Antlr(ANother Tool for Language Recognition)是一款優秀的語言識别工具,你隻需要使用擴充巴科斯範式(EBNF)定義好文法規則,Antlr就可以幫你完成詞法分析和文法分析的工作,然後自己再完成語義分析和運作時,就可以很輕易寫出一門簡單的腳本語言。 今天我們先不寫語言,而是隻用antlr完成一個比較簡單的功能——表達式計算。
得益于antlr的強大功能,我們自己僅需要寫20多行簡單代碼就能實作任意複雜度的四則運算表達求值。本次代碼我已全部放在github上,其中Expr.g4為文法規則定義檔案,MyExprVisitor.java為實作代碼,ExprMain.java為測試功能用的main方法,其餘均為antlr自動生成的java代碼。
我們先來看下Expr.g4所定義的文法規則,沒錯,即便是簡單的四則運算也是有規則的,其實就是我們國小三年級學到的四則運算計算優先級規則,括号内最優先,其次是乘除法,最後才是加減法。
grammar Expr;
@header {
package xyz.xindoo.ulang.expr;
}
expression
: primary
| expression bop=('*'|'/') expression
| expression bop=('+'|'-') expression
;
primary
: '(' expression ')'
| number
;
number
: Digits
| Digits '.' Digits
;
Digits
: [0-9] ([0-9]*)?
; 上面文法就是四則運算的巴科斯範式定義(EBNF),可能對初學者有點難了解,其實就是一個遞歸定義,一個表達式可能是有多個子表達式構成,但子表達式的盡頭一定是數字。 antlr可以用EBNF所定義的規則,将某個輸入串解析為一顆抽象文法樹(AST)。我們以表達式
((3+3)*(1+4))/(5-3)
為例,它的抽象文法樹如下:
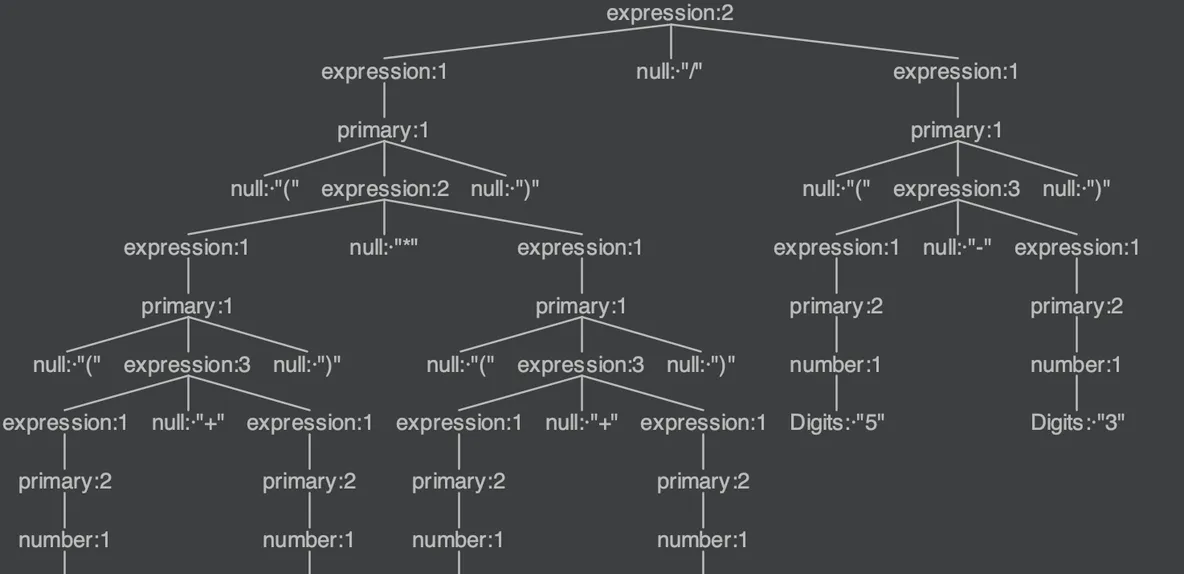
如果你仔細看上面這棵樹,就會發現
((3+3)*(1+4))/(5-3)
的結果就是這顆樹後序周遊的結果。 優先級在哪展現呢? 有沒有發現,優先級越高的子表達式,其在AST中的深度越深,它也就被越先計算,上圖太複雜可能看不出來,我們以
1+2*3
為例,如下圖:

在antlr中,文法的優先級展現在其次序中,規則排的越靠前,其優先級越高。
說完了文法規則,我們來說下具體如何求值。上文已經說過了,對AST後序周遊就可以得到其結果。antlr可以中已經實作了文法樹的周遊,而你隻需要使用antlr的指令
antlr4 -visitor Expr
,生成代碼後自己實作其中每個類型節點的周遊方法即可,這裡我使用了visitor模式,自己隻需要重寫ExprBaseVisitor類即可,重寫後如下:
package xyz.xindoo.ulang.expr;
public class MyExprVisitor extends ExprBaseVisitor<Double> {
@Override
public Double visitExpression(ExprParser.ExpressionContext ctx) {
if (null == ctx.bop) {
return visitChildren(ctx);
}
switch (ctx.bop.getText()) {
case "+": return visit(ctx.children.get(0)) + visit(ctx.children.get(2));
case "-": return visit(ctx.children.get(0)) - visit(ctx.children.get(2));
case "*": return visit(ctx.children.get(0)) * visit(ctx.children.get(2));
case "/": return visit(ctx.children.get(0)) / visit(ctx.children.get(2));
}
return 0.0;
}
@Override
public Double visitPrimary(ExprParser.PrimaryContext ctx) {
if (ctx.children.size() == 3) {
return visit(ctx.children.get(1));
}
return visitChildren(ctx);
}
@Override
public Double visitNumber(ExprParser.NumberContext ctx) {
return Double.parseDouble(ctx.Digits().get(0).getText());
}
} 沒錯,就這麼簡單,隻實作每種類型節點的周遊方法就行了,接下來就是寫個main方法來測試下功能是否正常。
public class ExprMain {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String expr = scanner.nextLine();
ExprLexer lexer = new ExprLexer(CharStreams.fromString(expr));
CommonTokenStream tokens = new CommonTokenStream(lexer);
ExprParser parser = new ExprParser(tokens);
ExprParser.ExpressionContext expressionContext = parser.expression();
MyExprVisitor visitor = new MyExprVisitor();
Double res = visitor.visitExpression(expressionContext);
System.out.println("=" + res);
}
}
} 跑幾個樣例測試下,結果全部正确。