再次吐槽公司的sb環境,不讓上網不能插優盤,今天有事回家寫一下筆記HBase region split
在管理叢集時,最容易導緻hbase節點發生故障的恐怕就是hbase region split和compact的了,日志有split時間太長;檔案找不到;split的時候response too slow等等,是以先看看hbase region split源碼,希望對以後能有幫助
HBase region split源碼分析
一、流程概述
1.HBaseAdmin 發起 hbase split
2.HRegionServer 确定分割點 region split point
3.CompactSplitThread和SplitRequest 進行region分割
3.1SplitTransaction st.prepare()初始化兩個子region
3.2splitTransaction execute執行分割
3.2.1兩個子region DaughterOpener線程 start
3.2.2若region 需要compact,進行compact路程
3.2.3HRegionServer添加子region到meta表,加入到RegionServer裡
3.3修改zk節點狀态,等待split結束
二 、hbase region split UML圖
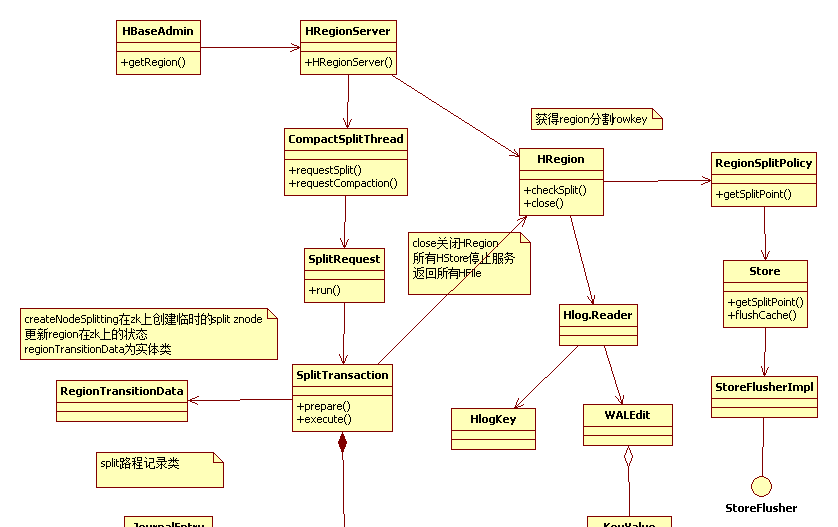
三、詳細分析
1.HBaseAdmin 發起 hbase split
public void split(final byte [] tableNameOrRegionName,
final byte [] splitPoint) throws IOException, InterruptedException {
CatalogTracker ct = getCatalogTracker();
try {
Pair<HRegionInfo, ServerName> regionServerPair
= getRegion(tableNameOrRegionName, ct);//獲得HRI,若是但region
if (regionServerPair != null) {
if (regionServerPair.getSecond() == null) {
throw new NoServerForRegionException(Bytes.toStringBinary(tableNameOrRegionName));
} else {
//split region 重點分析方法
split(regionServerPair.getSecond(), regionServerPair.getFirst(), splitPoint);
}
} else {
//table split流程
final String tableName = tableNameString(tableNameOrRegionName, ct);
List<Pair<HRegionInfo, ServerName>> pairs =
MetaReader.getTableRegionsAndLocations(ct,
tableName);
for (Pair<HRegionInfo, ServerName> pair: pairs) {
// May not be a server for a particular row
if (pair.getSecond() == null) continue;
HRegionInfo r = pair.getFirst();
// check for parents
if (r.isSplitParent()) continue;
// if a split point given, only split that particular region
if (splitPoint != null && !r.containsRow(splitPoint)) continue;
// call out to region server to do split now
split(pair.getSecond(), pair.getFirst(), splitPoint);
}
}
} finally {
cleanupCatalogTracker(ct);
}
}
2.HRegionServer 确定分割點 region split point
@Override
public void splitRegion(HRegionInfo regionInfo, byte[] splitPoint)
throws NotServingRegionException, IOException {
checkOpen();//檢查server和hdfs是否可用
HRegion region = getRegion(regionInfo.getRegionName());//根據HRI擷取region
region.flushcache();//flush cache 有幾種情況不進行flush
//the cache is empte | the region is closed.| a flush is already in progress | writes are disabled
region.forceSplit(splitPoint);//設定split point
compactSplitThread.requestSplit(region, region.checkSplit());//擷取split point,進行split
}
獲得split point詳細過程,擷取最适合的store-hbase現在就是取最大的,擷取store的midkey作為splitpoint
protected byte[] getSplitPoint() {
byte[] explicitSplitPoint = this.region.getExplicitSplitPoint();
if (explicitSplitPoint != null) {
return explicitSplitPoint;
}
Map<byte[], Store> stores = region.getStores();
byte[] splitPointFromLargestStore = null;
long largestStoreSize = 0;
for (Store s : stores.values()) {
byte[] splitPoint = s.getSplitPoint();
long storeSize = s.getSize();
if (splitPoint != null && largestStoreSize < storeSize) {//獲得最大store
splitPointFromLargestStore = splitPoint;
largestStoreSize = storeSize;
}
}
return splitPointFromLargestStore;
}
3.CompactSplitThread和SplitRequest 進行region分割
這裡是split中較為複雜的過程
public void run() {
if (this.server.isStopping() || this.server.isStopped()) {
LOG.debug("Skipping split because server is stopping=" +
this.server.isStopping() + " or stopped=" + this.server.isStopped());
return;
}
try {
final long startTime = System.currentTimeMillis();
SplitTransaction st = new SplitTransaction(parent, midKey);
// If prepare does not return true, for some reason -- logged inside in
// the prepare call -- we are not ready to split just now. Just return.
// 3.1SplitTransaction st.prepare()初始化兩個子region
if (!st.prepare()) return;
try {
st.execute(this.server, this.server);//3.2splitTransaction execute執行分割
this.server.getMetrics().incrementSplitSuccessCount();
} catch (Exception e) {
。。。。。。。。。。。。
3.2splitTransaction execute執行分割
public PairOfSameType<HRegion> execute(final Server server,
final RegionServerServices services)
throws IOException {
PairOfSameType<HRegion> regions = createDaughters(server, services);
//建立split臨時目錄,改變region zk狀态,關閉region,停止所有store服務
//建立daughter目錄,将region storefile放入目錄中
//建立子region A、B,在zk上注冊,并且設定原HRI下線
openDaughters(server, services, regions.getFirst(), regions.getSecond());
transitionZKNode(server, services, regions.getFirst(), regions.getSecond());
return regions;
}
加一個同樣複雜的
3.2.0 createDaughters函數的操作
這裡建立兩個子Region,包括他們的regioninfo,并且将父region的hfile引用寫入子Region中
生成兩個子region的代碼: SplitTransaction.stepsBeforePONR Java代碼

- public PairOfSameType<HRegion> stepsBeforePONR(final Server server,
- final RegionServerServices services, boolean testing) throws IOException {
- // Set ephemeral SPLITTING znode up in zk. Mocked servers sometimes don't
- // have zookeeper so don't do zk stuff if server or zookeeper is null
- if (server != null && server.getZooKeeper() != null) {
- try {
- //步驟1@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- createNodeSplitting(server.getZooKeeper(),
- parent.getRegionInfo(), server.getServerName(), hri_a, hri_b);
- } catch (KeeperException e) {
- throw new IOException("Failed creating PENDING_SPLIT znode on " +
- this.parent.getRegionNameAsString(), e);
- }
- }
- this.journal.add(JournalEntry.SET_SPLITTING_IN_ZK);
- if (server != null && server.getZooKeeper() != null) {
- // After creating the split node, wait for master to transition it
- // from PENDING_SPLIT to SPLITTING so that we can move on. We want master
- // knows about it and won't transition any region which is splitting.
- //步驟2@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- znodeVersion = getZKNode(server, services);
- }
- //步驟3@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- this.parent.getRegionFileSystem().createSplitsDir();
- this.journal.add(JournalEntry.CREATE_SPLIT_DIR);
- Map<byte[], List<StoreFile>> hstoreFilesToSplit = null;
- Exception exceptionToThrow = null;
- try{
- //步驟4@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- hstoreFilesToSplit = this.parent.close(false);
- } catch (Exception e) {
- exceptionToThrow = e;
- }
- if (exceptionToThrow == null && hstoreFilesToSplit == null) {
- // The region was closed by a concurrent thread. We can't continue
- // with the split, instead we must just abandon the split. If we
- // reopen or split this could cause problems because the region has
- // probably already been moved to a different server, or is in the
- // process of moving to a different server.
- exceptionToThrow = closedByOtherException;
- }
- if (exceptionToThrow != closedByOtherException) {
- this.journal.add(JournalEntry.CLOSED_PARENT_REGION);
- }
- if (exceptionToThrow != null) {
- if (exceptionToThrow instanceof IOException) throw (IOException)exceptionToThrow;
- throw new IOException(exceptionToThrow);
- }
- if (!testing) {
- //步驟5@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- services.removeFromOnlineRegions(this.parent, null);
- }
- this.journal.add(JournalEntry.OFFLINED_PARENT);
- // TODO: If splitStoreFiles were multithreaded would we complete steps in
- // less elapsed time? St.Ack 20100920
- //
- // splitStoreFiles creates daughter region dirs under the parent splits dir
- // Nothing to unroll here if failure -- clean up of CREATE_SPLIT_DIR will
- // clean this up.
- //步驟6@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- splitStoreFiles(hstoreFilesToSplit);
- // Log to the journal that we are creating region A, the first daughter
- // region. We could fail halfway through. If we do, we could have left
- // stuff in fs that needs cleanup -- a storefile or two. Thats why we
- // add entry to journal BEFORE rather than AFTER the change.
- //步驟7@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
- this.journal.add(JournalEntry.STARTED_REGION_A_CREATION);
- HRegion a = this.parent.createDaughterRegionFromSplits(this.hri_a);
- // Ditto
- this.journal.add(JournalEntry.STARTED_REGION_B_CREATION);
- HRegion b = this.parent.createDaughterRegionFromSplits(this.hri_b);
- return new PairOfSameType<HRegion>(a, b);
- }
1.RegionSplitPolicy.getSplitPoint()獲得region split的split point ,最大store的中間點midpoint最為split point
2.SplitRequest.run()
執行個體化SplitTransaction
st.prepare():split前準備:region是否關閉,所有hfile是否被引用
st.execute:執行split操作
1.createDaughters 建立兩個region,獲得parent region的寫鎖
1在zk上建立一個臨時的node splitting point,
2等待master直到這個region轉為splitting狀态
3之後建立splitting的檔案夾,
4等待region的flush和compact都完成後,關閉這個region
5從HRegionServer上移除,加入到下線region中
6進行regionsplit操作,建立線程池,用StoreFileSplitter類将region下的所有Hfile(StoreFile)進行split,
(split row在hfile中的不管,其他的都進行引用,把引用檔案分别寫到region下邊)
7.生成左右兩個子region,删除meta上parent,根據引用檔案生成子region的regioninfo,寫到hdfs上
2.stepsAfterPONR 調用DaughterOpener類run打開兩個子region,調用initilize
a)向hdfs上寫入.regionInfo檔案以便meta挂掉以便恢複
b)初始化其下的HStore,主要是LoadStoreFiles函數:
對于該store函數會構造storefile對象,從hdfs上擷取路徑和檔案,每個檔案一個
storefile對象,對每個storefile對象會讀取檔案上的内容建立一個
HalfStoreFileReader讀對象來操作該region的父region上的相應的檔案,及該
region上目前存儲的是引用檔案,其指向的是其父region上的相應的檔案,對該
region的所有讀或寫都将關聯到父region上
将子Region添加到rs的online region清單上,并添加到meta表上
(0.98版本,包含以下3.2.1~3)
(0.94版本,兩個方法之後給合在了stepsAfterPONR裡邊)
3.2.1兩個子region DaughterOpener線程 start
final RegionServerServices services, HRegion a, HRegion b)
throws IOException {
boolean stopped = server != null && server.isStopped();
boolean stopping = services != null && services.isStopping();
// TODO: Is this check needed here?
if (stopped || stopping) {
LOG.info("Not opening daughters " +
b.getRegionInfo().getRegionNameAsString() +
" and " +
a.getRegionInfo().getRegionNameAsString() +
" because stopping=" + stopping + ", stopped=" + stopped);
} else {
// Open daughters in parallel.建立兩個字region打開操作類
DaughterOpener aOpener = new DaughterOpener(server, a);
DaughterOpener bOpener = new DaughterOpener(server, b);
aOpener.start();
bOpener.start();
try {
aOpener.join();
bOpener.join();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IOException("Interrupted " + e.getMessage());
}
if (aOpener.getException() != null) {
throw new IOException("Failed " +
aOpener.getName(), aOpener.getException());
}
if (bOpener.getException() != null) {
throw new IOException("Failed " +
bOpener.getName(), bOpener.getException());
}
if (services != null) {
try {
// add 2nd daughter first (see HBASE-4335)
services.postOpenDeployTasks(b, server.getCatalogTracker(), true);
// Should add it to OnlineRegions
services.addToOnlineRegions(b);
services.postOpenDeployTasks(a, server.getCatalogTracker(), true);
services.addToOnlineRegions(a);
} catch (KeeperException ke) {
throw new IOException(ke);
}
}
}
}
調用HRegion 打開方法openHRegion
protected HRegion openHRegion(final CancelableProgressable reporter)
throws IOException {
checkCompressionCodecs();
long seqid = initialize(reporter);
//初始化region,
//1.checkRegionInfoOnFilesystem将HRegionInfo寫入檔案
//2.cleanupTempDir 清空老region臨時目錄
//3.初始化HRegion store,加載hfile
//4.獲得recover.edit檔案,找到對應的store,将讀取的keyvalue輸出到store,恢複hregion
if (this.log != null) {
this.log.setSequenceNumber(seqid);
}
return this;
}
3.2.2若region 需要compact,進行compact過程
compact過程有點複雜,過程如下:
1.将所有storefile放入compact候選者
2.交給coprocessor做處理,選擇compact storefile
3.若coprocessor沒有做處理,則采用系統算法選擇
3.1必須要進行compact的檔案,檔案大小大于compact最大值并且沒有其他被引用
3.2必須要進行compact檔案小于compact檔案最小數
3.3 isMajorCompaction判斷是否需要major compact
3.3.1當ttl大于storefile中最大檔案compact time,則不需要
3.3.2 以上反之,需要
3.3.3 最後一次major compaction時間大于majorCompactionTime,需要
3.4 當compact檔案大于compact檔案最大數,且需要major compaction活強制major compaction,則進行major compaction
3.5或則進行minor compact,他兩個的差別在于一個compact檔案數是所有并且删除就tts和version的資料,一個compact檔案數不大于maxcompactfile配置
public CompactionRequest requestCompaction(int priority) throws IOException {
// don't even select for compaction if writes are disabled
if (!this.region.areWritesEnabled()) {
return null;
}
CompactionRequest ret = null;
this.lock.readLock().lock();
try {
synchronized (filesCompacting) {
// candidates = all storefiles not already in compaction queue
List<StoreFile> candidates = Lists.newArrayList(storefiles);
if (!filesCompacting.isEmpty()) {
// exclude all files older than the newest file we're currently
// compacting. this allows us to preserve contiguity (HBASE-2856)
StoreFile last = filesCompacting.get(filesCompacting.size() - 1);
int idx = candidates.indexOf(last);
Preconditions.checkArgument(idx != -1);
candidates.subList(0, idx + 1).clear();
}
boolean override = false;
if (region.getCoprocessorHost() != null) {
override = region.getCoprocessorHost().preCompactSelection(
this, candidates);
}
CompactSelection filesToCompact;
if (override) {
// coprocessor is overriding normal file selection
filesToCompact = new CompactSelection(conf, candidates);
} else {
filesToCompact = compactSelection(candidates, priority);
}
if (region.getCoprocessorHost() != null) {
region.getCoprocessorHost().postCompactSelection(this,
ImmutableList.copyOf(filesToCompact.getFilesToCompact()));
}
// no files to compact
if (filesToCompact.getFilesToCompact().isEmpty()) {
return null;
}
// basic sanity check: do not try to compact the same StoreFile twice.
if (!Collections.disjoint(filesCompacting, filesToCompact.getFilesToCompact())) {
// TODO: change this from an IAE to LOG.error after sufficient testing
Preconditions.checkArgument(false, "%s overlaps with %s",
filesToCompact, filesCompacting);
}
filesCompacting.addAll(filesToCompact.getFilesToCompact());
Collections.sort(filesCompacting, StoreFile.Comparators.FLUSH_TIME);
// major compaction iff all StoreFiles are included
boolean isMajor = (filesToCompact.getFilesToCompact().size() == this.storefiles.size());
if (isMajor) {
// since we're enqueuing a major, update the compaction wait interval
this.forceMajor = false;
}
// everything went better than expected. create a compaction request
int pri = getCompactPriority(priority);
ret = new CompactionRequest(region, this, filesToCompact, isMajor, pri);
}
} finally {
this.lock.readLock().unlock();
}
if (ret != null) {
CompactionRequest.preRequest(ret);
}
return ret;
}
在貼一段選compact檔案的
public CompactionRequest selectCompaction(Collection<StoreFile> candidateFiles,
final List<StoreFile> filesCompacting, final boolean isUserCompaction,
final boolean mayUseOffPeak, final boolean forceMajor) throws IOException {
// Preliminary compaction subject to filters
ArrayList<StoreFile> candidateSelection = new ArrayList<StoreFile>(candidateFiles);
// Stuck and not compacting enough (estimate). It is not guaranteed that we will be
// able to compact more if stuck and compacting, because ratio policy excludes some
// non-compacting files from consideration during compaction (see getCurrentEligibleFiles).
int futureFiles = filesCompacting.isEmpty() ? 0 : 1;
boolean mayBeStuck = (candidateFiles.size() - filesCompacting.size() + futureFiles)
>= storeConfigInfo.getBlockingFileCount();
candidateSelection = getCurrentEligibleFiles(candidateSelection, filesCompacting);
LOG.debug("Selecting compaction from " + candidateFiles.size() + " store files, " +
filesCompacting.size() + " compacting, " + candidateSelection.size() +
" eligible, " + storeConfigInfo.getBlockingFileCount() + " blocking");
long cfTtl = this.storeConfigInfo.getStoreFileTtl();
if (!forceMajor) {
// If there are expired files, only select them so that compaction deletes them
if (comConf.shouldDeleteExpired() && (cfTtl != Long.MAX_VALUE)) {
ArrayList<StoreFile> expiredSelection = selectExpiredStoreFiles(
candidateSelection, EnvironmentEdgeManager.currentTimeMillis() - cfTtl);
if (expiredSelection != null) {
return new CompactionRequest(expiredSelection);
}
}
candidateSelection = skipLargeFiles(candidateSelection);
}
// Force a major compaction if this is a user-requested major compaction,
// or if we do not have too many files to compact and this was requested
// as a major compaction.
// Or, if there are any references among the candidates.
boolean majorCompaction = (
(forceMajor && isUserCompaction)
|| ((forceMajor || isMajorCompaction(candidateSelection))
&& (candidateSelection.size() < comConf.getMaxFilesToCompact()))
|| StoreUtils.hasReferences(candidateSelection)
);
if (!majorCompaction) {
// we're doing a minor compaction, let's see what files are applicable
candidateSelection = filterBulk(candidateSelection);
candidateSelection = applyCompactionPolicy(candidateSelection, mayUseOffPeak, mayBeStuck);
candidateSelection = checkMinFilesCriteria(candidateSelection);
}
candidateSelection = removeExcessFiles(candidateSelection, isUserCompaction, majorCompaction);
CompactionRequest result = new CompactionRequest(candidateSelection);
result.setOffPeak(!candidateSelection.isEmpty() && !majorCompaction && mayUseOffPeak);
return result;
}
3.2.3HRegionServer添加子region到meta表,加入到RegionServer裡
更新meta表
// If daughter of a split, update whole row, not just location.更新meta表 loaction和rowkey
MetaEditor.addDaughter(ct, r.getRegionInfo(),
this.serverNameFromMasterPOV);
加入regionserver
public void addToOnlineRegions(HRegion region) {
this.onlineRegions.put(region.getRegionInfo().getEncodedName(), region);
}
3.3修改zk節點狀态,等待split結束
/* package */void transitionZKNode(final Server server,
final RegionServerServices services, HRegion a, HRegion b)
throws IOException {
// Tell master about split by updating zk. If we fail, abort.
if (server != null && server.getZooKeeper() != null) {
try {
this.znodeVersion = transitionNodeSplit(server.getZooKeeper(),
parent.getRegionInfo(), a.getRegionInfo(), b.getRegionInfo(),
server.getServerName(), this.znodeVersion);
int spins = 0;
// Now wait for the master to process the split. We know it's done
// when the znode is deleted. The reason we keep tickling the znode is
// that it's possible for the master to miss an event.
do {
if (spins % 10 == 0) {
LOG.debug("Still waiting on the master to process the split for " +
this.parent.getRegionInfo().getEncodedName());
}
Thread.sleep(100);
// When this returns -1 it means the znode doesn't exist
this.znodeVersion = tickleNodeSplit(server.getZooKeeper(),
parent.getRegionInfo(), a.getRegionInfo(), b.getRegionInfo(),
server.getServerName(), this.znodeVersion);
spins++;
} while (this.znodeVersion != -1 && !server.isStopped()
&& !services.isStopping());
結束了,有時間再看看compact過程,其實在split中已經包含compact的過程,不知道是不是所有的compact流程都一樣