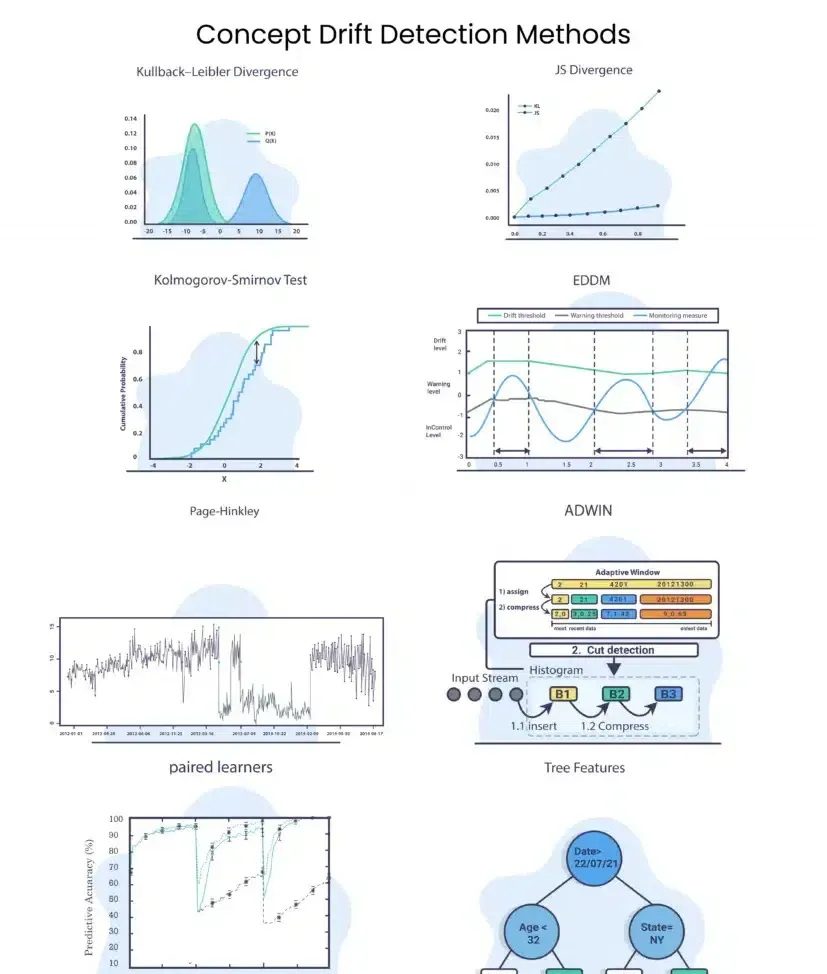
目前,有多種技術可用于機器學習檢測概念漂移的方法。熟悉這些檢測方法是為每個漂移和模型使用正确度量的關鍵。
在本文章中,回顧了四種類型的檢測方法:統計、統計過程控制、基于時間視窗和上下文方法。
如果您正在尋找有關概念漂移的介紹,我建議您檢視機器學習中的概念漂移一文。
統計方法
統計方法用于比較分布之間的差異。
在某些情況下,會使用散度,這是分布之間的一種距離度量。 在其他情況下,運作測試以獲得分數。
Kullback-Leibler 散度
Kullback-Leibler 散度有時被稱為相對熵。
KL散度試圖量化一個機率分布與另一個機率分布有多大不同,是以,如果我們有分布Q和P,其中,Q分布是舊資料的分布,P是我們想要計算的新資料的分布:
其中,“||”代表散度。
我們可以看到,
- 如果 P(x) 高而 Q(x) 低,則散度将很高。
- 如果 P(x) 低而 Q(x) 高,則散度也會很高,但不會那麼大。
- 如果 P(x) 和 Q(x) 相似,則散度就會很低。

JS 散度
Jensen-Shannon 散度使用 KL 散度
其中,
JS散度和KL散度的主要差別在于JS是對稱的,它總是有一個有限值。
Kolmogorov-Smirnov 檢驗 (K-S 檢驗)
兩樣本 KS 檢驗是比較兩個樣本的有用且通用的非參數方法。 在 KS 測試中,我們計算:
其中, 是先前資料與 樣本的經驗分布函數, 是新資料與 樣本和的經驗分布函數, 是使 最大化的樣本
KS 檢驗對兩個樣本的經驗累積分布函數的位置和形狀的差異很敏感。它非常适合數值資料。
何時使用統計方法
統計方法部分的想法是評估兩個資料集之間的分布。
我們可以使用這些工具來查找不同時間範圍内的資料之間的差異,并衡量随着時間的推移資料行為的差異。
對于這些方法,不需要标簽,也不需要額外的記憶體,我們可以快速獲得模型輸入特征/輸出變化的名額。 這将幫助我們甚至在模型的性能名額出現任何潛在下降之前就開始調查這種情況。 另一方面,如果沒有正确處理,缺少标簽和忽視對過去事件和其他特征的記憶可能會導緻誤報。
統計過程控制
統計過程控制的想法是驗證我們模型的誤差是否在可控範圍内。 這在生産中運作時尤其重要,因為性能會随着時間而變化。是以,我們希望有一個系統,如果模型達到了一定錯誤率,就會發送警報。請注意,某些模型具有“紅綠燈”系統,其中也有警告報警。
漂移檢測方法/早期漂移檢測方法 (DDM/EDDM)
這個想法是将誤差模組化為二項式變量。 這意味着我們可以計算出我們的預期誤內插補點。 當我們使用二項式分布時,我們可以标記 ,是以, 。
DDM
在這裡我們可以提出:
- 當
- 當
優點:DDM 在檢測逐漸變化(如果它們不是很慢)和突然變化(增量和突然漂移)時表現出良好的性能。
缺點:當變化緩慢時,DDM 難以檢測漂移。許多樣本可能在漂移水準激活之前儲存了很長時間,存在樣本儲存溢出的風險。
EDDM
在這裡,通過測量 2 個連續錯誤的距離,我們可以提出:
- 當
- 當
EDDM 方法是 DDM 的修改版本,其重點是識别逐漸漂移。
CUMSUM 和 Page-Hinckley (PH)
CUSUM 及其變體 Page-Hinckley (PH) 是社群中的開拓方法之一。 該方法的想法是提供一種序列分析技術,該技術通常用于監測高斯信号平均值的變化檢測。
CUSUM 和 Page-Hinckley (PH) 通過計算觀測值與平均值的差異來檢測概念漂移,并在該值大于使用者定義的門檻值時設定漂移警報。 這些算法對參數值很敏感,導緻在誤報和檢測真實漂移之間進行權衡。
由于 CUMSUM 和 Page-Hinckley (PH) 用于處理資料流,是以每個事件都用于計算下一個結果:
CUMSUM:
- 當發出警報,并設定
注意:CUMSUM 是無記憶的、單邊的或不對稱的,是以它隻能檢測到值的增加。
Page-Hinckley (PH) :
- 當發出警報,并設定。
何時使用統計過程控制方法
要使用所介紹的統計過程控制方法,我們需要提供樣本的标簽。 在許多情況下,這可能是一個挑戰,因為延遲可能很高,并且很難提取它,尤其是在大型組織中使用它時。 另一方面,一旦獲得這些資料,我們就會得到一個相對快速的系統來涵蓋 3 種漂移類型:突然漂移、漸進漂移和增量漂移。
該系統還允許我們與部門一起跟蹤退化情況(如果有的話),以發出警告和警報。
時間視窗分布
時間視窗分布模型關注時間戳和事件的發生。
ADWIN
ADWIN 的思想是從時間視窗 開始,在上下文沒有明顯變化時動态增大視窗 ,并在檢測到變化時将其縮小。 該算法試圖找到顯示不同平均值的 和 的兩個子視窗。 這意味着視窗的舊部分
Paired Learners
假設對于給定的問題,我們有一個使用大量資料進行訓練的大型穩定模型,讓我們将其标記為模型 A。
我們還将設計另一個模型,一個更輕量級的模型,在更小和更新的資料上進行訓練(它可以具有相同的類型)。 我們将其稱為模型 B。
想法:找到模型 B 優于模型 A 的時間視窗。由于模型 A 比模型 B 穩定并且封裝了更多資料,我們預計它會勝過它。 但是,如果模型 B 優于模型 A,則可能表明發生了概念漂移。
上下文方法(Contextual Approaches)
這些方法的想法是評估訓練集和測試集之間的差異。 當差異顯著時,可能表明資料存在漂移。
樹特征
樹特征的想法是在資料上訓練一個相對簡單的樹,并添加預測時間戳作為特征之一。 由于樹模型也可以用于特征重要性,我們可以知道時間如何影響資料以及在什麼時候。此外,我們可以檢視由時間戳建立的拆分,我們可以看到拆分前後概念之間的差異。
在上圖中,我們可以看到日期特征位于根部,這意味着該特征具有最高的資訊增益,這意味着在 7 月 22 日,他們可能在資料中發生了漂移。
漂移檢測實作
- Java 實作:MOA
- Python 實作:scikit-multiflow