什麼是神經網絡?
人工神經網絡最初是由研究人員開發的,他們試圖模仿人腦的神經生理學。通過将許多簡單的計算元素(神經元或單元)組合成高度互連的系統,這些研究人員希望産生諸如智能之類的複雜現象。神經網絡是一類靈活的非線性回歸,判别模型。通過檢測資料中複雜的非線性關系,神經網絡可以幫助做出有關實際問題的預測。
神經網絡對于存在以下條件的預測問題特别有用:
- 尚無将輸入與輸出相關的數學公式。
- 預測模型比解釋模型更重要。
- 有很多訓練資料。
神經網絡的常見應用包括信用風險評估,營銷和銷售預測。
neuralNet
基于多層感覺器(MLP),具有以下特征:
- 有任意數量的輸入
- 在隐藏層和輸出層中使用線性組合函數
- 在隐藏層中使用S型激活函數
- 具有一個或多個包含任意數量機關的隐藏層
使用神經網絡函數
該
neuralNet
通過最小化的目标函數訓練網絡。
開發神經網絡時,需要做出許多參數選擇:要使用的輸入數量,要使用的基本網絡體系結構,要使用的隐藏層數量,每個隐藏層的機關數量,要使用的激活函數使用等等。
您可能根本不需要任何隐藏層。線性模型和廣義線性模型可用于多種應用。而且,即使要學習的函數是輕微的非線性,如果資料太少或噪聲太大而無法準确估計非線性,使用簡單的線性模型也可能會比使用複雜的非線性模型獲得更好的效果。最簡單的方法是從沒有隐藏單元的網絡開始,然後一次添加一個隐藏單元。然後估計每個網絡的誤差。當誤差增加時,停止添加隐藏的機關。
如果有足夠的資料,足夠多的隐藏單元和足夠的訓練時間,則隻有一個隐藏層的MLP可以學習到幾乎任何函數的準确性。
生成神經網絡模型的獨立SAS評分代碼
訓練和驗證神經網絡模型後,可以使用該模型對新資料進行評分。可以通過多種方式對新資料進行評分。一種方法是送出新資料,然後運作模型,通過SAS Enterprise Miner或SAS Visual Data Mining and Machine Learning使用資料挖掘來對資料進行評分,以生成評分輸出。
本示例說明如何使用
neuralNet
操作為ANN模型生成獨立的SAS評分代碼。SAS評分代碼可以在沒有SAS Enterprise Miner許可證的SAS環境中運作。
建立和訓練神經網絡
annTrain
将建立并訓練一個人工神經網絡(ANN),用于分類,回歸的函數。
本示例使用
Iris
資料集建立多層感覺器(MLP)神經網絡。Fisher(1936)發表的
Iris
資料包含150個觀測值。萼片長度,萼片寬度,花瓣長度和花瓣寬度以毫米為機關測量從各三個物種50個标本。四種測量類型成為輸入變量。種類名稱成為名義目标變量。目的是通過測量其花瓣和萼片尺寸來預測鸢尾花的種類。
您可以通過以下DATA步驟來将資料集加載到會話中。
- data mycas.iris;
- set sashelp.iris;
- run;
Iris
資料中沒有缺失值。這是很重要的,因為
annTrain
操作将從模型訓練中剔除包含缺失資料的觀察值。如果要用于神經網絡分析的輸入資料包含大量缺失值的觀測值,則應在執行模型訓練之前替換或估算缺失值。因為
Iris
資料不包含任何缺失值,是以該示例不執行變量替換。
該示例使用
annTrain
來建立和訓練神經網絡。神經網絡根據其萼片和花瓣的長度和寬度(以毫米為機關)的輸入來預測預測鸢尾花種類的函數。
1.
2.
3. target="species"
4. inputs={"sepallength","sepalwidth","petallength","petalwidth"}
5. nominals={"species"}
6. hiddens={2}
7. maxiter=1000
8. seed=12345
9. randDist="UNIFORM"
10. scaleInit=1
11. combs={"LINEAR"}
12. targetAct="SOFTMAX"
13. errorFunc="ENTROPY"
14. std="MIDRANGE"
15. validTable=vldTable - 使用
sampling.Stratified
Iris
Species
- 将分區訓示列添加
_Partind_
_Partind_
- 建立一個由30%的表觀察值組成的采樣分區
Species
- 指定
12345
- 命名
sampling_stratified
iris_partitioned
iris_partitioned
- 在源表中指定所有變量,将其傳輸到采樣的表中。
- 使用新添加的分區列中的資料建立單獨的表,以進行神經網絡訓練和驗證。令訓練表
trnTable
iris_partitioned
_Partind_
- 使用新添加的分區列中的資料建立單獨的表,進行神經網絡訓練和驗證。假設驗證表
vldTable
iris_partitioned
_Partind_
-
annTrain
trnTable
Species
- 指定四個輸入變量用作ANN分析的分析變量。
- 要求将目标變量
Species
- 為神經網絡前饋模型中的每個隐藏層指定隐藏神經元的數量。例如,
hiddens={2}
- 指定在尋求目标函數收斂時要執行的最大疊代次數。
- 指定用于執行采樣和分區任務的随機種子。
- 要求将UNIFORM分布用于随機生成初始神經網絡連接配接權重。
- 指定連接配接權重的比例因子,該比例是相對于上一層中的機關數的。
scaleInit
scaleInit
- 為每個隐藏層中的神經元指定LINEAR組合函數。
- 在輸出層中為神經元指定激活函數。預設情況下,SOFTMAX函數用于名義變量。
- 指定誤差函數來訓練網絡。ENTROPY是名義目标的預設設定。
- 指定要在區間變量上使用的标準化。當
std
- 指定要用于驗證表的輸入表名稱。這樣可以通過使用
optmlOpt
- 指定
Nnet_train_model
- 啟用神經算法求解器優化工具。
- 指定250次最大疊代以進行優化,并指定1E–10作為目标函數的門檻值停止值。
- 啟用LBFGS算法。LBFGS是準牛頓方法族中的一種優化算法,它通過使用有限的計算機記憶體來近似Broyden-Fletcher-Goldfarb-Shanno(BFGS)算法。
- 使用頻率參數來設定驗證選項。當
frequency
frequency
輸出顯示資料的概述。
輸出:列資訊
來自table.columnInfo的結果
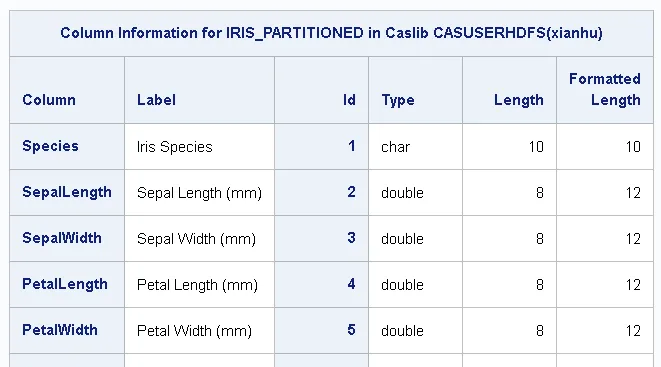
如果在輸入表上使用
table.fetch
指令,則可以檢視輸出2中顯示的示例資料行 。
輸出2:已提取的行
來自table.fetch的結果

如果
simple.freq
在輸入表上使用指令,則可以驗證三種種類中每種都有50個觀測值,輸入資料表中總共有150個觀測值,如輸出3所示。
輸出 3:物種頻率
來自simple.freq的結果
Iris
通過成功完成輸入表的
neuralNet.annTrain
訓練過程後 ,結果将顯示訓練資料疊代曆史記錄,其中包含目标函數,損失和驗證誤差列,如 輸出4中所示。
輸出 4:優化疊代曆史記錄
來自NeuroNet.annTrain的結果
在“疊代曆史記錄”表下方,您應該看到“收斂狀态”表。對于成功的神經網絡模型,“收斂狀态”應報告“優化已收斂”,如 輸出 5中所示。
輸出 5:收斂狀态
成功的模型訓練包括輸出模型的摘要結果,如輸出 6所示 。
輸出 6:模型資訊
這些結果重申了關鍵的模型建構因素,例如模型類型;目标變量 神經網絡模型輸入,隐藏和輸出節點的摘要;權重和偏差參數;最終目标值;以及評分驗證資料集的誤分類誤差。
在表格底部,您将看到由驗證資料确定的最終誤分類錯誤百分比。如果将這個神經網絡模型用作預測函數,并且您的資料來自與
Iris
驗證表具有相同資料分布,則 可以預期93%–94%的物種預測是正确的。
使用神經網絡模型對輸入資料進行評分
訓練和驗證神經網絡模型後,可以使用該模型對新資料進行評分。最常見的技術是通過SAS Enterprise Miner或SAS Visual Data Mining and Machine Learning使用資料挖掘環境來生成評分輸出,進而送出新資料并運作模型以對新資料評分。
擁有訓練的神經網絡後,可以使用該神經網絡模型和
annScore
操作對新的輸入資料進行評分,如下所示:
- table=vldTable
- modelTable="train_model";
- 識别訓練資料表。訓練資料是
iris_partitioned
_partind_
- 确認驗證資料表。驗證資料是
iris_partitioned
_partind_
- 對訓練資料進行評分。送出輸入資料,該 資料将由經過訓練的神經網絡模型評分。因為在此代碼塊中要評分的資料是模型訓練資料,是以您應該期望評分代碼讀取所有105個觀察值,并以0%錯誤分類錯誤預測目标變量值。模型訓練資料包含已知的目标值,是以,在對模型訓練資料進行評分時,應期望其分類錯誤為0%。
- 對驗證資料評分。該操作将送出輸入資料,在SAS資料挖掘環境中,由經過訓練的神經網絡模型對輸入資料進行評分。驗證資料包含已知目标值,但訓練算法不會讀取驗證資料。算法預測驗證資料中每個觀察值的目标值,然後将預測值與已知值進行比較。分類誤差百分比是通過從1中減去正确預測的分類百分比來計算的。較低的分類誤差百分比通常表示模型性能更好。
驗證資料包含30%的原始輸入資料觀察值,并按目标變量
Species
分層 。原始資料包含每個種類的50個觀察值;驗證資料(30%)包含三種物種中每一種的比例15個觀測值,總共45個觀測值。如果驗證資料中的45個觀察值中有42個被正确分類,則該模型的錯誤分類誤差為6.67%。