使用一個開源項目,獲得源碼後一般都是按configure/make/make install的步驟進行部署。網上有不少關于使用automake系列工具來生成/管理項目的,最終都指向ibm-developer的一篇文章,但說實話該文章跟真正的開源項目還有一大截距離,大部分coder情願自己寫makefile代替。本文原意是往開源項目中添加代碼,當然不是簡單的往現成的檔案中加幾行了事,而是,往開源項目的目錄結構中添加檔案,并導出接口供開源項目本身或者其他項目使用。
如果直接寫如何添加檔案,那這篇文章又可能隻是一個花瓶,解決不了什麼問題。是以,文章還是得從分析configure内容開始,展現各檔案之間的關系。至于其他枝節,不明自喻。附注,本文使用的開源項目為libvirt1.0.0和sed4.2
先上一張廣為流傳的automake的流程圖:
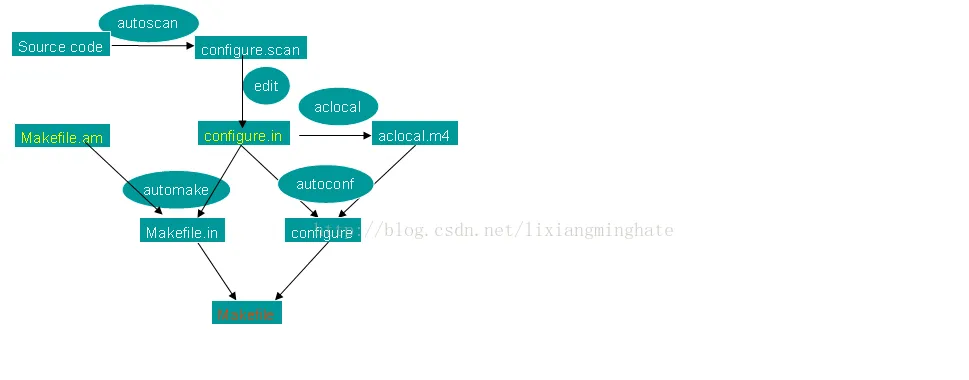
圖1
1.第一個問題,拿到開源項目後,大家都會不約而同的運作configure,以生成makefile檔案,那麼configure中有什麼?
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
清單1,sed項目configure部分内容
#這裡隻摘取部分
#第一部分
...
NEXT_AS_FIRST_DIRECTIVE_WCTYPE_H
NEXT_WCTYPE_H
HAVE_ISWCNTRL
NEXT_AS_FIRST_DIRECTIVE_WCHAR_H
NEXT_WCHAR_H
HAVE_WCHAR_H
HAVE_WINT_T
HAVE_UNISTD_H
NEXT_AS_FIRST_DIRECTIVE_UNISTD_H
#第二部分
...
if test "$cross_compiling" = yes; then
{ $as_echo "$as_me:$LINENO: result: don't care (cross compiling)" >&5
$as_echo "don't care (cross compiling)" >&6; }; XFAIL_TESTS=
else
cat >conftest.$ac_ext <<_ACEOF
/* confdefs.h. */
_ACEOF
cat confdefs.h >>conftest.$ac_ext
cat >>conftest.$ac_ext <<_ACEOF
/* end confdefs.h. */
#include <locale.h>
#include <string.h>
#include <stdlib.h>
#include <wchar.h>
#ifdef HAVE_WCTYPE_H
#include <wctype.h>
#endif
int test(void)
{
char in[] = "\xD0\xB4";
char good[] = "\xD0\x94";
char out[10];
wchar_t in_wc, good_wc;
if (mbtowc (&in_wc, in, 3) == -1)
return 0;
if (mbtowc (&good_wc, good, 3) == -1)
return 0;
if (towupper (in_wc) != good_wc)
return 0;
if (wctomb (out, good_wc) != 2)
return 0;
if (memcmp (out, good, 2))
return 0;
return 1;
}
int main()
{
char *old;
int len;
/* Try hardcoding a Russian UTF-8 locale. If the name "ru_RU.UTF-8"
is invalid, use setlocale again just to get the current locale. */
old = setlocale (LC_CTYPE, "ru_RU.UTF-8");
if (old)
{
if (test())
exit (0);
}
else
old = setlocale (LC_CTYPE, "C");
/* Maybe cyrillic case folding is implemented for all UTF-8 locales.
If the current locale is not UTF-8, the test will be skipped. */
len = strlen (old);
if ((len > 6 && !strcmp (old + len - 6, ".UTF-8"))
|| (len > 6 && !strcmp (old + len - 6, ".utf-8"))
|| (len > 5 && !strcmp (old + len - 5, ".UTF8"))
|| (len > 5 && !strcmp (old + len - 5, ".utf8")))
/* ok */
;
else
exit (1);
/* Run the test in the detected UTF-8 locale. */
setlocale (LC_CTYPE, old);
exit (!test ());
}
_ACEOF
rm -f conftest$ac_exeext
if { (ac_try="$ac_link"
case "(($ac_try" in
*\"* | *\`* | *\\*) ac_try_echo=\$ac_try;;
*) ac_try_echo=$ac_try;;
esac
eval ac_try_echo="\"\$as_me:$LINENO: $ac_try_echo\""
$as_echo "$ac_try_echo") >&5
(eval "$ac_link") 2>&5
ac_status=$?
$as_echo "$as_me:$LINENO: \$? = $ac_status" >&5
(exit $ac_status); } && { ac_try='./conftest$ac_exeext'
{ (case "(($ac_try" in
*\"* | *\`* | *\\*) ac_try_echo=\$ac_try;;
*) ac_try_echo=$ac_try;;
esac
eval ac_try_echo="\"\$as_me:$LINENO: $ac_try_echo\""
$as_echo "$ac_try_echo") >&5
(eval "$ac_try") 2>&5
ac_status=$?
$as_echo "$as_me:$LINENO: \$? = $ac_status" >&5
(exit $ac_status); }; }; then
{ $as_echo "$as_me:$LINENO: result: yes" >&5
$as_echo "yes" >&6; }; XFAIL_TESTS=
else
$as_echo "$as_me: program exited with status $ac_status" >&5
$as_echo "$as_me: failed program was:" >&5
sed 's/^/| /' conftest.$ac_ext >&5
( exit $ac_status )
{ $as_echo "$as_me:$LINENO: result: no" >&5
$as_echo "no" >&6; }; XFAIL_TESTS='utf8-1 utf8-2 utf8-3 utf8-4'
fi
...
#第三部分
# Check whether --enable-i18n was given.
if test "${enable_i18n+set}" = set; then
enableval=$enable_i18n;
else
enable_i18n=yes
fi
if test "x$enable_i18n" = xno; then
ac_cv_func_wcscoll=false
fi
# Check whether --enable-regex-tests was given.
if test "${enable_regex_tests+set}" = set; then
enableval=$enable_regex_tests; if test "x$with_included_regex" = xno; then
enable_regex_tests=no
fi
else
enable_regex_tests=$with_included_regex
fi 仔細看是一些變量定義和一些bash語句用于檢測編譯環境。這configure檔案動辄過萬行,估計都跟一些小的項目的代碼量差不多了,那可能是由某個輸入檔案輸入,然後通過工具生成。結合圖1知,輸入檔案是configure.in/configure.ac生成工具是autoconf。工具肯定是沒法修改了,那隻能退一步,檢視輸入檔案configure.in
清單2,configure.in部分内容:
#這裡隻摘取部分
#configure中第一部分在此檔案中找不到對應項
#對應configure第三部分
AC_MSG_CHECKING([whether UTF-8 case folding tests should pass])
AC_TRY_RUN([
#include <locale.h>
#include <string.h>
#include <stdlib.h>
#include <wchar.h>
#ifdef HAVE_WCTYPE_H
#include <wctype.h>
#endif
int test(void)
{
char in[] = "\xD0\xB4";
char good[] = "\xD0\x94";
char out[10];
wchar_t in_wc, good_wc;
if (mbtowc (&in_wc, in, 3) == -1)
return 0;
if (mbtowc (&good_wc, good, 3) == -1)
return 0;
if (towupper (in_wc) != good_wc)
return 0;
if (wctomb (out, good_wc) != 2)
return 0;
if (memcmp (out, good, 2))
return 0;
return 1;
}
int main()
{
char *old;
int len;
/* Try hardcoding a Russian UTF-8 locale. If the name "ru_RU.UTF-8"
is invalid, use setlocale again just to get the current locale. */
old = setlocale (LC_CTYPE, "ru_RU.UTF-8");
if (old)
{
if (test())
exit (0);
}
else
old = setlocale (LC_CTYPE, "C");
/* Maybe cyrillic case folding is implemented for all UTF-8 locales.
If the current locale is not UTF-8, the test will be skipped. */
len = strlen (old);
if ((len > 6 && !strcmp (old + len - 6, ".UTF-8"))
|| (len > 6 && !strcmp (old + len - 6, ".utf-8"))
|| (len > 5 && !strcmp (old + len - 5, ".UTF8"))
|| (len > 5 && !strcmp (old + len - 5, ".utf8")))
/* ok */
;
else
exit (1);
/* Run the test in the detected UTF-8 locale. */
setlocale (LC_CTYPE, old);
exit (!test ());
}
], [AC_MSG_RESULT([yes]); XFAIL_TESTS=],
[AC_MSG_RESULT([no]); XFAIL_TESTS='utf8-1 utf8-2 utf8-3 utf8-4'],
[AC_MSG_RESULT([don't care (cross compiling)]); XFAIL_TESTS=])
...
#對應configure第二部分
AC_ARG_ENABLE(i18n,[ --disable-i18n disable internationalization (default=enabled)], ,enable_i18n=yes)
if test "x$enable_i18n" = xno; then
ac_cv_func_wcscoll=falsefiAC_ARG_ENABLE(regex-tests,
[ --enable-regex-tests enable regex matcher regression tests (default=yes)],
[if test "x$with_included_regex" = xno; then enable_regex_tests=nofi],
enable_regex_tests=$with_included_regex) 雖然在configure.ac和configure在内容有極大不同,但細看還是有很多相同點,隻是比較隐晦。比如
都有設定變量:
enable_regex_tests=no 都有函數測試:
int main()
{
char *old;
int len;
/* Try hardcoding a Russian UTF-8 locale. If the name "ru_RU.UTF-8"
is invalid, use setlocale again just to get the current locale. */
old = setlocale (LC_CTYPE, "ru_RU.UTF-8");
if (old)
{
if (test())
exit (0);
}
else
old = setlocale (LC_CTYPE, "C");
/* Maybe cyrillic case folding is implemented for all UTF-8 locales.
If the current locale is not UTF-8, the test will be skipped. */
len = strlen (old);
if ((len > 6 && !strcmp (old + len - 6, ".UTF-8"))
|| (len > 6 && !strcmp (old + len - 6, ".utf-8"))
|| (len > 5 && !strcmp (old + len - 5, ".UTF8"))
|| (len > 5 && !strcmp (old + len - 5, ".utf8")))
/* ok */
;
else
exit (1);
/* Run the test in the detected UTF-8 locale. */
setlocale (LC_CTYPE, old);
exit (!test ());
} 這麼說,可以猜測configure中的shell腳本内容是通過configure.ac按某種文法規則組合生成的。
按 http://gnu.april.org/software/automake/manual 的說明,configure中的内容是有configure.ac通過一條條宏語句擴充後生成。configure.ac就像.h檔案定義了大量的宏操作,每個宏中有一個或多個變量。而在configure就像.cpp,在檔案中引用了這些宏。經過編譯宏被展開,隻不過configure中被展開為shell腳本。
1.1)比如
configure.ac中的宏: AC_TRY_RUN([program, [action-if-true [, action-if-false [, action-if-cross-compiling]]]]); 其中,program是C程式的文本。本宏在編譯時使用CFLAGS或者CXXFLAGS以及 CPPFLAGS、LDFLAGS和LIBS。
經過autoconf把宏展開到configure中。當configure運作時,如果被program成功地編譯和連接配接了并且在執行的時候傳回的退出狀态為0,就運作action-if-true中的shell指令。否則就運作action-if-false中的shell指令;而程式的退出狀态可以通過shell變量$ac_status;得到。
放在這個項目中,宏擴充後,configure腳本運作,成功則為XFAIL_TESTS設定xxx,不成功又設定XFAIL_TESTS為xxx
1.2)又如
configure.ac中的宏:AC_ARG_ENABLE (feature, help-string [, action-if-given [, action-if-not-given]])
它進過autoconf,生成shell到configure中,使得如果使用者以選項`--enable-feature'或者`--disable-feature'作為附加參數 運作configure,就運作action-if-given中的shell指令。
如果兩個選項都沒有給出,就運作 action-if-not-given中的shell指令
3)而像宏:AC_DEFINE_UNQUOTED(name, value,[help info])
它更簡單了直接在configure中定義了名為name的變量,值為value。
1.3)結論:
總體來說configure.ac作為configure的輸入檔案,由autoconf将其中定義的宏進行擴充,生成configure中的shell,宏裡面定義了一些變量和一套對應不同變量值所應有的動作。configure在運作時要檢測系統環境,根據檢測結果去設定宏裡的變量以及做出相應的動作。
2.程式的執行總有輸入和輸出,既然configure.ac是configure的輸入檔案,那麼,configure運作後的輸出結果有哪些,即上文提到的相應的動作指啥?
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
首先看configure.ac中這段:
清單3:
# Check whether we are able to follow symlinks
AC_CHECK_FUNC(lstat, have_lstat=yes)
AC_CHECK_FUNC(readlink, have_readlink=yes)
if test "x$have_lstat" = xyes -a "x$have_readlink" = xyes; then
AC_DEFINE(ENABLE_FOLLOW_SYMLINKS, ,[Follow symlinks when processing in place])
fi 對應到configure中
if test "x$have_lstat" = xyes -a "x$have_readlink" = xyes; then
cat >>confdefs.h <<\_ACEOF
#define ENABLE_FOLLOW_SYMLINKS /**/ AC_DEFINE宏用來生成configure中名為ENABLE_FOLLOW_SYMLINKS的宏,在這段shell中,如果檢測到have_lstat=yes同時have_readlink=yes,則定義宏ENABLE_FOLLOW_SYMLINKS。可是configure要ENABLE_FOLLOW_SYMLINKS這個宏幹啥?繼續往後看。
2.1)對于configure運作的結果,會儲存到config.status檔案中,來看下config.status檔案
BEGIN {
...
D["HAVE_GETTEXT"]=" 1"
D["HAVE_DCGETTEXT"]=" 1"
D["ENABLE_FOLLOW_SYMLINKS"]=" /**/"
for (key in D) D_is_set[key] = 1
FS = ""
}
...
if (D_is_set[macro]) {
# Preserve the white space surrounding the "#".
print prefix "define", macro P[macro] D[macro]
next
} else {
# Replace #undef with comments. This is necessary, for example,
# in the case of _POSIX_SOURCE, which is predefined and required
# on some systems where configure will not decide to define it.
if (defundef == "undef") {
print "/*", prefix defundef, macro, "*/"
next
}
} 對configure中定義的宏全部添加到config.status中,并通過循環,測試這些宏的值。如果configure檢測到某一項,則config.h中生成#define 宏名;如果configure沒有檢測到某一項,則在config.h中生成#undef 宏名,如下:
清單4:config.h部分内容
/* Define to the copyright year printed by --version. */
#define COPYRIGHT_YEAR 2009
/* Define to one of `_getb67', `GETB67', `getb67' for Cray-2 and Cray-YMP
systems. This function is required for `alloca.c' support on those systems.
*/
/* #undef CRAY_STACKSEG_END */
/* Define to 1 if using `alloca.c'. */
/* #undef C_ALLOCA */ #configure過程中檢測失敗的用#undef定義
/* Define to 1 if // is a file system root distinct from /. */
/* #undef DOUBLE_SLASH_IS_DISTINCT_ROOT */
/* Follow symlinks when processing in place */
#define ENABLE_FOLLOW_SYMLINKS /**/
/* Define to 1 if translation of program messages to the user's native
language is requested. */
#define ENABLE_NLS 1 2.2)configure檔案頭部還會定義一堆變量,這堆變量在configure.in中找不到歸宿,正如清單2中提到。通過grep -rn 變量名 搜尋,會在makefile.in/makefile中找到這些變量名,如
清單5:makefile.in部分内容
#這部分内容正好彌補了configure.in中沒有找到的變量
NEXT_AS_FIRST_DIRECTIVE_SYS_TIME_H = @NEXT_AS_FIRST_DIRECTIVE_SYS_TIME_H@
NEXT_AS_FIRST_DIRECTIVE_UNISTD_H = @NEXT_AS_FIRST_DIRECTIVE_UNISTD_H@
NEXT_AS_FIRST_DIRECTIVE_WCHAR_H = @NEXT_AS_FIRST_DIRECTIVE_WCHAR_H@
NEXT_AS_FIRST_DIRECTIVE_WCTYPE_H = @NEXT_AS_FIRST_DIRECTIVE_WCTYPE_H@
NEXT_ERRNO_H = @NEXT_ERRNO_H@
NEXT_STDINT_H = @NEXT_STDINT_H@
NEXT_STDIO_H = @NEXT_STDIO_H@ 看makefile.in中的格式,有點像變量指派的形式,具體指派在哪?都說了,這些變量定義在configure中,configure運作後的結果儲存在config.status中,是以,要檢視makefine.in中某個變量的值,可以去config.status中查找,比如
NEXT_AS_FIRST_DIRECTIVE_SYS_TIME_H = @NEXT_AS_FIRST_DIRECTIVE_SYS_TIME_H@ 在config.status中儲存的值為:
清單6:config.status部分内容:
S["REPLACE_GETTIMEOFDAY"]="0"
S["HAVE_STRUCT_TIMEVAL"]="1"
S["HAVE_SYS_TIME_H"]="1"
S["NEXT_AS_FIRST_DIRECTIVE_SYS_TIME_H"]="<sys/time.h>"
S["NEXT_SYS_TIME_H"]="<sys/time.h>"
S["LTLIBINTL"]="" 由此可知NEXT_AS_FIRST_DIRECTIVE_SYS_TIME_H值為<sys/time.h>
2.3)結論:
configure的運作結果儲存到config.status中,其值用于生成config.h中的宏以及為makefile.in中的變量提供值。
3.既然知道config.h中儲存了一堆宏定義,那麼除了configure.ac還有誰同時規定了要檢測這些宏?
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
configure不過是個執行者,肯定不會規劃要生成哪些宏,而configure.in也作為configure的規劃者,并沒有把要生成宏全部寫進自己的規劃書中,比如:
清單7:
/* Follow symlinks when processing in place */
#define ENABLE_FOLLOW_SYMLINKS /**/
/* Define to 1 if translation of program messages to the user's native
language is requested. */
#define ENABLE_NLS 1
/* Define on systems for which file names may have a so-called `drive letter'
prefix, define this to compute the length of that prefix, including the
colon. */ 宏定義:#define ENABLE_NLS 1在configure.in中就找不到,上圖:

由此可知,除了configure.in作為configure的規劃者,一定有另一個規劃者。還是通過grep -rn " ENABLE_NLS"查找 ENABLE_NLS的出處。
很快在config_h.in中找到了英雄的出處:
清單8:config_h.in部分輸出
/* Follow symlinks when processing in place */
#undef ENABLE_FOLLOW_SYMLINKS
/* Define to 1 if translation of program messages to the user's native
language is requested. */
#undef ENABLE_NLS
/* Define on systems for which file names may have a so-called `drive letter'
prefix, define this to compute the length of that prefix, including the
colon. */
#undef FILE_SYSTEM_ACCEPTS_DRIVE_LETTER_PREFIX 類似的,FILE_SYSTEM_ACCEPTS_DRIVE_LETTER_PREFIX也在configure.in中找不到出處,但是可以在config_h.in中找到出處
3.1)結論,config_h.in檔案初始化一部分需要生成的宏,同過configure檢測,則在config.h中輸出#define 宏名,如果檢測失敗,輸出結果為#undef 宏名
4.makefile的生成
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
全篇的目的是生成makefile,前面這麼多也是為他鋪墊。
makefile指定了編譯的檔案,以及編譯的規則。但是倒推回去,誰指定了這些規則,configure裡看不到一行編譯相關的内容(編譯選項除外),剩下的隻有makefile.am和makefile.in了。
開源項目的頂層目錄中的makefile.am隻指定了需要編譯遞歸那些子目錄,而子目錄下的makefile.am則指定了需要編譯的檔案,以及依賴關系,編譯/連接配接選項相關的變量,如圖
這是頂層目錄的makefile.in
下面是子目錄的:
其中編譯相關的變量可以在makefile.am和config.status中找到原型:
最後,經過automake的加工,這些輸入模闆檔案中的内容全部添加到輸出檔案--makefile中:
圖示:makefile中的變量
圖示makefile與makefile.in編譯方式的異同
是以,如果需要往開源項目中添加檔案,最好在makefile.am中添加。但是有時會發生修改makefile.am後automake失敗的情況,無奈隻能到makefile.in中修改。畢竟按文檔,makefile.in是用來生成makefile的模版檔案。
makefile.in中有啥?
清單9:部分makefile.in輸出:
CC = @CC@
CCDEPMODE = @CCDEPMODE@
CFLAGS = @CFLAGS@
COPYRIGHT_YEAR = @COPYRIGHT_YEAR@
CPP = @CPP@
CPPFLAGS = @CPPFLAGS@ 都說了,makefile.in中指定的變量值來自config.status的生成值,那麼回到config.status中檢視這部分變量的值:
清單10:還是部分config.status的輸出:
S["DEPDIR"]=".deps"
S["OBJEXT"]="o"
S["EXEEXT"]=""
S["ac_ct_CC"]="gcc"
S["CPPFLAGS"]=""
S["LDFLAGS"]=""
S["CFLAGS"]="-g -O2"
S["CC"]="gcc"
S["COPYRIGHT_YEAR"]="2009" 看到沒,編譯連接配接相關的變量值在此!經過automake,把config.status中的值裝入到模版檔案makefile.in,生成makefile,如下:
BITSIZEOF_WCHAR_T =
BITSIZEOF_WINT_T =
CC = gcc
CCDEPMODE = depmode=gcc3
CFLAGS = -g -O2
COPYRIGHT_YEAR = 2009
CPP = gcc -E
CPPFLAGS =
CYGPATH_W = echo 此外,各個子目錄下的makefile.in還指定了生成makefile源碼的方式。