#1014 : Trie樹
10000ms
1000ms
256MB
描述
小Hi和小Ho是一對好朋友,出生在資訊化社會的他們對程式設計産生了莫大的興趣,他們約定好互相幫助,在程式設計的學習道路上一同前進。
這一天,他們遇到了一本詞典,于是小Hi就向小Ho提出了那個經典的問題:“小Ho,你能不能對于每一個我給出的字元串,都在這個詞典裡面找到以這個字元串開頭的所有單詞呢?”
身經百戰的小Ho答道:“怎麼會不能呢!你每給我一個字元串,我就依次周遊詞典裡的所有單詞,檢查你給我的字元串是不是這個單詞的字首不就是了?”
小Hi笑道:“你啊,還是太年輕了!~假設這本詞典裡有10萬個單詞,我詢問你一萬次,你得要算到哪年哪月去?”
小Ho低頭算了一算,看着那一堆堆的0,頓時感覺自己這輩子都要花在上面了...
小Hi看着小Ho的囧樣,也是繼續笑道:“讓我來提高一下你的知識水準吧~你知道樹這樣一種資料結構麼?”
小Ho想了想,說道:“知道~它是一種基礎的資料結構,就像這裡說的一樣!”
小Hi滿意的點了點頭,說道:“那你知道我怎麼樣用一棵樹來表示整個詞典麼?”
小Ho搖搖頭表示自己不清楚。
小Hi于是在紙上畫了一會,遞給小Ho,道:“你看這棵樹和這個詞典有什麼關系?”
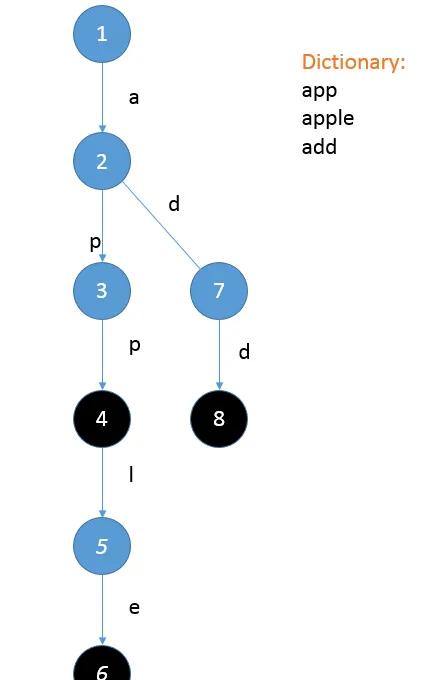
小Ho盯着手裡的紙想了一會道:“我知道了!對于從樹的根節點走到每一個黑色節點所經過的路徑,如果将路徑上的字母都連起來的話,就都對應着詞典中的一個單詞呢!”
小Hi說道:“那你知道如何根據一個詞典建構這樣一棵樹麼?”
“不造!”
“想你也不知道,我來告訴你吧~”小Hi擺出一副老師的樣子,說道:“你先這麼想,如果我已經有了這樣的一個詞典和對應的一棵樹,我要添加一個新的單詞apart,我應該怎麼做?”
“讓我想想……”小Ho又開始苦思冥想:“首先我要先看看已經能走到哪一步了對吧?比如我從1号節點走"a"這一條邊就可以走到2号節點,然後從2号節點走"p"這一條邊可以走到3号節點,然後……就沒路可走了!這時候我就需要添加一條從3号節點出發且标記為"p"的邊才可以接着往下走……最後就是這樣了!然後我把最後到達的這個結點标記為黑色就可以了。”

小Hi說道:“真聰明~那你不妨再算算如果是一個有10W個單詞的詞典,每個單詞的長度不超過10的話,這棵樹會有多大?”
小Ho于是掏出筆來,一邊畫一遍念叨:“假設我已經将前三個單詞構成了這樣一棵樹,那麼我要添加一個新的單詞的時候,最壞情況是這個單詞和之前的三個單詞都沒有公共字首,那麼這個新的單詞的長度如果是5的話,我就至少要添加5個結點到樹中才能夠繼續表示這個詞典!”
“而如果每次都是最壞情況的話,這棵樹最多也就100W個結點這麼大!更何況最壞情況是不可能次次都發生的!畢竟字母表也才26個字母呢!”小Ho繼續說道。
“嗯~這樣我們是不是就可以用(單詞個數*單詞長度)個結點來表示一個詞典了呢?小Hi問道。
“是的呢!”小Ho道:“但是這樣一棵樹又有什麼用呢?”
“可别小看了它,它就是傳說中的Trie樹哦~至于他有什麼用,一會你就知道了!”小Hi笑嘻嘻的回答道。
“你看,我們現在得到了這樣一棵樹,那麼你看,如果我給你一個字元串ap,你要怎麼找到所有以ap開頭的單詞呢?”小Hi又開始考校小Ho。
“唔...一個個周遊所有的單詞?”小Ho還是不忘自己最開始提出來的算法。
“笨!這棵樹難道就白建構了!”小Hi教訓完小Ho,繼續道:“看好了!”
小Hi在樹上用綠色标出了一個節點,遞給小Ho。
“這個結點……是從根節點先走"a"然後走"p"到達的結點呢!哦~~我知道了,以這個結點為根的子樹裡所有标記結點都是以"ap"為字首的單詞呢!而且所有以"ap"為字首的單詞都在以這個節點為根的子樹裡~”小Ho驚喜道。
“是的呢~那你對怎麼解決我的問題有想法了麼?”小Hi追問道。
“唔...那就是每次拿到你的字元串之後,我在樹上找到其對應的那個結點,然後統計這個節點中有多少個标記節點?”小Ho不是很确定的答道:“但是這樣...似乎在最壞情況,也就是你每次給個字元串都很短的時候,我還是要掃描這棵樹的很大一部分呢?也就是說雖然平均時間複雜度降低了,但是最壞情況時間複雜度還是很高的樣子!”
小Hi笑嘻嘻道:”沒想到你自己看出來了呢~我還以為又要教訓你了!~那你有什麼好的解決方法麼?”
“沒呢!小Hi你就别賣關子了,趕緊告訴我吧!”被折磨的夠嗆的小Ho開始求饒。
“好吧!就幫你這一回~”
“小Ho你有沒有想過這樣一個問題?不妨稱以T為根的子樹中标記節點的個數為L[T],既然我要統計某個L[T1],,而這個結點是不确定的,我有沒有辦法一次性把所有結點的L[T]求出來呢?”小Hi整理了下思緒,問道。
“似乎是有的,老師以前說過,遞歸什麼的。。”小Ho答道。
“遞歸太複雜了!我們可以之後再說,你這麼想,在你建構Trie樹的時候,當你經過一個結點的時候,說明了什麼?”小Hi撇了撇頭,繼續問道。
“我想想,經過一個結點……标記結點……說明了以這個結點為根的子樹中将要多出來一個标記結點?”
“沒錯!那你有沒有什麼辦法來記錄這個改變呢?”
“我想想,我在最開始置所有L[T]=0,然後每次添加一個新的單詞的時候,都将它經過的所有結點的L[T]全部+1,這樣我建構完這棵Trie樹的時候,我也就能夠同時統計到所有L[T]了,對麼?”小Ho開心道。
“那麼現在!趕緊去用代碼實作吧!”小Hi如是說道
輸入
輸入的第一行為一個正整數n,表示詞典的大小,其後n行,每一行一個單詞(不保證是英文單詞,也有可能是火星文單詞哦),單詞由不超過10個的小寫英文字母組成,可能存在相同的單詞,此時應将其視作不同的單詞。接下來的一行為一個正整數m,表示小Hi詢問的次數,其後m行,每一行一個字元串,該字元串由不超過10個的小寫英文字母組成,表示小Hi的一個詢問。
在20%的資料中n, m<=10,詞典的字母表大小<=2.
在60%的資料中n, m<=1000,詞典的字母表大小<=5.
在100%的資料中n, m<=100000,詞典的字母表大小<=26.
本題按通過的資料量排名哦~
輸出
對于小Hi的每一個詢問,輸出一個整數Ans,表示詞典中以小Hi給出的字元串為字首的單詞的個數。
樣例輸入
5
babaab
babbbaaaa
abba
aaaaabaa
babaababb
5
babb
baabaaa
bab
bb
bbabbaab
樣例輸出
1
3
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#define L 10+1
using namespace std;
struct T{
int num;
T* next[26];
T(){
num=0;
int i;
for(i=0;i<26;i++)
next[i]=NULL;
}
}t;
void In(char str[]){
T* p=&t;
for(int i=0;str[i];i++){
int a=str[i]-'a';
if(p->next[a]==NULL)
p->next[a]=new T;
p=p->next[a];
p->num++;
}
}
int find(char str[]){
T* p=&t;
for(int i=0;str[i];i++){
int a=str[i]-'a';
if(p->next[a]==NULL)return 0;
p=p->next[a];
}
return p->num;
}
int main(){
int n,m;
char str[L];
scanf("%d",&n);
while(n--){
scanf("%s",str), In(str);
}
scanf("%d",&m);
while(m--){
scanf("%s",str);
printf("%d\n",find(str));
}
return 0;
}