在使用VS2010編寫MFC程式時,使用函數:MessageBox("提示資訊"), void CtestDlg::OnBnClickedButton1()
{
MessageBox("你已經送出成功。");
// TODO: 在此添加控件通知處理程式代碼
} 編譯時候出錯,出錯資訊如:
錯誤 1 error C2664: “CWnd::MessageBoxW”: 不能将參數 1 從“const char [17]”轉換為“LPCTSTR” d:/我的檔案/visual studio 2005/projects/test/test/testdlg.cpp 155
很多人不知道原因。現在給出這個錯誤的解決辦法。
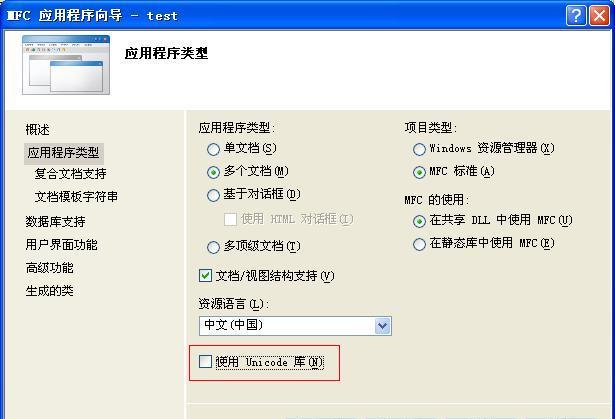
方法一:由于VS2010預設使用的是UNICODE字元集,在建立項目時,把使用UNICODE字元集取消,如下圖:
方法二:在使用的函數前加“_T”如:
void CtestDlg::OnBnClickedButton1()
{
MessageBox(_T("你已經送出成功。"));
// TODO: 在此添加控件通知處理程式代碼
}
方法三:
如需要更改已經建立的項目字元集,則選擇“項目”-》“XXX項目屬性”-》“配置屬性”-》“正常”選項中,把“字元集”改為“使用多位元組字元集”,然後确定。如下圖:

OK了。
或者:
<1> Cstring str;
str.Format("a = %d",a);
<2> ::MessageBox(head,_T("content"),_T("tile"),MB_ok);
<3>AfxMessageBox(nstringID,MB_YESNO|MB_ICONSTOP);
<4>CWnd::MessageBox();
<5>MessageBox((LPTSTR)(LPTSTR)str);
MessageBox釋疑
消息框是個很常用的控件,屬性比較多,本文列出了它的一些常用方法,及指出了它的一些應用場合。
1.
MessageBox(_T("這是一個最簡單的消息框!"));
2.
MessageBox(_T("這是一個有标題的消息框!"),_T("标題"));
3.
MessageBox(_T("這是一個确定 取消的消息框!"),_T("标題"), MB_OKCANCEL );
4.
MessageBox(_T("這是一個警告的消息框!"),_T("标題"), MB_ICONEXCLAMATION );
5.
MessageBox(_T("這是一個兩種屬性的消息框!"),_T("标題"), MB_ICONEXCLAMATION|MB_OKCANCEL );
6.
if(MessageBox(_T("一種常用的應用"),_T("标題"),MB_ICONEXCLAMATION|MB_OKCANCEL)==IDCANCEL)
return;
附其它常用屬性
系統預設圖示,可在消息框上顯示
X錯誤 MB_ICONHAND, MB_ICONSTOP, and MB_ICONERROR
?詢問 MB_ICONQUESTION
!警告 MB_ICONEXCLAMATION and MB_ICONWARNING
i資訊 MB_ICONASTERISK and MB_ICONINFORMATION
按鈕的形式
MB_OK 預設
MB_OKCANCEL 确定取消
MB_YESNO 是否
MB_YESNOCANCEL 是否取消
傳回值
IDCANCEL 取消被選
IDNO 否被選
IDOK 确定被選
IDYES 是被選
補充:
以上消息框的用法是在CWnd的子類中的應用,如果不是,則要MessageBox(NULL,"ddd","ddd",MB_OK); 或MessageBox(hWnd,"ddd","ddd",MB_OK); hWnd為某視窗的句柄,或者直接用AfxMessageBox。
這裡所列出的屬性隻是一些常用屬性,在MSDN中還有更多的屬性
_T釋疑
定義
_T("")是一個宏,定義于tchar.h下。
#define __T(x) L ## x
#define _T(x) __T(x)
作用
他的作用是讓你的程式支援Unicode編碼,
因為Windows使用兩種字元集ANSI和UNICODE,
前者就是通常使用的單位元組方式,
但這種方式處理象中文這樣的雙位元組字元不友善,
容易出現半個漢字的情況。
而後者是雙位元組方式,友善處理雙位元組字元。
Windows NT的所有與字元有關的函數都提供兩種方式的版本,而Windows 9x隻支援ANSI方式。
如果你編譯一個程式為ANSI方式,
_T實際不起任何作用。
而如果編譯一個程式為UNICODE方式,則編譯器會把"Hello"字元串以UNICODE方式儲存。_T和_L的差別在于,_L不管你是以什麼方式編譯,一律以UNICODE方式儲存。
LPSTR:32bit指針指向一個字元串,每個字元占1位元組
LPCSTR:32-bit指針指向一個常字元串,每個字元占1位元組
LPCTSTR:32-bit指針指向一個常字元串,每字元可能占1位元組或2位元組,取決于Unicode是否定義
LPTSTR:32-bit指針每字元可能占1位元組或2位元組,取決于Unicode是否定義
L是表示字元串資源為Unicode的。
比如
wchar_tStr[] = L"Hello World!";
這個就是雙位元組存儲字元了。
_T是一個适配的宏~
當
#ifdef _UNICODE的時候
_T就是L
沒有#ifdef _UNICODE的時候
_T就是ANSI的。
比如
LPTSTR lpStr = new TCHAR[32];
TCHAR* szBuf = _T("Hello");
以上兩句使得無論是在UNICODE編譯條件下還是在ANSI編譯條件下都是正确編譯的。
而且MS推薦你使用相比對的字元串函數。
比如處理LPTSTR或者LPCTSTR的時候,不要用strlen ,而是要用_tcslen
否則在UNICODE的編譯條件下,strlen不能處理wchar_t*的字元串。
T是非常有意思的一個符号(TCHAR、LPCTSTR、LPTSTR、_T()、_TEXT()...),它表示使用一種中間類型,既不明确表示使用 MBCS,也不明确表示使用 UNICODE。那到底使用哪種字元集?編譯的時候才決定