是什麼?
Elasticsearch是一個基于Apache Lucene(TM)的開源搜尋引擎。無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、性能最好的、功能最全的搜尋引擎庫。
Elasticsearch不僅僅是Lucene和全文搜尋,我們還能這樣去描述它:
- 分布式的實時檔案存儲,每個字段都被索引并可被搜尋
- 分布式的實時分析搜尋引擎
- 可以擴充到上百台伺服器,處理PB級結構化或非結構化資料
面向文檔
應用中的對象很少隻是簡單的鍵值清單,更多時候它擁有複雜的資料結構,比如包含日期、地理位置、另一個對象或者數組。
總有一天你會想到把這些對象存儲到資料庫中。将這些資料儲存到由行和列組成的關系資料庫中,就好像是把一個豐富,資訊表現力強的對象拆散了放入一個非常大的表格中:你不得不拆散對象以适應表模式(通常一清單示一個字段),然後又不得不在查詢的時候重建它們。
Elasticsearch是面向文檔(document oriented)的,這意味着它可以存儲整個對象或文檔(document)。然而它不僅僅是存儲,還會索引(index)每個文檔的内容使之可以被搜尋。在Elasticsearch中,你可以對文檔(而非成行成列的資料)進行索引、搜尋、排序、過濾。這種了解資料的方式與以往完全不同,這也是Elasticsearch能夠執行複雜的全文搜尋的原因之一。
使用案例:
- 維基百科使用Elasticsearch來進行全文搜做并高亮顯示關鍵詞,以及提供search-as-you-type、did-you-mean等搜尋建議功能。
- 英國衛報使用Elasticsearch來處理訪客日志,以便能将公衆對不同文章的反應實時地回報給各位編輯。
- StackOverflow将全文搜尋與地理位置和相關資訊進行結合,以提供more-like-this相關問題的展現。
- GitHub使用Elasticsearch來檢索超過1300億行代碼。
- 每天,Goldman Sachs使用它來處理5TB資料的索引,還有很多投行使用它來分析股票市場的變動。
但是Elasticsearch并不隻是面向大型企業的,它還幫助了很多類似DataDog以及Klout的創業公司進行了功能的擴充。
Elasticsearch 與 Solr 的比較總結
- 二者安裝都很簡單;
- Solr 利用 Zookeeper 進行分布式管理,而 Elasticsearch 自身帶有分布式協調管理功能;
- Solr 支援更多格式的資料,而 Elasticsearch 僅支援json檔案格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,進階功能多有第三方插件提供;
- Solr 在傳統的搜尋應用中表現好于 Elasticsearch,但在處理實時搜尋應用時效率明顯低于 Elasticsearch。
Solr 是傳統搜尋應用的有力解決方案,但 Elasticsearch 更适用于新興的實時搜尋應用。
index、type
在Elasticsearch中,文檔歸屬于一種類型(type),而這些類型存在于索引(index)中,我們可以畫一些簡單的對比圖來類比傳統關系型資料庫:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
Elasticsearch叢集可以包含多個索引(indices)(資料庫),每一個索引可以包含多個類型(types)(表),每一個類型包含多個文檔(documents)(行),然後每個文檔包含多個字段(Fields)(列)。
什麼是mapping
ES的mapping非常類似于靜态語言中的資料類型:聲明一個變量為int類型的變量, 以後這個變量都隻能存儲int類型的資料。同樣的, 一個number類型的mapping字段隻能存儲number類型的資料。
同語言的資料類型相比,mapping還有一些其他的含義,mapping不僅告訴ES一個field中是什麼類型的值, 它還告訴ES如何索引資料以及資料是否能被搜尋到。
當你的查詢沒有傳回相應的資料, 你的mapping很有可能有問題。當你拿不準的時候, 直接檢查你的mapping。
剖析mapping
一個mapping由一個或多個analyzer組成, 一個analyzer又由一個或多個filter組成的。當ES索引文檔的時候,它把字段中的内容傳遞給相應的analyzer,analyzer再傳遞給各自的filters。
filter的功能很容易了解:一個filter就是一個轉換資料的方法, 輸入一個字元串,這個方法傳回另一個字元串,比如一個将字元串轉為小寫的方法就是一個filter很好的例子。
一個analyzer由一組順序排列的filter組成,執行分析的過程就是按順序一個filter一個filter依次調用, ES存儲和索引最後得到的結果。
總結來說, mapping的作用就是執行一系列的指令将輸入的資料轉成可搜尋的索引項。
預設analyzer
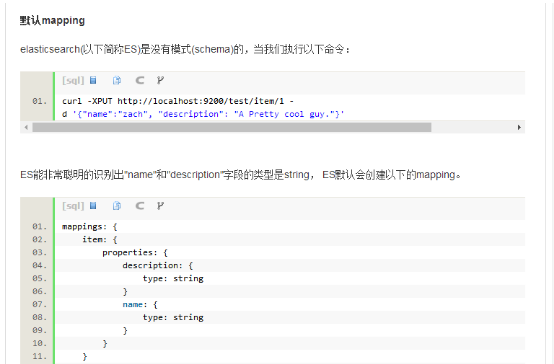
回到我們的例子, ES猜測description字段是string類型,于是預設建立一個string類型的mapping,它使用預設的全局analyzer, 預設的analyzer是标準analyzer。
我們可以在做查詢的時候鍵入_analyze關鍵字檢視分析的過程。使用以下指令檢視description字段的轉換過程:

可以看到, 我們的description字段的值轉換成了[pretty], [cool], [guy], 在轉換過程中大寫的A, 标點符号都被filter過濾掉了, Pretty也轉成了全小寫的pretty,
這裡比較重要的是, 即使ES存儲資料的時候仍然存儲的是完整的資料, 但是可以搜尋到這條資料的關鍵字隻剩下這三個單詞了, 其他的都是抛棄掉了。
現在就能得到正确的結果,這是一個公認的簡單例子, 但是它描述了ES是如何工作的, 不要把mapping想成是資料類型, 把它想象成是搜尋資料的指令集合。如果你不想字元"a"被删除, 你需要修改你的analyzer。
mapping配置
可以修改的項:
- 增加新的類型定義
- 增加新的字段
- 增加新的分析器
不允許修改的項:
- 更改字段類型(比如文本改為數字)
- 更改存儲為不存儲,反之亦然
- 更改索引屬性的值
- 更改已索引文檔的分析器
注意的是新增字段或更改分析器之後,需要再次對所有文檔進行索引重建
字段的資料類型
簡單類型
- string(指定分詞器)
- date(預設使用UTC保持,也可以使用format指定格式)
- 數值類型(byte,short,integer,long,float,double)
- boolean
- binary(存儲在索引中的二進制資料的base64表示,比如圖像,隻存儲不索引)
- ip(以數字形式簡化IPV4位址的使用,可以被索引、排序并使用IP值做範圍查詢).
有層級結構的類型
比如object 或者 nested.
特殊類型
比如geo_point, geo_shape, or completion.
動态模闆:
使用dynamic_templates可以完全控制新字段的映射,你設定可以通過字段名或資料類型應用一個完全不同的映射。
例子:我們為/my_index/my_type 分别建立
es:字段名以_es結尾的且是string類型的,需要使用spanish分詞器
enn:其他字段的且是string類型的,需要使用english分詞器
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic_templates": [
{
"es": {
=>模闆名稱,随意,一般要有語義"match": "*_es",
=>比對字段名稱"match_mapping_type": "string"=>比對字段類型"mapping": {
=>當比對到之後,該字段的具體設定"type": "string",
"anaylzer": "spanish"
}
}
},
{
"en": {
=>模闆名稱,随意,一般要有語義"match": "*",
=>比對字段名稱(任意,通用的順序要在之後)"match_mapping_type": "string"=>比對字段類型"mapping": {
=>當比對到之後,該字段的具體設定"type": "string",
"anaylzer": "english"
}
}
}
]
}
}
} index别名設定
一個别名能夠指向多個索引,是以當我們将别名指向新的索引時,我們還需要删除别名原來到舊索引的指向。這個改變需要是原子的,即意味着我們需要使用_aliases端點:
POST /_aliases { "actions": [ { "remove": { "index": "my_index_v1", "alias": "my_index" }}, { "add": { "index": "my_index_v2", "alias": "my_index" }} ] }
現在你的應用就在零停機時間的前提下,實作了舊索引到新索引的透明切換。
問題:
1、全文索引(json全文爬資料)
2、聚合無法根據比對度排序
3、聚合無法真分頁
一個mapping示例
{
"dynamic": "false",
"dynamic_templates": [
{
"indexes": {
"mapping": {
"type": "string",
"fields": {
"raw": {
"index": "not_analyzed",
"null_value": "",
"type": "string"
}
}
},
"match_mapping_type": "string",
"path_match": "indexes.*"
}
}
],
"properties": {
"indexes": {
"dynamic": "strict",
"properties": {
"application": {
"type": "string",
"index": "not_analyzed"
},
"attribute_name": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"null_value": ""
}
}
},
"category": {
"type": "string",
"index": "not_analyzed"
},
"create_time": {
"type": "long"
},
"data_md5": {
"type": "string",
"index": "not_analyzed"
},
"disable": {
"type": "boolean"
},
"keyword": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"null_value": ""
}
}
},
"project_code": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"null_value": ""
}
}
},
"project_id": {
"type": "string",
"index": "not_analyzed"
},
"project_title": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"null_value": ""
}
}
},
"project_type": {
"type": "string",
"index": "not_analyzed",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"null_value": ""
}
}
},
"reference_count": {
"type": "long"
},
"tenant": {
"type": "long"
},
"top_reference_count": {
"type": "long"
},
"type": {
"type": "long"
},
"update_time": {
"type": "long"
},
"user_id": {
"type": "long"
},
"user_name": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"null_value": ""
}
}
}
}
},
"tenant": {
"type": "long"
}
}
} ElasticSearch 基本查詢文法
基本搜尋
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
]
}
},
"from": 0,
"size": 1
}
Group BY
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
]
}
},
"from": 0,
"size": 0,
"aggregations": {
"mid": {
"aggregations": {
"terminal": {
"terms": {
"field": "terminal",
"size": 0
}
}
},
"terms": {
"field": "mid",
"size": "1"
}
}
}
}
Distinct Count
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
]
}
},
"from": 0,
"size": 0,
"aggregations": {
"COUNT(distinct (mid))": {
"cardinality": {
"field": "(mid)"
}
}
}
}
全文搜尋
{
"query" : {
"query_string" : {"query" : "name:rcx"}
}
}
match查詢
{
"query": {
"match": {
"title": "crime and punishment"
}
}
}
通配符查詢
{
"query": {
"wildcard": {
"title": "cr?me"
}
}
}
範圍查詢
{
"query": {
"range": {
"year": {
"gte" :1890,
"lte":1900
}
}
}
}
正規表達式查詢
{
"query": {
"regexp": {
"title": {
"value" :"cr.m[ae]",
"boost":10.0
}
}
}
}
布爾查詢
{
"query": {
"bool": {
"must": {
"term": {
"title": "crime"
}
},
"should": {
"range": {
"year": {
"from": 1900,
"to": 2000
}
}
},
"must_not": {
"term": {
"otitle": "nothing"
}
}
}
}
}
轉載于:https://www.cnblogs.com/wihainan/p/7064943.html