2020年 6 月 25 日,第一個正式版 YOLOv5由 Ultralytics 釋出。在這篇文章中,我們将讨論第一個YOLOv5版本中部署的新技術,并分析新模型的初步性能結果。
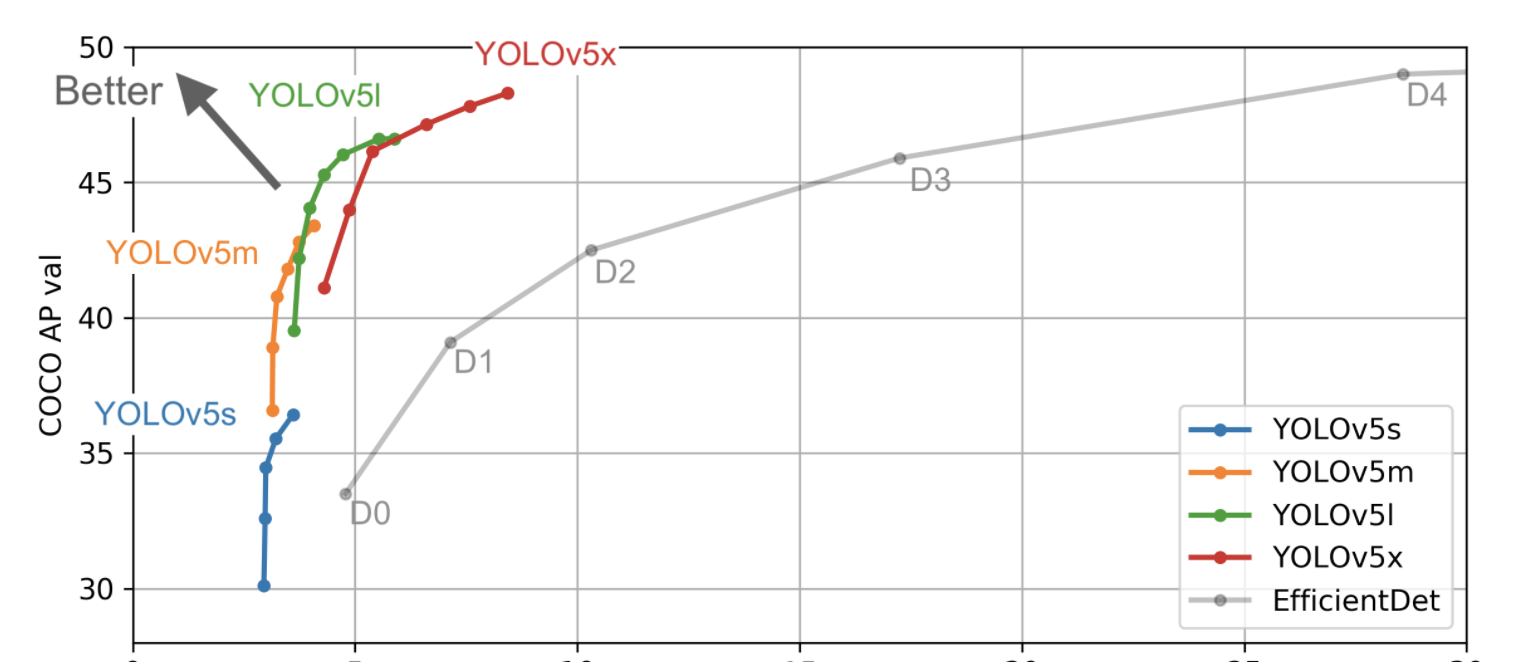
6/25 - YOLOv5 的初始版本顯示了最先進的對象檢測的前景(引用 YOLOv5 存儲庫)
在圖表中,目标是生成一個相對于其推理時間(X 軸)非常高效(Y 軸)的對象檢測器模型。初步結果表明,相對于其他最先進的技術,YOLOv5 在這方面做得非常好。
總之,YOLOv5 的大部分性能改進來自 PyTorch 訓練過程,而模型架構仍然接近YOLOv4。
在本文中,我們希望解決以下有關 YOLOv5 的一些問題:
- YOLO v5 有什麼新東西?
- YOLO v5 有哪些新技術?
- YOLO v5 與 YOLO v4 相比如何?
- YOLO v4 和 YOLO v5 有什麼不同?
- 我應該使用 YOLO v4 還是 YOLO v5 進行物體檢測?
- YOLO v5 是“真實的”嗎?

Video連結:https://youtu.be/O4jOqVqyAo8
1. YOLOv5 發展曆程
1.1 YOLO 的曆史
要深入了解 YOLO 的曆史,我建議閱讀YOLOv4 的完整細分。簡而言之,YOLO 模型是一種快速緊湊的物體檢測模型,相對于其大小而言性能非常好,并且一直在穩步改進。
1.2 YOLOv3 PyTorch 的擴充
該YOLOv5庫是一個自然延伸YOLOv3 PyTorch庫由格倫Jocher。YOLOv3 PyTorch 存儲庫是開發人員将 YOLOv3 Darknet 權重移植到 PyTorch 然後繼續生産的熱門目的地。許多人(包括我們在 Roboflow 的視覺團隊)喜歡 PyTorch 分支的易用性,并會使用這個出口進行部署。
在完全複制 YOLOv3 的模型架構和訓練過程後,Ultralytics 開始在重新設計存儲庫的同時進行研究改進,目标是使成千上萬的開發人員能夠訓練和部署他們自己的自定義對象檢測器來檢測世界上的任何對象,這是我們在此分享的目标在 Roboflow。
1.3 新的 YOLOv5 存儲庫進展
這些改進最初被稱為 YOLOv4,但由于最近在 Darknet 架構中釋出了 YOLOv4,為了避免版本沖突,它被重命名為 YOLOv5。一開始對 YOLOv5命名有很多争論,我們發表了一篇比較 YOLOv4 和 YOLOv5的文章,您可以在自己的資料上并排運作這兩種模型。我們在本文中避免自定義資料集比較,僅讨論 YOLO 研究人員在 GitHub 讨論中釋出的新技術和名額。
值得注意的是,自從存儲庫釋出以來,YOLOv5 已經發生了重大的研究進展,我們希望繼續進行,并且可能會為 YOLO-“綽号”提供一些理由。
2. YOLO 架構概述
對象檢測器旨在從輸入圖像中建立特征,然後通過預測系統将這些特征提供給對象,以在對象周圍繪制框并預測它們的類别。
物體檢測器的剖析(引文)
YOLO 模型是第一個在端到端可微分網絡中将預測邊界框與類标簽的過程連接配接起來的對象檢測器。
物體檢測過程的另一張圖(引自 YOLOv4)
YOLO 網絡由三個主要部分組成。
- Backbone - 一種卷積神經網絡,以不同的粒度聚合并形成圖像特征。
2)Neck-一系列用于混合群組合圖像特征的層,以将它們傳遞給預測。
- Head -使用頸部的特征并進行框和類别預測步驟。
當然,可以采用多種方法來組合每個主要元件的不同架構。YOLOv4 和 YOLOv5 的貢獻首先是整合了計算機視覺其他領域的突破,并證明作為一個集合,它們改進了 YOLO 對象檢測。
3. YOLO 訓練程式概述
訓練過程對于目标檢測系統的最終性能同樣重要,盡管它們通常很少被讨論。
- 資料增強 -資料增強對基礎訓練資料進行轉換,以将模型暴露在比單獨訓練集更廣泛的語義變化中。
- 損失計算 - YOLO 從組成損失函數 - GIoU、obj 和類損失計算總損失函數。這些可以仔細建構以最大化平均精度的目标。
4. PyTorch 翻譯
YOLOv5 最大的貢獻是将 Darknet 研究架構轉化為 PyTorch 架構。Darknet 架構主要用 C 編寫,對編碼到網絡中的操作提供細粒度的控制。在許多方面,對低級語言的控制對研究來說是一種福音,但它會使新研究見解的移植速度變慢,因為每個新添加的内容都會編寫自定義梯度計算。
在 YOLOv3 中将 Darknet 中的訓練程式翻譯(并超越)到 PyTorch 的過程是不小的壯舉。
5. YOLOv5 中的資料增強
要深入了解資料增強如何改進對象檢測模型,我建議閱讀這篇關于YOLOv4 中資料增強的文章。
這是 YOLOv5 中增強訓練圖像的圖檔。
YOLOv5 中的增強
對于每個訓練批次,YOLOv5 通過資料加載器傳遞訓練資料,該資料加載器線上增加資料。資料加載器進行三種增強:縮放、色彩空間調整和馬賽克增強。其中最新穎的是馬賽克資料增強,它将四個圖像組合成四個随機比例的圖塊。
該鑲嵌資料加載原産于YOLOv3 PyTorch現在YOLOv5回購。
Mosaic 增強對于流行的COCO 對象檢測基準特别有用,可幫助模型學習解決衆所周知的“小對象問題” ——其中小對象的檢測不如大對象準确。
值得注意的是,值得嘗試使用您自己的一系列增強功能來最大限度地提高自定義任務的性能。
6. 自動學習邊界框錨
為了進行框預測,YOLO 網絡将邊界框預測為與錨框尺寸清單的偏差。
(引用 YOLOv3 論文)
在 YOLOv3 PyTorch repo 中,Glenn Jocher 介紹了使用 K-means 和遺傳學習算法基于自定義資料集中邊界框的分布來學習錨框的想法。這對于自定義任務非常重要,因為邊界框大小和位置的分布可能與 COCO 資料集中預設的邊界框錨點有很大不同。
如果我們試圖檢測像非常高而瘦的長頸鹿或非常寬而平坦的蝠鲼之類的東西,則可能會出現錨框的最極端差異。
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
# YOLOv5 backbone
YOLOv5 配置檔案中的錨點現在可以根據訓練資料自動學習。
當您輸入自定義資料時,所有 YOLO 錨框都會在 YOLOv5 中自動學習。
7. 16 位浮點精度
PyTorch 架構允許将訓練和推理中的浮點精度從 32 位精度降低到 16 位精度的一半。這顯着加快了 YOLOv5 模型的推理時間。
但是,這種改進帶來的速度提升目前僅适用于特定 GPU——即 V100 和 T4。也就是說,NVIDIA 已經寫下意圖來擴大他們對這種效率提升的覆寫範圍。
8. 新模型配置檔案
YOLOv5 在 中制定模型配置.yaml,而不是.cfg 暗網中的檔案。這兩種格式的主要差別在于,.yaml檔案被壓縮為僅指定網絡中的不同層,然後将它們乘以塊中的層數。新.yaml格式如下所示:
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 head
head:
[[-1, 3, BottleneckCSP, [1024, False]], # 9
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 18 (P3/8-small)
[-2, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 26 (P5/32-large)
[[], 1, Detect, [nc, anchors]], # Detect(P5, P4, P3)
]
9. CSP骨幹網
YOLOv4 和 YOLOv5 都實作了 CSP Bottleneck 來制定圖像特征 - 研究信用指向WongKinYiu和他們最近關于卷積神經網絡主幹的跨階段部分網絡的論文。CSP 解決了其他較大的 ConvNet 主幹中的重複梯度問題,導緻參數更少,FLOPS 更少,具有可比的重要性。這對 YOLO 家族極其重要,其中推理速度和小模型尺寸至關重要。
CSP 模型基于 DenseNet。DenseNet 旨在連接配接卷積神經網絡中的層,其動機如下:減輕梯度消失問題(很難通過非常深的網絡反向傳播損失信号),支援特征傳播,鼓勵網絡重用特征,并減少網絡參數的數量。
在 CSPResNext50 和 CSPDarknet53 中,DenseNet 已被編輯以通過複制它并通過密集塊發送一個副本并将另一個直接發送到下一階段來分離基礎層的特征圖。CSPResNext50 和 CSPDarknet53 的想法是消除 DenseNet 中的計算瓶頸,并通過傳遞未經編輯的特征圖版本來改進學習。
10. PA-網頸
YOLOv4 和 YOLOv5 都實作了 PA-NET 頸部來進行特征聚合。
上面的每個 P_i 都代表 CSP 主幹中的一個特征層。
上圖來自谷歌大腦對EfficientDet對象檢測架構的研究。EfficientDet 的作者發現 BiFPN 是檢測頸部的最佳選擇,這可能是 YOLOv4 和 YOLOv5 與其他實作一起探索的進一步穩定的領域。
這裡當然值得注意的是,YOLOv5 借用了 YOLOv4 的研究調查來決定其架構的最佳頸部。YOLOv4 研究了最佳 YOLO 琴頸的各種可能性,包括:
- FPN
- PAN
- NAS-FPN
- BiFPN
- ASFF
- SFAM
11. 開發人員的一般生活品質更新
與其他對象檢測架構相比,YOLOv5對于将計算機視覺技術實施到應用程式中的開發人員來說非常容易使用。我将這些生活品質更新分為以下幾類。
- 輕松安裝- YOLOv5 隻需要安裝Torch 和一些輕量級的 Python 庫。
- 快速教育訓練-該YOLOv5模型快速教育訓練極為打造屬于您的模型,有助于削減成本的試驗。
- 有效的推理端口- 您可以使用 YOLOv5 對單個圖像、批處理圖像、視訊源或網絡攝像頭端口進行推理。
- 直覺的布局 - 開發時檔案夾布局直覺且易于導航
- 輕松轉換到移動裝置 -您可以輕松地将 YOLOv5 從 PyTorch 權重轉換為 ONXX 權重,再到 CoreML 到 IOS。
12. 初步評估名額
本節中提供的評估名額是初步的,我們可以期待在研究工作完成并且對 YOLO 模型系列做出更多新貢獻時,将在 YOLOv5 上發表正式的研究論文。也就是說,在研究論文發表之前,為正在考慮使用哪種架構的開發人員提供這些名額很有用。
下面的評估名額基于 COCO 資料集的性能,該資料集包含包含 80 個對象類的廣泛圖像。有關性能名額更詳細,請參閱這篇文章W¯¯帽子地圖。
YOLOv4 官方論文釋出了以下評估名額,它們在 V100 GPU 上的 COCO 資料集上運作他們的訓練網絡:
随着第一個 YOLOv5 V1 模型的初始釋出,YOLOv5 存儲庫釋出了以下内容:
這些圖反轉了 X 軸 - FPS 與 ms/img,但我們可以快速反轉 YOLOv5 軸以估計相同 V100 GPU 上大約 200-300FPS 的 FPS 數字,同時實作更高的 mAP。
同樣重要的是要注意YOLOv4-tiny的新版本,這是暗網存儲庫中一個非常小且性能非常好的模型。
YOLOv4-tiny的評估名額如下:
這意味着它非常快且非常高效。但這裡要注意的重要一點是評估名額是 AP_50 - 這意味着 50% iOU 時的平均精度。考慮到這個更寬松的名額,我們必須與 YOLOv5 的完整表進行比較:
我們可以看到 YOLOv5s(速度和模型大小相似的模型)達到了 55.8 AP_50。
由于 YOLOv4-tiny 模型是在 1080Ti 上評估的,這比 YOLOv5 表中使用的 V100 慢 2 倍,是以這裡的比較稍微複雜一些。
毋庸置疑,将會有更多精确比對的基準測試出現,并且一些正在此 GitHub 問題中進行。WongKinYiu 是上述 CSP 存儲庫的作者和 YOLOv4 的第二作者,提供了可比較的基準。
從這個角度來看,YOLOv4 成為了更優秀的架構。然而值得注意的是,在這個比較中,YOLOv4 在 Ultralytics YOLOv3 存儲庫(不是原生暗網)中進行了訓練,包括 YOLOv5 存儲庫中的大部分訓練增強,顯示了 mAP 的改進。
更多來這裡我相信。
13. 結論
退後一步,現在是從事計算機視覺工作的好時機,其中最先進的技術發展如此迅速。
YOLOv5的初始版本非常快速、高性能且易于使用。雖然 YOLOv5 尚未對 YOLO 模型系列引入新穎的模型架構改進,但它引入了一個新的 PyTorch 訓練和部署架構,改進了對象檢測器的最新技術。此外,YOLOv5 非常使用者友好,可以“開箱即用”地用于自定義對象。
如果您有興趣使用最先進的 YOLO 模型來訓練自定義檢測器,我們鼓勵您在 Google Colab 中檢視以下兩個指南中的任何一個:
- 如何訓練 YOLO v4 教程(在 Darknet Repo 中)
-
如何訓練 YOLO v5 教程(在 Ultralytics Repo 中)
祝你檢測順利!
想要訓練自定義模型?
跳過這篇文章,直接跳到我們的YOLOv5 教程。您将在幾分鐘内在自定義資料上擁有一個經過訓練的 YOLOv5 模型。
參考
https://blog.roboflow.com/yolov5-improvements-and-evaluation/
https://zhuanlan.zhihu.com/p/161083602