目錄
- 引言
- 一、 Web 基礎
-
- 1. 域名和 DNS
-
- 1.1 域名的概念
- 1.2 域名的結構
- 1.3 域名的申請
- 2. Hosts 檔案
-
- 2.1 作用
- 2.2 修改 Hosts 檔案
- 2.3 網卡中配置
- 3. 網頁與 HTML
-
- 3.1 網頁概述
- 3.2 網頁相關概念
- 3.3 HTML 概述
- 3.4 Web 概述
- 3.5 靜态頁面與動态頁面
- 二、HTTP 協定
-
- 1. 概述
- 2. 三次握手,四次斷開
- 3. 無狀态協定
- 4. HTTP 版本
- 5. HTTP 方法
- 6. HTTP 狀态碼
- 總結
引言
随着網際網路的飛速發展,企業資訊化應用大多已采用網頁的形式建構,掌握網頁的相關的知識和 HTTP 的請求流程,是掌握網際網路技術的第一步。
一、 Web 基礎
1. 域名和 DNS
1.1 域名的概念
- 網絡是基于 TCP/IP 協定進行通信和連接配接的,每一台主機都有一個唯一的固定的 IP 位址,以差別于網絡上成千上萬個使用者和計算機。
- 網絡中的位址方案分為兩套:IP 位址系統和域名位址系統,兩套位址系統是一一對應的
- 由于 IP 位址是數字辨別,使用時難以記憶和書寫,是以在IP位址的基礎上發展出一種符号化的位址方案,來代替數字型的IP位址
- 每個符号化的位址都與特定的 IP 位址對應,這樣網絡上資源通路起來就比較容易的多,這個與網絡上的數字型 IP 位址相對應的字元型位址,就是域名。
1.2 域名的結構
域名的結構和類型可以參照之前的總結
1.3 域名的申請
- 域名注冊是 Internet 中用于解決位址對應問題的一種方法
- 遵循先申請先注冊原則
- 域名注冊步驟: 準備申請資料——》尋找域名注冊網站——》查詢域名——》正式申請——》申請成功
2. Hosts 檔案
Hosts 檔案是一個用于存儲計算機網絡中節點資訊的檔案,可以将主機名映射到相應的 IP 位址,實作 DNS 的功能,可以由計算機的使用者進行修改控制。
2.1 作用
- 在網絡上通路網站,要先通過 DNS 伺服器把要通路的域名解析成 IP 位址後,計算機才能對這個網絡域名進行通路
- 由于 DNS 做域名解析和傳回 IP 需要時間,為了提高解析效率,可以通過在 Hosts 檔案中建立域名和 IP 的映射關系來達到目的。
- 在進行 DNS 請求前,系統會先檢查自己的 Hosts 檔案是否有這個網絡域名映射關系;如果有,就調用這個 IP 位址映射,如果沒有,再向已知的 DNS 伺服器提出域名解析,也就是說 Hosts 的請求級别比 DNS 高。
2.2 修改 Hosts 檔案
- /etc/hosts
#linux系統中負責快速解析的檔案,包含了ip與主機名的映射關系,在沒有DNS伺服器的情況下,\
使用本地/etc/hosts完成解析/映射,實作快速通路
[[email protected] /opt]#vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.134 www.gkd.com
- /etc/resolv.conf
#DNS用戶端配置檔案,主要用于設定DNS伺服器的iP和域名,還包含了主機域名的搜尋順序等等,\
這個檔案是由域名解析器(resolver,一個根據主機名解析IP位址的庫)使用的配置檔案。
[[email protected] /etc]#vim resolv.conf
# Generated by NetworkManager
search localdomain
nameserver 192.168.8.2
2.3 網卡中配置
[[email protected] /etc]#vim /etc/sysconfig/network-scripts/ifcfg-ens33
DNS1=114.114.114.114
DNS2=8.8.8.8
#生效順序: hosts檔案 > 網卡配置檔案 > /etc/resolv.conf
3. 網頁與 HTML
3.1 網頁概述
- 網頁是一個檔案,存放在世界上某個角落的某一部計算機中,而這部計算機必須是與網際網路相連的,網頁經由網址(URL)來識别與存放,是網際網路的一"頁"。
-
網頁可以包括如下内容:
① 文本: 文本是網頁上最重要的資訊載體與交流工具,網頁中的主要資訊一般都以文本形式為主。
② 圖像: 圖像在網頁中具有提供資訊并展示直覺形象的作用。靜态圖像: 在網頁中可能是圖檔或矢量圖形。通常為GIF、JPEG或PNG或矢量格式,如SVG或Flash。動畫圖像: 通常為GIF和SVG。
③ Flash動畫: 動畫在網頁中的作用是有效地吸引通路者更多的注意
④ 聲音: 聲音是多媒體和視訊網頁重要的組成部分。
⑤ 視訊: 視訊檔案的采用使網頁效果更加精彩且富有動感。
⑥ 表格:表格用來在網頁中控制頁面資訊的布局方式。
⑦ 導航欄: 導航欄在網頁中是一組超連結,其連接配接的目的端是網頁中重要的頁面。
⑧ 互動式表單: 表單在網頁中通常用來連接配接資料庫并接受使用者在浏覽器端輸入的資料,利用資料庫為用戶端與伺服器端提供更多的互動。
3.2 網頁相關概念
- 域名:浏覽網頁時輸入的網址
- HTTP :用來傳輸網頁的通信協定,使用浏覽器通路網址時,在域名前面要加上 http:// ,表示使用 http 協定傳輸網頁
- URL:是一種網際網路尋址系統,表示網絡上資源的位置路徑
- HTML:是編寫網頁的超文本标記語言
- 超連結:将網站中不同網頁連結起來的功能
- 釋出:将制作好的網頁上傳到伺服器提供使用者通路的過程
3.3 HTML 概述
- HTML 是超文本标記語言,是一種規範,也是一種标準,通過标記符來标記要顯示的網頁中的各個部分
- 網頁檔案本身是一種文本檔案,通過在文本檔案中添加标記符,可以告訴浏覽器如何顯示其中的内容
- HTML 檔案可以使用任何能夠生成 txt 檔案的文本編輯器來編輯,生成超文本标記語言檔案,隻需修改檔案名字尾為 “.html” 或 “.htm” 即可
3.4 Web 概述
- web (world wide Web)即全球廣域網,也稱為網際網路,是一種分布式圖形資訊系統,建立在Internet上的一種網絡服務
- web1.0 與 web2.0
web1.0
以編輯為特征,網站提供給使用者的内容是編輯處理後的,然後使用者閱讀網站提供的内容這個過程是網站到使用者的單向行為(靜态頁面的概念)黃頁
web2.0
更注重使用者的互動作用,使用者既是網站内容的消費者(浏覽者),也是網站内容的制造者
加強了網站與使用者之間的互動,網站内容基于使用者提供,網站的諸多功能也由使用者參與建設,實作了網站與使用者雙向的交流與參與 web2.0特征
使用者分享、以興趣為聚合點的社群、開放的平台,活躍的使用者
3.5 靜态頁面與動态頁面
- 靜态頁面
是标準的HTAL檔案 ,擴充名是 .htm、 .html,例如文本、圖像、聲音、Flash動畫、用戶端腳本和Activex控件及Java小程式等
是網站建設的基礎,早期網站一般都由靜态網頁制作
沒有背景資料庫、不含程式和不可互動的網頁
相對更新起來比較麻煩,适用于一般更新較少的展示型網站
- 靜态頁面特點
① 每個靜态網頁都有一個固定的URL,且URL以.htm、.html、.shtml等常見形式為字尾,而不含有"?"
② 網頁内容一經釋出到網站伺服器上,無論是否有使用者通路,每個靜态網頁都是儲存在網站伺服器上的
③ 靜态網頁的内容相對穩定,容易被搜尋引擎檢索
④ 靜态網頁沒有資料庫的支援,在網站制作和維護方面工作量較大,是以當網站資訊量很大時完全依靠靜态網頁制作方式比較困難
⑤ 靜态網頁的互動性較差,在功能方面有較大的限制
⑥ 頁面浏覽速度迅速,過程無需連接配接資料庫,開啟頁面速度快于動态頁面
- 動态頁面
指跟靜态頁面相對的一種網頁程式設計技術
動态網頁URL的字尾不是 .html 、.htm 、.shtml 、.xml等靜态網頁的常見網頁制作格式,而是以 .aspx 、.asp 、 .jsp 、 .php 、.perl 、.cgi 等形式為字尾,并且在動态頁面網頁網址中有一個标志性的符号—— " ? "
常用的語言有PHP、JsP、Python、 Ruby等
- 動态頁面特點
① 互動性:網頁會根據使用者的要求和選擇而動态改變和響應,将浏覽器作為用戶端界面,這将是今後的大勢所趨
② 自動更新:無須手動地更新HTML文檔,便會自動生成新的頁面,可以大大節省工作量
③ 因時因人而變:當不同的時間,不同的人通路同一網址時會産生不同的頁面 通路的使用者的權限、身份
二、HTTP 協定
1. 概述
- HTTP 超文本傳輸協定 (HyperText TransferProtocol) 是網際網路上應用最為廣泛的一種網絡協定,它是基于 TCP/IP協定的應用層傳輸協定,簡單來說就是用戶端和服務端進行資料傳輸的一種規則。
- HTTP/HTTPS 是應用層上的協定,建立在傳輸層 TCP 之上,用戶端通過與服務端進行 TCP 連接配接(三次握手),之後發送 HTTP 請求與接收 HTTP 響應都是通過通路 Socket 接口來調用 TCP 協定實作。(每次都會調用)
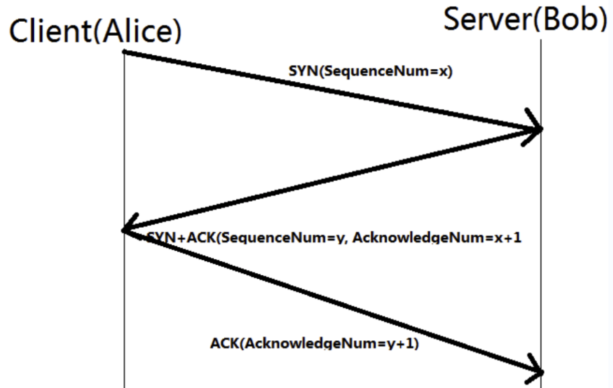
2. 三次握手,四次斷開
- 三次握手
SYN: Synchronize Sequence Numbers,同步序列編号,建立連接配接的信号。用戶端在接受到 SYN 消息時,就會在自己的段内生成一個随機值 X。
SYN-ACK:伺服器收到 SYN 後,打開用戶端連接配接,發送一個 SYN-ACK 作為答複。确認号設定為比接收到的序列号多一個,即 X + 1,伺服器為資料包選擇的序列号是另一個随機數 Y。
ACK:Acknowledge character, 确認字元,表示發來的資料已确認接收無誤。最後,用戶端将 ACK 發送給伺服器。序列号被設定為所接收的确認值即 Y + 1。
FIN: 斷開連接配接信号
當用戶端與服務端建立TCP協定時:
① 首先用戶端會發送一個SYN,例如X。
② 當服務端收到後傳回确認消息X+1,以及連接配接資料包随機數Y。這就是SYN-ACK
③ 用戶端收到後傳回最後确認字元Y+1,這就是ACK。
如果用戶端這個時候發現服務端傳回的并不是X+1,會重新發起SYN,直至正确方可連接配接,這也就是他的重試機制
其實說白了三次握手就是當用戶端發起申請後不僅用戶端要确認服務端,服務端也要确認用戶端,是以為什麼兩次就不行,多一次又繁瑣。
好比如撥通電話:
A: 喂,你好,能聽見我說話嗎?(SYN請求)
B:能聽見,(ACK響應)你能聽見我說話嗎?(SYN請求)
A:能聽見。(ACK響應)
三次握手,确認建立連接配接。
- 四次斷開
① 當用戶端決定斷開時,向服務端發送FIN信号,進入 FIN_WAIT_1 狀态,等待來自伺服器的 ACK 響應
② 用戶端收到伺服器發送的 ACK 響應後,用戶端就進入 FIN_WAIT_2 狀态,然後等待來自伺服器的 FIN 信号
③ 伺服器發送 ACK 确認消息後,一段時間(可以配置關閉)會發送 FIN 信号給用戶端,告知用戶端可以進行關閉。
④ 用戶端收到從服務端發送的 FIN 消息時,用戶端就會由 FIN_WAIT_2 狀态變為 TIME_WAIT 狀态,在這裡要注意這個時候用戶端可以重新連接配接到服務端為了防止資訊丢失,如果不進行連接配接,那麼在一段時間連接配接關閉,用戶端所有資料包括端口号緩存資料等全部釋放
挂斷電話例子:
A:我要挂電話了。(FIN請求)
B:好的。(ACK響應)
B:那我也挂電話了。(FIN請求)
A:好的。(ACK響應)
四次揮手,連接配接關閉。

- 為什麼是三次握手,而不是二次?
為了實作可靠資料傳輸, TCP 協定的通信雙方, 都必須維護一個序列号, 以辨別發送出去的資料包中, 哪些是已經被對方收到的。 三次握手的過程即是通信雙方互相告知序列号起始值, 并确認對方已經收到了序列号起始值的必經步驟
如果隻是兩次握手, 至多隻有連接配接發起方的起始序列号能被确認, 另一方選擇的序列号則得不到确認
- 為什麼是四次斷開?
因為當 Server 端收到 Client 端的 SYN連 接請求封包後,可以直接發送SYN+ACK封包。其中ACK封包是用來應答的,SYN封包是用來同步的。但是關閉連接配接時,當Server端收到FIN封包時,很可能并不會立即關閉SOCKET,是以隻能先回複一個ACK封包,告訴Client端,“你發的FIN封包我收到了”。隻有等到我Server端所有的封包都發送完了,我才能發送FIN封包,是以不能一起發送。故需要四步握手。
3. 無狀态協定
- 無狀态協定是指浏覽器對于事務的處理沒有記憶能力也就是說伺服器并不知道用戶端進行了什麼操作,比如關閉浏覽器再開啟通路等
- HTTP 是一種無狀态 (stateless) 協定,HTTP 協定本身不會對發送過的請求和相應的通信狀态進行持久化處理(存儲、儲存〉。
- 這樣做的目的是為了保持 TCP 協定的簡單性,進而能夠快速處理大量的事務,提高效率。
- 然而,在許多應用場景中,我們需要保持使用者登入的狀态或記錄使用者購物車中的商品。由于 HTTP 是無狀态協定,是以必須引入一些技術來記錄管理狀态,例如 cookie。
Cookie 是一種在用戶端保持 HTTP 狀态資訊的技術,它好比商場發放的優惠卡。
Cookie是在浏覽器通路WEB伺服器的某個資源時,由WEB伺服器在HTTP響應消息頭中附帶傳送給浏覽器的一片資料,WEB伺服器傳送給各個用戶端浏覽器的資料是可以各不相同的。
一旦WEB浏覽器儲存了某個Cookie,那麼它在以後每次通路該WEB伺服器時,都應在HTTP請求頭中将這個Cookie回傳給WEB伺服器。
Session技術是一種将會話狀态儲存在伺服器端的技術 ,它可以比喻成是醫院發放給病人的病曆卡和醫院為每個病人保留的病曆檔案的結合方式 。
用戶端需要接收、記憶和回送 Session的會話辨別号,Session可以且通常是借助Cookie來傳遞會話辨別号。
cookie 和session 都為了實作 http 的短期的持久化(記憶體/緩存方式,查詢快、效率比較高)
兩者對比: cookie 省伺服器性能而 session 更安全
4. HTTP 版本
- HTTP 0.9:己過時。隻接受 GET 一種請求方法,沒有通信中指定版本号,且不支援請求頭。
- HTTP 1.0:這是第一個在通信中指定版本号的 HTTP 協定版本,至今仍被廣泛采用,特别是在代理伺服器中。
- HTTP 1.1:目前版本。持久連接配接被預設采用,并能很好地配合代理伺服器工作;還支援以管道形式同時發送多個請求,以便降低線路負載,提高傳輸速度。
- HTTP 2.0:HTTP2.0是 HTTP 協定自1999年HTTP1.1釋出後的首個更新,大幅度的提高了web性能,在HTTP1.1完全語義相容的基礎上,進一步減少了網絡的延遲,實作低延遲高吞吐量。
HTTP1.0 和 HTTP1.1 之間差別:
① 緩存處理
在HTTP1.0中主要使用header裡的If-Modified-Since,Expires來做為緩存判斷的标準,HTTP1.1則引入了更多的緩存控制政策例如Entitytag,If-Unmodified-Since,If-Match,If-None-Match等更多可供選擇的緩存頭來控制緩存政策。
② 帶寬優化及網絡連接配接的使用
HTTP1.0中,存在一些浪費帶寬的現象,例如用戶端隻是需要某個對象的一部分,而伺服器卻将整個對象送過來了,并且不支援斷點續傳功能,HTTP1.1則在請求頭引入了range頭域,它允許隻請求資源的某個部分,即傳回碼是206 (PartialContent),這樣就友善了開發者自由的選擇以便于充分利用帶寬和連接配接
③ 錯誤通知的管理
在HTTP1.1中新增了24個錯誤狀态響應碼,如409(Conflict)表示請求的資源與資源的目前狀态發生沖突;410(Gone)表示伺服器上的某個資源被永久性的删除
④ HOST域
在HTTP1.0中認為每台伺服器都綁定一個唯一的IP位址,是以,請求消息中的URL并沒有傳遞主機名,HTTP1.0沒有host域。随着虛拟主機技術的發展,在一台實體伺服器上可以存在多個虛拟主機(Multi-homed Web Servers),并且它們共享一個IP位址。HTTP1.1的請求消息和響應消息都支援host域,且請求消息中如果沒有host域會報告一個錯誤(400 Bad Request)。
⑤ 長連接配接
1.0隻能一次性的聯系,1.1支援保持活躍狀态的連接配接方式,即長連結;
HTTP 1.1支援長連接配接(PersistentConnection)和請求的流水線(Pipelining)處理,在一個TCP連接配接上可以傳送多個HTTP請求和響應,減少了建立和關閉連接配接的消耗和延遲,在HTTP1.1中預設開啟Connection(保持): keep-alive(存活),一定程度上彌補了HTTP1.0每次請求都要建立連接配接的缺點
5. HTTP 方法
- HTTP 支援幾種不同的請求指令,這些指令被稱為 HTTP 方法,每條 HTTP 請求封包都包含一個方法,告訴伺服器要執行什麼動作,包括擷取一個頁面、允許一個網關程式、删除一個檔案等。
- 其中,最常用的方法是 GET、POST,如下:
| 方法 | 描述 |
|---|---|
| GET | 請求擷取Request-URI 所辨別的資源 |
| PUT | 請求伺服器存儲一個資源,并用Request-URI作為其辨別 |
| DELETE | 請求伺服器删除 Request-URI所辨別的資源 |
| POST | 在Request-URI所辨別的資源後附加新的資料 |
| HEAD | 請求擷取由 Request-URI所辨別的資源的響應消息報頭 |
- GET 和 POST 方法比較
① 語義上的差別:
Get向伺服器請求資料,依照HTTP協定,get是用來請求資料。
Post向伺服器發資料,依照HTTP協定,Post的語義是向伺服器添加資料,也就是說按照post的語義,該操作是會修改伺服器上的資料
② 伺服器請求的差別:
Get請求是可以被緩存,比如通路百度,通路的方式就是GET,此時通路後的内容會緩被存在浏覽器中,短時間再次通路,其實是拿到的浏覽器中的緩存内容另外Get請求隻能接收ASCII碼的回複。
Post請求是不可以被緩存的。對于Post方式送出表單,重新整理頁面浏覽器會彈出提示框 “是否重新送出表單”,Post可以接收二進制等各種資料形式,是以如果要上傳檔案一般用Post請求
③ 參數放請求頭和請求體的差别:
Get請求通常沒有請求體,在Tce傳輸中隻需傳輸一次(而不是一個包),是以Get請求效率相對高。
Post請求将資料放在請求體中,而實際傳輸中,會先傳輸完請求頭,再傳輸請求體,是分為兩次傳輸的(而不是兩個包),Post請求頭會比get更小(一般不帶參數),請求頭更容易在一個TCP包中完成傳輸,更何況請求頭中有content-Length的辨別,可以更好地保證 HTTP 包的完整性。
| \ | GET 方法 | POST 方法 |
|---|---|---|
| 對資料長度的限制 | URL 的長度是受限制的(URL 的最大長度是2048個字元) | 無限制 |
| 緩存 | 能被緩存 | 不能被緩存 |
| 安全性 | 與POST相比, GET的安全性較差,因為所發送的資料是URL的一部分。在發送密碼或其他敏感資訊時絕不要使用GET | POST比GET更安全,因為參數不會被儲存在浏覽器曆史或Web伺服器日志中 |
| 曆史 | 參數保留在浏覽器曆史中 | 參數不會儲存在浏覽器曆史中 |
| 後退按鈕/重新整理 | 無害 | 資料會被重新送出(浏覽器應該告知使用者資料會被重新送出) |
| 書簽 | 可收藏為書簽 | 不可收藏為書簽 |
6. HTTP 狀态碼
- HTTP 狀态碼(HTTP Status Code)是用以表示網頁伺服器 HTTP 響應狀态的3位數字代碼,當浏覽器請求某一URL 時,伺服器會根據處理情況傳回相應的處理狀态。
- HTTP狀态碼可以分為五大類,如下表所示,其中2XX、3XX表示請求正常,4XX、5XX表示出現異常情況。
| 狀态碼首位 | 已定義範圍 | 分類 |
|---|---|---|
| 1xx | 100-101 | 資訊提示 |
| 2xx | 200-206 | 成功 |
| 3xx | 300-305 | 重定向 |
| 4xx | 400-415 | 用戶端錯誤 |
| 5xx | 500-505 | 伺服器錯誤 |
- 生産環境常見的狀态碼如下所示
| 消息 | 描述 |
|---|---|
| 200 OK | 請求成功(其後是對GET和POST 請求的應答文檔) |
| 301 Moved Permanently | 請求的永久頁面跳轉 |
| 403 Forbidden | 禁止通路該頁面 |
| 404 Not Found | 伺服器無法找到被請求的頁面 |
| 500 Internal Server Error | 内部伺服器錯誤 |
| 502 Bad Gateway | 無效網關 |
| 503 Service Unavailable | 目前服務不可用 |
| 504 Gateway Timeout | 網關請求逾時 |
總結
- POST 和 GET 方法在緩存、安全性、長度限制等方面各有不同
- HTTP 協定請求響應以封包形式傳遞