作者:Peter
整理:Lemon
桑基圖繪制實踐
本文中介紹的是如何制作桑基圖,使用的可視化庫是強大的
Pyecharts
(版本1.7.1,版本一緻很重要)。文章将從如下幾個方面進行介紹:
- 什麼是桑基圖
- 官網的兩個
demo
- 桑基圖繪制項目實戰
在開始之前,我們先來看看通過本文制作的最終效果圖:
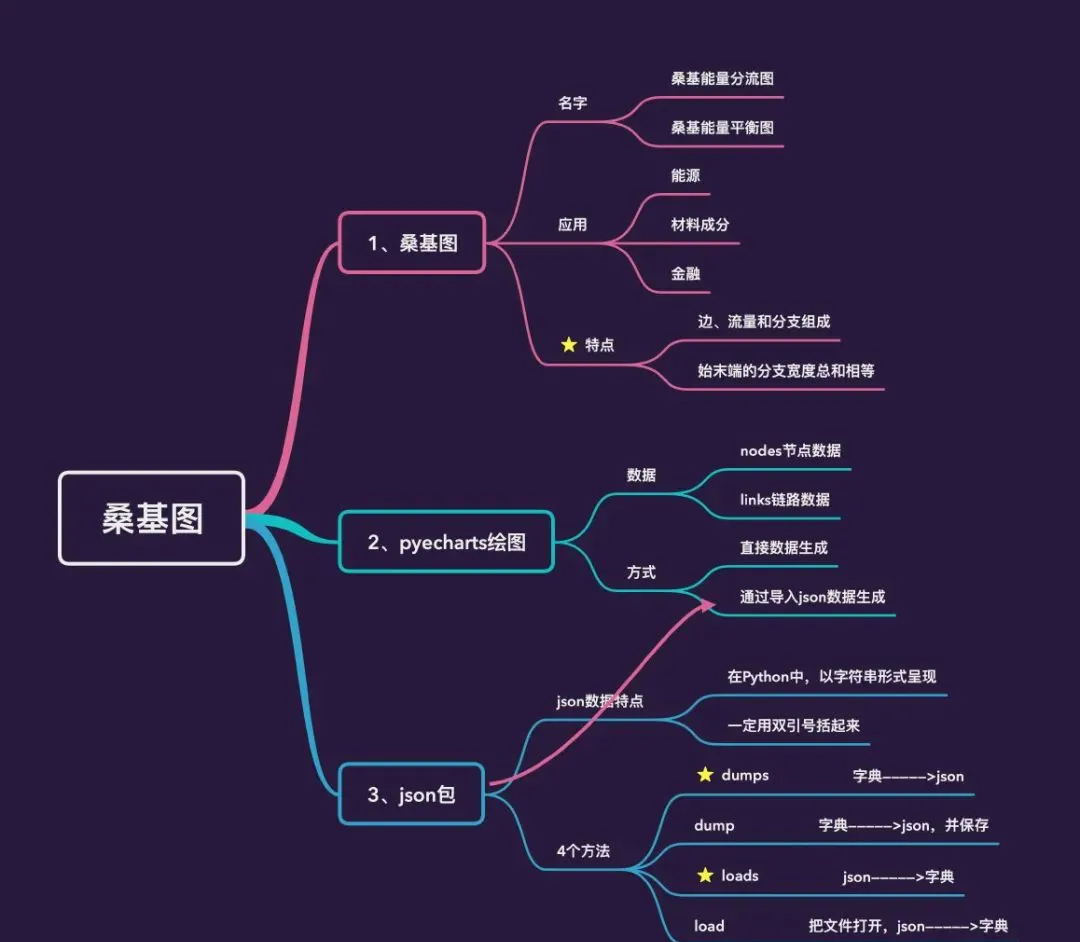
什麼是桑基圖?
桑基圖(桑葚圖),也叫桑基能量分流圖或者桑基能量平衡圖,裡面的桑基其實是一個人名,全名是
馬修·亨利·菲尼亞斯·裡爾·桑基(Matthew Henry Phineas Riall Sankey)
,是一名愛爾蘭裔工程師,也是英國皇家陸軍工兵的上尉[1]。

早在 1898 年的時候,他就使用這種圖形來表示蒸汽機的能源效率:
桑基之後,桑基圖逐漸成為科學和工程領域,代表平衡、能量流、物質流的标準模型,在一些産品的生命周期評估中也常被使用,通常應用于能源、材料成分、金融等資料的可視化分析。主要特點是:
- 圖形由邊、流量和支點組成。邊代表了流動的資料,流量代表了流動資料的具體數值,節點代表了不同分類
- 始末端的分支寬度總和相等,即所有主支寬度的總和應與所有分出去的分支寬度的總和相等,保持能量的平衡。
官網demo
本文中使用的
Pyecharts
版本是
1.7.1
,版本的一緻非常重要。
import pyecharts
pyecharts.__version__ demo_1
首先我們看看官網的第一個
demo
:
from pyecharts import options as opts
from pyecharts.charts import Sankey
nodes = [ # 所有節點名稱
{"name": "category1"},
{"name": "category2"},
{"name": "category3"},
{"name": "category4"},
{"name": "category5"},
{"name": "category6"},
]
links = [ # 每一條鍊路的資料,包含:父節點source + 子節點target + 資料值value
{"source": "category1", "target": "category2", "value": 10},
{"source": "category2", "target": "category3", "value": 15},
{"source": "category3", "target": "category4", "value": 20},
{"source": "category5", "target": "category6", "value": 25},
]
c = (
Sankey()
.add(
"sankey",
nodes,
links,
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="Sankey-基本示例"))
# .render("sankey_base.html") 生成HTML檔案
)
c.render_notebook() # jupyter notebook中線上顯示 在上面的代碼中,
nodes
部分表示的是所有的節點名稱,不管是父節點還是最小的子節點都要列出來;
links
部分表示的是每條鍊路的資料,包含:父節點source + 子節點target + 資料值value。根據links的資料,我們可以發現:
category1——-category2———category3———category4
構成了一條完整的鍊路,
category5—category6
構成了另一條鍊路。
下面是最終的圖形:
demo_2
接下來我們看看官網的第二個
demo
:
import json
from pyecharts import options as opts
from pyecharts.charts import Sankey
with open("product.json", "r", encoding="utf-8") as f: # 導入json資料
j = json.load(f) # json資料轉成字典資料
c = (
Sankey()
.add(
"sankey",
nodes=j["nodes"], # 取出json資料的節點和鍊路資料
links=j["links"],
pos_top="10%",
focus_node_adjacency=True,
levels=[
opts.SankeyLevelsOpts(
depth=0,
itemstyle_opts=opts.ItemStyleOpts(color="#fbb4ae"),
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
opts.SankeyLevelsOpts(
depth=1,
itemstyle_opts=opts.ItemStyleOpts(color="#b3cde3"),
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
opts.SankeyLevelsOpts(
depth=2,
itemstyle_opts=opts.ItemStyleOpts(color="#ccebc5"),
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
opts.SankeyLevelsOpts(
depth=3,
itemstyle_opts=opts.ItemStyleOpts(color="#decbe4"),
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
],
linestyle_opt=opts.LineStyleOpts(curve=0.5),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Sankey-Level Settings"),
tooltip_opts=opts.TooltipOpts(trigger="item", trigger_on="mousemove"),
)
# .render("sankey_with_level_setting.html")
)
c.render_notebook() # 線上顯示 - 讀取本地的
json
josn.load()
Python
- 取出
json
桑基圖繪制實踐
原始資料整理
通過上面官網的例子我們明白了繪制桑基圖需要的兩個資料:節點資料+鍊路資料,下面????通過一個實際的案例來講解如何生成繪制桑基圖需要的資料
認識原始資料
Peter同學一個人在深圳搬磚,辛辛苦苦地搬了一個月,産生很多的開銷????,這些開支主要分成5大塊:
- 住宿
- 餐飲
- 交通
- 服裝
- 紅包
每個部分又分别有不同的去向,是以這些資料就自然構成了一條條的鍊路,比如:
總費用—住宿—房租(2000)
,
總費用—交通—滴滴(220)
等,我們隻考慮兩個節點之間的關系
分層級整理資料
1、接下來我們分不同的層級來整理原始資料,首先是第一層:總費用到5個子版塊。算出每個子版塊的總和
2、整理5個子版塊的資料
3、我們将上面兩個步驟得到的資料放入一個
sheet
中,命名為
開支
:
桑基圖資料生成
讀取資料
首先我們将上面制作好的開支這份資料讀到pandas中:
import pandas as pd
import numpy as np
import json
# 等價于:data = pd.read_excel("life.xlsx",sheet_name=1) 1表示sheet_name的索引位置,索引從0開始
df = pd.read_excel("life.xlsx",sheet_name="開支") # 直接寫名字
df.head() 注意兩點:
- 當一個表格中存在多個
sheet
sheet_name
- 指定
sheet_name
- 直接指定名字
- 指定該
sheet_name
确定全部節點nodes
1、先找出全部的節點
所有的節點資料就是上面的父類和子類中去重後的元素,我們使用集合
set
進行去重,再轉成清單
# 父類+子類中的資料,需要去重
df['父類'].tolist()
df['子類'].tolist() 将上面的資料相加并且去重:
# 将兩個清單相加,在轉成集合set進行元素去重,再轉成清單
nodes = list(set(df['父類'].tolist() + df['子類'].tolist()))
nodes 2、生成節點資料
# 節點清單資料: nodes_list
nodes_list = []
for i in nodes:
dic = {}
dic["name"] = i
nodes_list.append(dic)
nodes_list 生成鍊路資料
我們将導入的資料生成鍊路資料:每一行記錄都是一個鍊路資料:
links_list = []
for i in range(len(df)):
dic = {}
dic['source'] = df.iloc[i,0] # 父類
dic['target'] = df.iloc[i,1] # 子類
dic['value'] = int(df.iloc[i,2]) # 資料值 : 使用int函數直接強制轉換,防止json.dump()報錯
links_list.append(dic) Attention⚠️:導入的資料部分需要強制轉換成
int
類型,防止後面的資料處理報錯。
到此為止,我們已經完成了桑葚圖中節點資料和鍊路資料的生成,下面開始繪圖。
繪制桑基圖
我們通過官網的2種不同方式來繪制桑基圖
方式1
這種方式比較簡單:直接将上面得到的
nodes_list
和
links_list
整體放入繪圖的代碼中:
# 需要事先導入,否則jupyter notebook中可能不會出圖
from pyecharts.globals import CurrentConfig, OnlineHostType
from pyecharts import options as opts # 圖形設定
from pyecharts.charts import Sankey # 導入桑基圖型的類
nodes_list = [
{'name': '圍巾'},
{'name': '長輩'},
{'name': '網絡費'},
{'name': '服裝'},
{'name': '公交'},
{'name': '同學'},
{'name': '襪子'},
{'name': '總費用'},
{'name': '衣服'},
{'name': '紅包'},
{'name': '交通'},
{'name': '聚餐'},
{'name': '滴滴'},
{'name': '餐飲'},
{'name': '管理費'},
{'name': '水電'},
{'name': '共享單車'},
{'name': '外賣'},
{'name': '房租'},
{'name': '住宿'},
{'name': '飲料'},
{'name': '鞋子'},
{'name': '地鐵'}
]
links_list = [
{'source': '總費用', 'target': '住宿', 'value': 2580},
{'source': '總費用', 'target': '餐飲', 'value': 1300},
{'source': '總費用', 'target': '交通', 'value': 500},
{'source': '總費用', 'target': '服裝', 'value': 900},
{'source': '總費用', 'target': '紅包', 'value': 1300},
{'source': '住宿', 'target': '房租', 'value': 2000},
{'source': '住宿', 'target': '水電', 'value': 400},
{'source': '住宿', 'target': '管理費', 'value': 100},
{'source': '住宿', 'target': '網絡費', 'value': 80},
{'source': '餐飲', 'target': '外賣', 'value': 800},
{'source': '餐飲', 'target': '聚餐', 'value': 300},
{'source': '餐飲', 'target': '飲料', 'value': 200},
{'source': '交通', 'target': '滴滴', 'value': 220},
{'source': '交通', 'target': '地鐵', 'value': 150},
{'source': '交通', 'target': '公交', 'value': 80},
{'source': '交通', 'target': '共享單車', 'value': 50},
{'source': '服裝', 'target': '衣服', 'value': 400},
{'source': '服裝', 'target': '鞋子', 'value': 300},
{'source': '服裝', 'target': '圍巾', 'value': 150},
{'source': '服裝', 'target': '襪子', 'value': 50},
{'source': '紅包', 'target': '同學', 'value': 800},
{'source': '紅包', 'target': '長輩', 'value': 500}
]
c = (
Sankey()
.add(
"月度開支",
nodes_list,
links_list,
linestyle_opt=opts.LineStyleOpts(opacity=0.5, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="月度開支桑葚圖"))
)
c.render_notebook() 得到的桑基圖在
notebook
中是動态的圖形:
動态視訊效果如下:
方式2
如果資料比較少,将
nodes_list
和
links_list
放入繪圖的代碼中不會占據過多的空間;但是如果資料量大,不同鍊路種類多,全部放在整個繪圖代碼中,就會顯得整個代碼很臃腫。
于是産生了方式2:先将上面得到的
nodes_list
和
links_list
生成一個
json
檔案,再将
json
檔案通過
with
方法讀進來進行繪圖。下面講解如何通過得到的
nodes_list
和
links_list
資料生成我們繪圖需要的
json
資料。
json
格式的資料,在
python
中以字元串的形式呈現,一定要用雙引号括起來。
json
子產品中提供的
4
個功能:
-
dumps
python
-
dump
-
loads
json
-
load
1、先生成字典資料
data_dic = {}
data_dic["nodes"] = nodes_list
data_dic["links"] = links_list 得到的字典
data_dic
資料分為節點資料和鍊路資料,具體如下:
{'nodes': [{'name': '圍巾'}, # 節點部分資料
{'name': '長輩'},
{'name': '網絡費'},
{'name': '服裝'},
{'name': '公交'},
{'name': '同學'},
{'name': '襪子'},
{'name': '總費用'},
{'name': '衣服'},
{'name': '紅包'},
{'name': '交通'},
{'name': '聚餐'},
{'name': '滴滴'},
{'name': '餐飲'},
{'name': '管理費'},
{'name': '水電'},
{'name': '共享單車'},
{'name': '外賣'},
{'name': '房租'},
{'name': '住宿'},
{'name': '飲料'},
{'name': '鞋子'},
{'name': '地鐵'}],
'links': [{'source': '總費用', 'target': '住宿', 'value': 2580}, # 鍊路部分資料
{'source': '總費用', 'target': '餐飲', 'value': 1300},
{'source': '總費用', 'target': '交通', 'value': 500},
{'source': '總費用', 'target': '服裝', 'value': 900},
{'source': '總費用', 'target': '紅包', 'value': 1300},
{'source': '住宿', 'target': '房租', 'value': 2000},
{'source': '住宿', 'target': '水電', 'value': 400},
{'source': '住宿', 'target': '管理費', 'value': 100},
{'source': '住宿', 'target': '網絡費', 'value': 80},
{'source': '餐飲', 'target': '外賣', 'value': 800},
{'source': '餐飲', 'target': '聚餐', 'value': 300},
{'source': '餐飲', 'target': '飲料', 'value': 200},
{'source': '交通', 'target': '滴滴', 'value': 220},
{'source': '交通', 'target': '地鐵', 'value': 150},
{'source': '交通', 'target': '公交', 'value': 80},
{'source': '交通', 'target': '共享單車', 'value': 50},
{'source': '服裝', 'target': '衣服', 'value': 400},
{'source': '服裝', 'target': '鞋子', 'value': 300},
{'source': '服裝', 'target': '圍巾', 'value': 150},
{'source': '服裝', 'target': '襪子', 'value': 50},
{'source': '紅包', 'target': '同學', 'value': 800},
{'source': '紅包', 'target': '長輩', 'value': 500}]} 2、将生成的字典資料轉成
json
資料,并儲存到本地
通過
json.dump
方法将上面生成的字典類型資料轉成
json
資料,并儲存到本地:
with open("sankey.json","w",encoding="utf-8") as f: # 資料儲存到了本地
# json.dump(data_dic, f) 寫入一行資料
json.dump(data_dic, f, indent=2, sort_keys=True, ensure_ascii=False) # 寫入多行資料 3、讀取
json
資料進行繪圖
import json
from pyecharts import options as opts
from pyecharts.charts import Sankey
with open("sankey.json", "r", encoding="utf-8") as f: # 1、打開儲存的檔案
j = json.load(f) # 2、json字元串轉成字典類型資料
c = (
Sankey()
.add(
"月度開支",
nodes=j["nodes"], # 3、通過鍵值對的映射關系來讀取資料
links=j["links"],
pos_top="20%",
focus_node_adjacency=True,
levels=[
opts.SankeyLevelsOpts(
depth=0,
# itemstyle_opts=opts.ItemStyleOpts(color="#fbb4ae"), 4、屬性的設定部分
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
opts.SankeyLevelsOpts(
depth=1,
# itemstyle_opts=opts.ItemStyleOpts(color="#b3cde3"),
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
opts.SankeyLevelsOpts(
depth=2,
# itemstyle_opts=opts.ItemStyleOpts(color="#ccebc5"),
linestyle_opts=opts.LineStyleOpts(color="source", opacity=0.6),
),
],
linestyle_opt=opts.LineStyleOpts(curve=0.5,color="source",opacity=0.6,type_="dotted"),
label_opts=opts.LabelOpts(position="right")
)
.set_global_opts(
title_opts=opts.TitleOpts(title="月度開支桑葚圖"),
tooltip_opts=opts.TooltipOpts(trigger="item", trigger_on="mousemove|click",is_show=True),
)
)
c.render_notebook() 看看實際的動态化效果:
參考資料
[1]
桑基的介紹: https://zhuanlan.zhihu.com/p/127360262
作者簡介