NumPy簡介
Numpy提供了一個在Python中做科學計算的基礎庫,重在數值計算,主要用于處理多元數組(矩陣)的庫。用來存儲和處理大型矩陣,比Python自身的嵌套清單結構要高效的多。本身是由C語言開發,是個很基礎的擴充,Python其餘的科學計算擴充大部分都是以此為基礎。
高性能科學計算和資料分析的基礎包
ndarray,多元數組(矩陣),具有矢量運算能力,快速、節省空間
矩陣運算,無需循環,可完成類似Matlab中的矢量運算
線性代數、随機數生成
1、建立數組的3種方法
import random
import numpy as np
# numpy是幫助我們進行數值型計算的
a = np.array([1,2,3,4,5])
print(a) # [1 2 3 4 5]
print(type(a)) #
b = np.array(range(1,6))
print(b)
print(type(b))
c = np.arange(1,6)
print(c)
print(type(c))
# dtype:檢視數組中資料的類型
print(c.dtype) # int64,預設是根據電腦位數來的
# 指定生成的資料類型
d = np.array([1,1,0,1],dtype=bool)
print(d) # [ True True False True]
# numpy中的小數
e = np.array([random.random() for i in range(4)])
print(e) # [0.8908038 0.4591454 0.38334215 0.08534364]
print(type(e)) #
print(e.dtype) # float64
# 取資料的幾位小數
f = e.round(2) # 或者 f = np.round(e,2)
print(f) # [0.92 0.27 0.07 0.94]
2、數組的形狀
import numpy as np
# 數組的形狀
a = np.array([[1,3,4],[3,5,6]])
print(a)
"""
二維數組
[[1 3 4]
[3 5 6]]
"""
print(a.shape) # (2,3),代表着2行3列的數組
b = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
print(b)
"""
三維數組
[[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]]
"""
print(b.shape) # (2, 2, 3)
# 由于上面這種寫法(幾維數組)過于複雜
c = np.arange(12) # 生成一個一維數組
d = np.reshape(c,(3,4)) # 将1維數組轉變成3*4的二維數組
print(d)
"""
3*4的二維數組
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
e = np.arange(24)
f = e.reshape((2,3,4))
print(f)
"""
2*3*4的三維數組,其中2表示塊數,3行4列
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
"""
# 三種方式将3維數組f,轉成1維數組
g = f.reshape((24,)) # 一定要有, f.reshape((1,24))也行
h = f.reshape((f.shape[0]*f.shape[1]*f.shape[2],))
i = f.flatten()
print(g)
print(h)
print(i)
3、數組的計算
import numpy as np
# 數組的計算
a = np.array([i for i in range(12)])
b = a.reshape((3,4)) # 2維數組
print(b)
"""
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
print(b+2)
"""
numpy會将數組中的所有元素+2,+—*/同理,下面看一個特殊的
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
"""
# print(b/0)
"""
在numpy中,/0并不會報錯,其中nan(not a number)代表未定義或不可表示的值,inf(infimum)表示無窮
[[nan inf inf inf]
[inf inf inf inf]
[inf inf inf inf]]
"""
# 兩個相同結構的數組的+——*/
c = np.array([1,2,3,4])
d = np.array([5,6,7,8])
e = c.reshape((2,2))
f = d.reshape((2,2))
print(e+f)
"""
e:
[[1 2]
[3 4]]
f:
[[5 6
[7 8]]
e+f:
[[ 6 8]
[10 12]]
"""
# 因為行的次元兩個數組是相同的,是以會對每一行進行+——*/運算
# 多元中有一個(或以上)次元相同的話就可以進行計算
# 所有次元都不相同,無法進行計算
4、加載csv資料
"""
加載csv資料
"""
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
"""
fname:檔案路徑
delimiter:資料分隔符(預設為空格)
dtype:資料類型
skiprows:跳過多少行
usecols:選取指定的列(元組類型)
unpack:是否轉置
"""
aaa = np.loadtxt(fname=us_file_path,delimiter=",",dtype=int)
5、轉置操作
a = np.array([i for i in range(12)])
b = a.reshape((3,4))
print(b)
"""
轉置的3中方法
轉置:2維數組的行和列交換
"""
print(b.T)
print(b.transpose())
# 交換0軸和1軸
print(b.swapaxes(1,0))
6、取行/列
"""
取行/列
"""
# 取第3行
print(b[2])
# 取連續的多行(2~4行)
print(b[1:4])
# 取不連續的多行(1、3行)
print(b[[0,2]])
# 取第2列
print(b[:,1])
# 取連續的多列(1~3列)
print(b[:,0:3])
# 取不連續的多列(1,3列)
print(b[:,[0,2]])
# 取行列交叉的點(3行4列)
c = b[2,3]
print(c)
print(type(c))
#取多行和多列,取第3行到第五行,第2列到第4列的結果
#去的是行和列交叉點的位置
print(b[2:5,1:4])
#取多個不相鄰的點
#選出來的結果是(0,0) (2,1) (2,3)
print(b[[0,2,2],[0,1,3]])
7、布爾索引、三元運算、裁剪
"""
numpy中的布爾索引
"""
print(b)
"""
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
print(b>5)
"""
[[False False False False]
[False False True True]
[ True True True True]]
"""
# Demo:将數組中>5的值改成5
print(b[b>5]) # [ 6 7 8 9 10 11]
b[b>5] = 5
"""
numpy中的三元運算
"""
# b中小于4的==>0,大于等于4的==>10
c = np.where(b<4,0,10)
# 注意:不會修改b,而是有一個傳回值
print(c)
"""
numpy中的裁剪
"""
# 小于10的替換成10,大于18的替換成18
b.clip(10,18)
8、numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一個數字
什麼時候numpy中會出現nan:
當我們讀取本地的檔案為float的時候,如果有缺失,就會出現nan
當做了一個不合适的計算的時候(比如無窮大(inf)減去無窮大)
inf(-inf,inf):infinity,inf表示正無窮,-inf表示負無窮
什麼時候回出現inf包括(-inf,+inf)
比如一個數字除以0,(python中直接會報錯,numpy中是一個inf或者-inf)
注意點:
inf和nan都是float類型
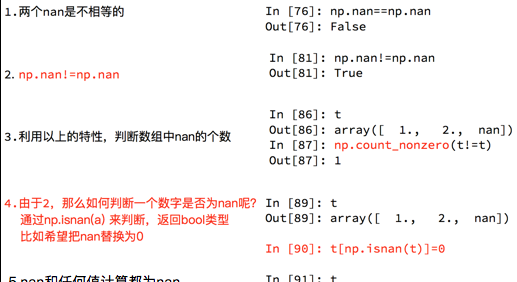
那麼問題來了,在一組資料中單純的把nan替換為0,合适麼?會帶來什麼樣的影響?
比如,全部替換為0後,替換之前的平均值如果大于0,替換之後的均值肯定會變小,是以更一般的方式是把缺失的數值替換為均值(中值)或者是直接删除有缺失值的一行
那麼問題來了:
如何計算一組資料的中值或者是均值
常用的統計函數
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受離群點的影響較大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
極值:np.ptp(t,axis=None) 即最大值和最小值隻差
标準差:t.std(axis=None)
預設傳回多元數組的全部的統計結果,如果指定axis則傳回一個目前軸上的結果
Demo:将數組中的nan替換成平均值
import numpy as np
def fill_ndarray(t1):
# 對每列進行操作
for i in range(t1.shape[1]):
# 擷取目前列
temp_col = t1[:,i]
# 判斷這列中有沒有nan
nan_number = np.count_nonzero(temp_col!=temp_col)
if nan_number > 0:
# 擷取目前列中不為nan的數組
temp_not_nan_col = temp_col[temp_col==temp_col]
# 找出nan,替換成平均值,或temp_col(np.isnan(temp_col)) = temp_not_nan_col.mean()
temp_col[temp_col!=temp_col] = temp_not_nan_col.mean()
return t1
if __name__ == '__main__':
t1 = np.arange(24).reshape((4, 6)).astype("float")
# 将第二行的3列以後指派為nan
t1[1, 2:] = np.nan
t2 = fill_ndarray(t1)
print(t2)
更多好用方法
擷取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1)
建立一個全0的數組: np.zeros((3,4))
建立一個全1的數組: np.ones((3,4))
建立一個對角線為1的正方形數組(方陣):np.eye(3)
numpy中的copy和view
a=b 完全不複制,a和b互相影響
a = b[:],視圖的操作,一種切片,會建立新的對象a,但是a的資料完全由b保管,他們兩個的資料變化是一緻的,
a = b.copy(),複制,a和b互不影響
生成随機數

軸
二維數組的軸:
三維數組的軸: