1.字首碼
在一個字元集中,任何一個字元的編碼都不是另一個字元編碼的字首,即字首碼。例如,有兩個碼字111與1111,那麼這兩個碼字就不符合字首碼的規則,因為111是1111的字首。放到二叉樹裡來講,隻用葉子節點編碼的碼字才是字首碼,如果同時使用中間節點和葉子節點編碼,那結果就不是字首碼。因為壓縮中經過編碼的碼字全部是字首碼,是以在對照碼表解壓的時候,碰到哪個碼字就是哪個碼字,不用擔心出現某個字元的編碼是另一個字元的編碼的字首的情況,該意識一定要具備。
關于字首碼,下面一段話摘自《算法導論》:“字首碼的作用是簡化解碼過程。由于沒有碼字是其他碼字的字首,編碼檔案的開始碼字是無歧義的。我們可以簡單的識别出開始碼字,将其轉換會原字元,然後對編碼檔案剩餘部分重複這種解碼過程。”
2.原始哈夫曼編碼
哈夫曼設計了一個貪心算法來構造最優字首碼,被稱為哈夫曼編碼(Huffman code),其正确性證明依賴于貪心選擇性質和最優子結構。哈夫曼編碼可以很有效的壓縮資料,具體壓縮率依賴于資料本身的特性。這裡我們先介紹幾個概念:碼字、碼字長度、定長編碼與變長編碼。
每個字元可以用一個唯一的二進制串表示,這個二進制串稱為這個字元的碼字,這個二進制串的長度稱為這個碼字的碼字長度。碼字長度固定就是定長編碼,碼字長度不同則為變長編碼。變長編碼可以達到比定長編碼好得多的壓縮率,其思想是賦予高頻字元(出現頻率高的字元)短(碼字長度較短)碼字,賦予低頻字元長碼字。例如,我們用ASCII字元編輯一個文本文檔,不論字元在整個文檔中出現的頻率,每個字元都要占用一個位元組;如果我們使用變長編碼的方式,每個字元因在整個文檔中的出現頻率不同導緻碼字長度不同,有的可能占用一個位元組,而有的可能隻占用一比特,這個時候,整個文檔占用空間就會比較小了。當然,如果這個文本文檔相當大,導緻每個字元的出現頻率基本相同,那麼此時所謂變長編碼在壓縮方面的優勢就基本不存在了(這點要十分明确,這是為什麼壓縮要分塊的原因之一,後續源碼分析會詳細講解)。
哈夫曼編碼會自底向上構造出一棵對應最優編碼的二叉樹,我們使用下面這個例子來說明哈夫曼樹的構造過程。首先,我們已知在某個文本中有如下字元及其出現頻率,
| 字元 | a | b | c | d | e | f |
| 出現頻率 | 45 | 13 | 12 | 16 | 9 | 5 |
構造過程如下圖所示:
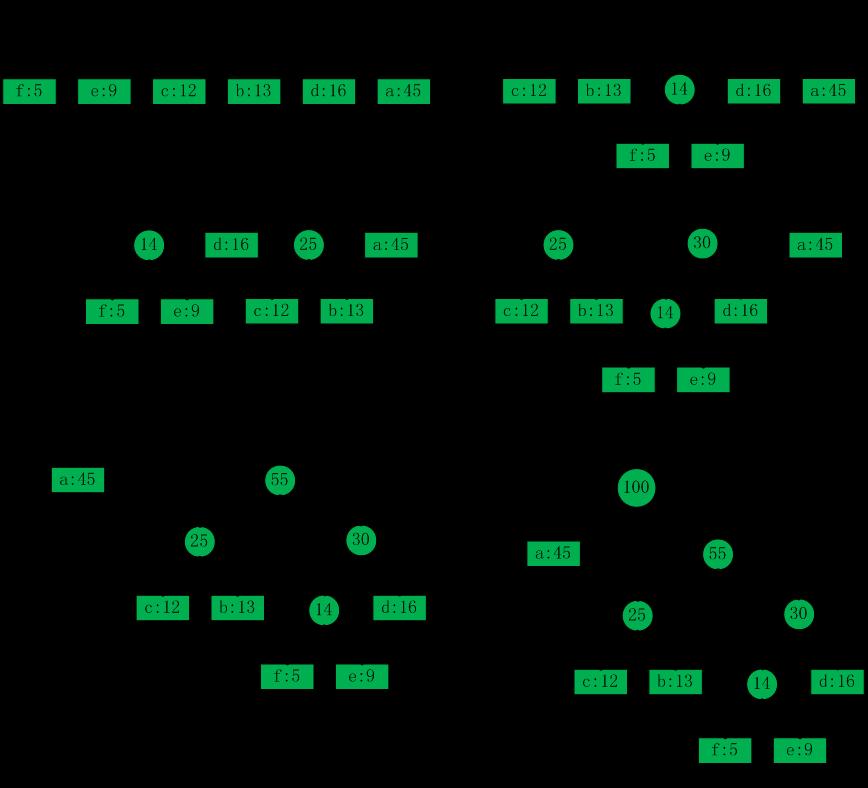
圖1到圖6列除了整個哈夫曼樹構造過程中的每個步驟。在一開始,每個字元都已經按照出現頻率大小排好順序,在後續的步驟中,每次都将頻率最低的兩棵樹合并,然後用合并後的結果再次排序(注意,排序不是目的,目的是找到這時出現頻率最低的兩項,以便下次合并。gzip源碼中并沒有專門去“排序”,而是使用專門的資料結構把頻率最低的兩項找到即可)。葉子節點用矩形表示,每個葉子節點包含一個字元及其頻率。中間節點用圓圈表示,包含其孩子節點的頻率之和。中間節點指向左孩子的邊标記為0,指向右孩子的邊标記為1。一個字元的碼字對應從根到其葉節點的路徑上的邊的标簽序列。圖1為初始集合,有六個節點,每個節點對應一個字元;圖2到圖5為中間步驟,圖6為最終哈夫曼樹。此時每個字元的編碼都是字首碼。
3.Deflate所用的哈夫曼編碼的性質
哈夫曼編碼使用的資料結構就是二叉樹。這裡介紹一些閱讀gzip源碼時需要使用的一些哈夫曼樹的性質,注意,deflate算法使用的哈夫曼樹在原始哈夫曼樹的基礎上增加了一些獨特的性質,專門為壓縮/解壓縮服務。本章隻要了解這些性質并記住這裡提出的問題即可。上文所述是原始哈夫曼樹,與壓縮使用的哈夫曼樹還有一些差別。這部分内容主要參考部落格http://blog.csdn.net/imquestion/article/details/16439,還有一部分是我自己總結的。我們參看下圖來驗證這些性質,注意:碼字長度就是樹的深度,

a. 如果有n個葉子節點,那麼整棵樹的總節點個數為2n-1。以上圖為例,有6個葉子節點,而總節點共有11個。注意,這個地方與gzip源碼中幾個數組的定義不同,源碼中是2n+1,原因後續分析,這裡提一下,後續分析時要留心;
b. 整棵樹最左邊葉子節點的碼字為0(碼字長度視情況而定);
c. 碼字長度相同(即樹深相同)的葉子節點,它們的碼字是連續的,而且右面的總比左面的大1。從上圖中可以看出,c、b、d節點在同一層,c的碼字為100,b的碼字為101,符合該性質,但是d的碼字為111,不符合該性質。如果能将d節點與14節點交換,那就符合該性質了。實際上,這就是deflate中所用哈夫曼編碼與原始哈夫曼編碼不同的地方,前者建構哈夫曼樹的過程在後者的建構上增加了一些條件。這個地方留作一個問題,我們後續分析源碼時詳細讨論,這裡要留心。
此時我們已經初步看到deflate中所用哈夫曼編碼與原始哈夫曼編碼的不同,現在我們使用一棵deflate中所用的标準的哈夫曼樹來分析以下的性質,如下圖所示
d. 樹深為(n+1)時,該層最左面的葉子節點(即本層碼字值最小的那個葉子節點)的值為,樹深為n時,n層最右面的葉子節點(即這一層碼字值最大的葉子節點)的值+1,并且要變長一位(即左移一位)。以上圖為例,i的碼字是01,f的碼字是100,符合該性質;a的碼字是11100,但是a的上一層沒有葉子節點,不能用該性質?我們先接着看下面的性質;
e. 樹深為n這層,最右面的葉子節點(即該層碼字值最大的葉子節點)的值為最左面的葉子節點的值(即該層碼字值最小的葉子節點)加上該層所含葉子節點的個數減一。以上圖為例,f的碼字是100,e的碼字是110,該層共有葉子節點三個,符合該性質;a的碼字為11100,d的碼字為11111,該層共有葉子節點四個,符合該性質;
f. 前兩條性質可以合成本條性質,即,樹深為(n+1)時,該層最左面的葉子節點的值為,樹深為n的這一層最左面的葉子節點的值加上該層所有葉子節點的個數,然後變長一位(即左移一位)。以上圖為例,h的碼字為00,改層有葉子節點兩個,f的碼字為100,是以00+10(2的二進制表示)=10,将10左移一位就是100,即f,符合該性質。實際上,該性質在源碼中對應的代碼就是code = (code + bl_count[bits-1])<< 1,後面我們詳細分析這句話。看到這裡,上面第四條性質的問題就可以解決了,f的碼字是100,f所在的這層有三個葉子節點,那麼再往下一層,這層沒有葉子節點,但是我們可以假設一個不存在的葉子節點,這個不存在的葉子節點的編碼要用f去計算,即,code = (100+11)<<1,11就是二進制的3,是以code就是1110,即這個不存在的葉子節點的編碼就是1110,用它去計算a,繼續套用這個公式,code = (1110+0)<<1,是以code就是11100,與性質是符合的!!!
g. 節點n的左子節點是2n,右子節點是2n+1;
其實deflate中使用的哈夫曼編碼就是“範式哈夫曼編碼”,範式哈夫曼編碼的相關介紹如下:“範式哈夫曼編碼最早由Schwartz提出,它是哈夫曼編碼的一個子集。其中心思想是使用某些強制的約定,僅通過很少的資料便能重構出哈夫曼編碼樹的結構。其中一種很重要的約定是數字序列屬性(numerical sequence property),它要求相同長度的碼字是連續整數的二進制描述。例如,假設碼字長度為4的最小值為0010,那麼其它長度為4的碼字必為0011, 0100, 0101, ...;另一個約定:為了盡可能的利用編碼空間,長度為i第一個碼字f(i)能從長度為i-1的最後一個碼字得出, 即:f(i) = 2(f(i-1)+1)。假定長度為4的最後一個碼字為1001,那麼長度為5的第一個碼字便為10100。最後一個約定:碼字長度最小的第一個編碼從0開始。通過上述約定,解碼器能根據每個碼字的長度恢複出整棵哈夫曼編碼樹的結構。”從上面的性質可以看出,我們這裡使用的就是範式哈夫曼編碼。