一。scrapy結構資料
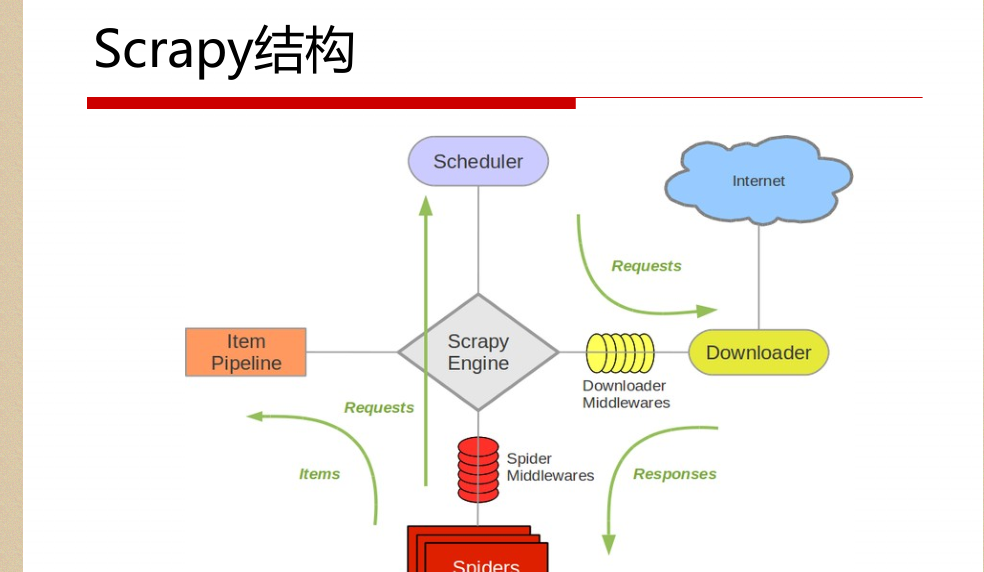
解釋:
1.名詞解析:
o 引擎(Scrapy Engine)
o 排程器(Scheduler)
o 下載下傳器(Downloader)
o 蜘蛛(Spiders)
o 項目管道(Item Pipeline)
o 下載下傳器中間件(Downloader Middlewares)
o 蜘蛛中間件(Spider Middlewares)
o 排程中間件(Scheduler Middlewares)
2.具體解析
綠線是資料流向
從初始URL開始,Scheduler會将其交給Downloader進
行下載下傳
下載下傳之後會交給Spider進行分析
Spider分析出來的結果有兩種
一種是需要進一步抓取的連結,如 “下一頁”的連結,它們
會被傳回Scheduler;另一種是需要儲存的資料,它們被送到Item Pipeline裡,進行
後期處理(詳細分析、過濾、存儲等)。
在資料流動的通道裡還可以安裝各種中間件,進行必
要的處理。
二。初始化爬蟲架構 Scrapy
指令: scrapy startproject qqnews

ps:真正的項目是在spiders裡面寫入的
三。scrapy元件spider
爬取流程
1. 先初始化請求URL清單,并指定下載下傳後處
理response的回調函數。
2. 在parse回調中解析response并傳回字典,Item
對象,Request對象或它們的疊代對象。
3 .在回調函數裡面,使用選擇器解析頁面内容
,并生成解析後的結果Item。
4. 最後傳回的這些Item通常會被持久化到資料庫
中(使用Item Pipeline)或者使用Feed exports将
其儲存到檔案中。
标準項目結構執行個體:
1.items結構:定義變量,根據不同種資料結構定義
2.spider結構中引入item裡面,并作填充item
3。pipline去清洗,驗證,存入資料庫,過濾等等 後續處理
Item Pipeline常用場景
清理HTML資料
驗證被抓取的資料(檢查item是否包含某些字段)
重複性檢查(然後丢棄)
将抓取的資料存儲到資料庫中
4.Scrapy元件Item Pipeline
經常會實作以下的方法:
open_spider(self, spider) 蜘蛛打開的時執行
close_spider(self, spider) 蜘蛛關閉時執行
from_crawler(cls, crawler) 可通路核心元件比如配置和
信号,并注冊鈎子函數到Scrapy中
pipeline真正處理邏輯
定義一個Python類,實作方法process_item(self, item,
spider)即可,傳回一個字典或Item,或者抛出DropItem
異常丢棄這個Item。
5.settings中定義哪種類型的pipeline
持續更新中。。。。,歡迎大家關注我的公衆号LHWorld.