文章目錄
- 1. 摘要
- 2. Compaction 概述
- 3. 實作
- 3.1 Prepare keys 過程
- 3.1.1 compaction觸發的條件
- 3.1.2 compaction 的檔案篩選過程
- 3.1.3 compaction每一層level大小的計算過程
- 3.1.4 挑選參與compaction的檔案
- 3.1.5 Compaction job根據擷取到資料配置設定compaction 線程
- 3.2 Process keys
- 3.2.1 構造能夠通路所有key的疊代器
- 3.2.2 通過SeekToFirst和Next指針 處理元素
- 3.3 Write keys
- 3.3.1 将builder與輸出檔案的writer綁定
- 3.3.2 通過table_builder的狀态機添加block資料
- 3.3.3 通過建構的meta_index_builder和Footer完成資料的固化
- 4. Compaction 的一些周邊功能
- 4.1 Remote Compaction
- 4.2 CompactRange
- 4.3 MarkCompaction
- 5. 總結
2022.1.8 第二版本 補充一些 compaction 周邊工具 以及 更多的外部觸發排程政策
2020.9 第一版本 完整實作
1. 摘要
閱讀本文前建議看看Rocksdb Compaction 源碼詳解(一):SST檔案詳細格式源碼解析,先初步了compaction操作的SST檔案結構
Rocksdb的compaction流程可以說是比較核心的流程了,它的存在除了保證不同sst 檔案之間的key-value之間的有序性,資料的壓縮存儲,清理過時資料之外,還需要在存儲細節上做一些優化來進一步提升LSM tree的讀性能(Range tombstone的構造,提升了deleteRange區間的key-value的判斷效率;filter block的建立,提升判斷一個key是否存在的機率;index block的建立,支援二分查找和hash map的查找,提升針對普通key-value的查找性能…)。
雖然LSM tree的順序寫入保證了寫性能,但是其本身的存儲結構卻犧牲了讀性能,是以需要通過compaction這樣的機制随着IO的持續寫入來不斷得微調整 整個資料存儲系統的結構,來降低讀對系統的影響。
本節中涉及的代碼都是基于rocksdb 6.6.fb版本來描述的,閱讀完預計一個多小時,建議大家先概覽,然後選擇部分感興趣的來看,歡迎大家一起交流讨論
2. Compaction 概述
接下來我将帶領大家欣賞這樣一個有趣機制的實作,
rocksdb實作了多種這樣的compaction政策,這裡以預設的level compaction為切入點:
如圖2.1 對compaction的實作做了一個整體的描述,圖有點複雜?這張圖能夠将compaction的大體流程講清楚,但對于其中的一些優化細節的實作還是太過籠統。限于本人能力有限,會在自己能力範圍内為大家講清楚這個機制。
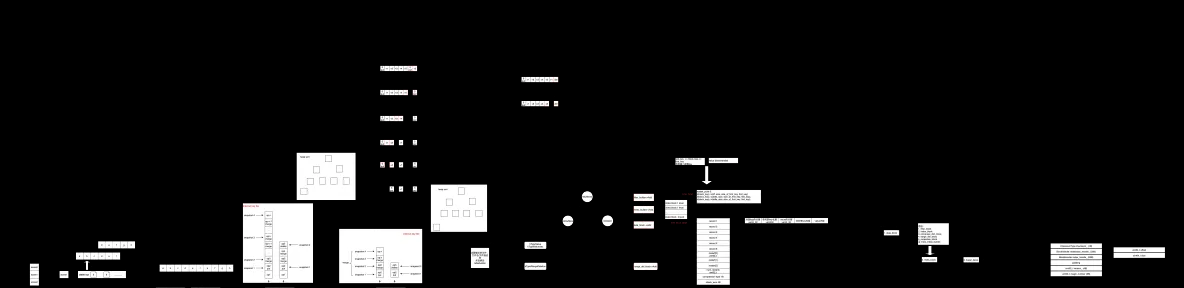
圖2.1 compaction整體流程概述
主要分為三個階段:
- Prepare key,主要是從SST檔案中讀取需要參與compaction的key-value資料
- Process key,主要是進行key value資料的合并,排序,處理不同的key type的操作
- write key,将key-value資料寫入對應的block資料之中
不過其詳細實作并不是三個階段這麼簡單,非常多的細節,看看上面那張籠統概述的圖就知道了。
3. 實作
上圖将整個Compaction的總體過程分為三部分,這個劃分并不是官方的劃分,隻是為了友善大家了解,從代碼中提煉出來的主要邏輯。為了避免篇幅太過冗長,這裡選擇将對應代碼邏輯的calltrace 添加進來,對于有趣的關鍵邏輯再做詳細說明。以下部分到描述 對應上圖中的流程就是從左向右看的三個部分:
3.1 Prepare keys 過程
主要做如下幾件事情:
- 根據每一層的score來 取出參與compaction 層
- 利用clean cut算法來 來從層中取出參與compaction的檔案
- 将檔案中的key-value 邊界取出,并做一個邊界排序,确認最終的key的邊界範圍
- 依據邊界範圍,按照subcompaction limit 拆分成一個一個subcompaction , 建立對應的sub處理的線程,進入下一個階段
大體過程如下 圖3.1

圖3.1 compaction到prepare key 部分
3.1.1 compaction觸發的條件
rocksdb的compaction都是背景運作,通過線程BGWorkCompaction 進行compaction的排程。
該線程的觸發一般有兩種情況
一種是手動compact,
CompactFiles
來進行手動compaction操作
另一種是自動MaybeScheduleFlushOrCompaction,這個函數在切換wal(SwitchWAL)或者write_buffer(memtable)滿的時候被調用。
我們主要還是分析自動compaction的邏輯,這也是通用邏輯。接下來分析
MaybeScheduleFlushOrCompaction
函數中的compact邏輯,這裡可以看到RocksDB中背景運作的compact會有一個限制(max_compactions).而我們可以看到這裡還有一個變量 unscheduled_compactions_,這個變量表示需要被compact的columnfamily的隊列長度.
while (bg_compaction_scheduled_ < bg_job_limits.max_compactions &&
unscheduled_compactions_ > 0) {
CompactionArg* ca = new CompactionArg;
ca->db = this;
ca->prepicked_compaction = nullptr;
bg_compaction_scheduled_++; //正在被排程的compaction線程數目
unscheduled_compactions_--; //待排程的線程個數,及待排程的cfd的長度
//排程BGWorkCompaction線程
env_->Schedule(&DBImpl::BGWorkCompaction, ca, Env::Priority::LOW, this,
&DBImpl::UnscheduleCompactionCallback);
} compact的時候RocksDB也有一個隊列叫做DBImpl::compaction_queue_.
std::deque<ColumnFamilyData*> compaction_queue_; 這個隊列的更新是在函數SchedulePendingCompaction更新的,且unscheduled_compactions_變量是和該函數一起更新的,也就是隻有設定了該變量才能夠正常排程compaction背景線程。
void DBImpl::SchedulePendingCompaction(ColumnFamilyData* cfd) {
if (!cfd->queued_for_compaction() && cfd->NeedsCompaction()) {
AddToCompactionQueue(cfd);
++unscheduled_compactions_;
}
} 上面的核心函數是NeedsCompaction,通過這個函數來判斷是否有sst需要被compact,是以接下來我們就來詳細分析這個函數.當滿足下列幾個條件之一就将會更新compact隊列,通過調用LevelCompactionPicker::NeedsCompaction函數來進行是否滿足compaction的條件判斷的,以下條件隻要滿足一個就可以進行compaction的排程:
- 有逾時的sst(ExpiredTtlFiles)
-
files_marked_for_compaction或者bottommost_files_marked_for_compaction都不為空
兩個vector類型的數組
-
周遊所有的level的sst,然後判斷是否需要compact
這裡通過每個sst的score進行判斷,後續會對該score進行描述
bool LevelCompactionPicker::NeedsCompaction(
const VersionStorageInfo* vstorage) const {
if (!vstorage->ExpiredTtlFiles().empty()) {
return true;
}
if (!vstorage->FilesMarkedForPeriodicCompaction().empty()) {
return true;
}
if (!vstorage->BottommostFilesMarkedForCompaction().empty()) {
return true;
}
if (!vstorage->FilesMarkedForCompaction().empty()) {
return true;
}
for (int i = 0; i <= vstorage->MaxInputLevel(); i++) {
if (vstorage->CompactionScore(i) >= 1) {
return true;
}
}
return false;
} 3.1.2 compaction 的檔案篩選過程
是以接下來我們來分析最核心的CompactionScore,這裡将會涉及到兩個變量,這兩個變量分别儲存了level以及每個level所對應的score(這裡score越高表示compact優先級越高),而score小于1則表示不需要compact.
這裡是通過兩個數組進行相關變量的更新
std::vector<double> compaction_score_; //目前sst的score
std::vector<int> compaction_level_; //目前sst需要被compact到的層level 這兩個變量的更新是在函數void VersionStorageInfo::ComputeCompactionScore中被更新的,這個函數會差別leve-0和其他level的處理邏輯
- 首先會計算level-0下所有檔案的大小(total_size)以及檔案個數(num_sorted_runs).
- 用檔案個數除以level0_file_num_compaction_trigger來得到對應的score
- 針對levelStyle的compaction,需要從上面的score和(total_size/max_bytes_for_level_base)取最大值,作為目前參與compaction的score。因為有的時候level-0在密集型IO場景下會瞬時達到很大,超過level-1的max_bytes_for_level_base,是以需要針對這種場景設定score
void VersionStorageInfo::ComputeCompactionScore(
......
for (int level = 0; level <= MaxInputLevel(); level++) {
double score;
if (level == 0) {
......
int num_sorted_runs = 0;
uint64_t total_size = 0;
for (auto* f : files_[level]) {
if (!f->being_compacted) {
total_size += f->compensated_file_size; //所有level-0檔案總大小
num_sorted_runs++; //所有檔案個數
}
}
......
score = static_cast<double>(num_sorted_runs) /
mutable_cf_options.level0_file_num_compaction_trigger;
if (compaction_style_ == kCompactionStyleLevel && num_levels() > 1) {
// Level-based involves L0->L0 compactions that can lead to oversized
// L0 files. Take into account size as well to avoid later giant
// compactions to the base level.
score = std::max(
score, static_cast<double>(total_size) /
mutable_cf_options.max_bytes_for_level_base);
}
} 針對非level-0的處理邏輯,也是擷取目前level未正在進行compaction的所有檔案大小,然後除以MaxBytesForLevel得到score
// Compute the ratio of current size to size limit.
uint64_t level_bytes_no_compacting = 0;
for (auto f : files_[level]) {
if (!f->being_compacted) {
level_bytes_no_compacting += f->compensated_file_size;
}
}
score = static_cast<double>(level_bytes_no_compacting) /
MaxBytesForLevel(level);
}
compaction_level_[level] = level;
compaction_score_[level] = score; 3.1.3 compaction每一層level大小的計算過程
一種是靜态的數值,即每一層的大小都是固定的
一種是動态調整的,動态根據每一層大小進行計算,得到最大level_max_bytes,并依此遞推之前的level
其中函數有一個函數 MaxBytesForLevel(level),很明顯就是擷取目前level的最大的檔案大小。實作如下:
uint64_t VersionStorageInfo::MaxBytesForLevel(int level) const {
// Note: the result for level zero is not really used since we set
// the level-0 compaction threshold based on number of files.
assert(level >= 0);
assert(level < static_cast<int>(level_max_bytes_.size()));
return level_max_bytes_[level];
} 其中數組level_max_bytes_ 的更新是在CalculateBaseBytes函數中進行,在其中的更新過程還是與我們option設定的一個參數相關
level_compaction_dynamic_level_bytes,如果這個配置被置為false,意味着每一層的大小都是固定的,則會有如下的更新規則:
- 如果是level-1 ,那麼将其level_max_bytes_設定為options.max_bytes_for_level_base 這樣的配置
-
如果是大于level-1的level,則他們的level_max_bytes_ 計算方式如下:
Level-n = level_max_bytes_[n - 1] * max_bytes_for_level_multiplier*max_bytes_for_level_multiplier_additional[n]
其中
max_bytes_for_level_multiplier
和max_bytes_for_level_multiplier_additional都是通過option進行設定的,其中max_bytes_for_level_multiplier_additional預設為1
假如: max_bytes_for_level_base = 1024 ,max_bytes_for_level_multiplier = 10
則L1,L2,L3 依次為:1024,10240,102400的大小
if (!ioptions.level_compaction_dynamic_level_bytes) {
base_level_ = (ioptions.compaction_style == kCompactionStyleLevel) ? 1 : -1;
// Calculate for static bytes base case
for (int i = 0; i < ioptions.num_levels; ++i) {
if (i == 0 && ioptions.compaction_style == kCompactionStyleUniversal) {
level_max_bytes_[i] = options.max_bytes_for_level_base;
} else if (i > 1) {
level_max_bytes_[i] = MultiplyCheckOverflow(
MultiplyCheckOverflow(level_max_bytes_[i - 1],
options.max_bytes_for_level_multiplier),
options.MaxBytesMultiplerAdditional(i - 1));
} else {
level_max_bytes_[i] = options.max_bytes_for_level_base;
}
}
} 假如level_compaction_dynamic_level_bytes 被設定為true,即每次計算出來的level_max_bytes可能會不一樣
這個參數主要是為了保證LSM tree密集IO壓力下仍然能夠保證合理的樹型結構(良好的樹型結構能夠提供優秀的查找性能),這裡的計算方式是這樣的
- 找到目前樹形結構資料量最多的一層,作為Target_Size(Ln)
- 通過公式
Target_Size(Ln-1) = Target_Size(Ln) / max_bytes_for_level_multiplier
比如目前系統中最大的level的 target size是10G,num_levels = 6,max_bytes_for_level_multiplier = 10
那麼從L6-L1依次每一層level的大小如下,10G,1G,102M,10.2M,1.02M,102KB
首先計算第一個非空的level.
uint64_t max_level_size = 0;
int first_non_empty_level = -1;
for (int i = 1; i < num_levels_; i++) {
uint64_t total_size = 0;
for (const auto& f : files_[i]) {
total_size += f->fd.GetFileSize();
}
if (total_size > 0 && first_non_empty_level == -1) {
first_non_empty_level = i;
}
if (total_size > max_level_size) {
max_level_size = total_size;
}
} 得到最小的那個非0的level的size.
uint64_t base_bytes_max =
std::max(options.max_bytes_for_level_base, l0_size);
uint64_t base_bytes_min = static_cast<uint64_t>(
base_bytes_max / options.max_bytes_for_level_multiplier);
uint64_t cur_level_size = max_level_size;
for (int i = num_levels_ - 2; i >= first_non_empty_level; i--) {
// Round up after dividing
cur_level_size = static_cast<uint64_t>(
cur_level_size / options.max_bytes_for_level_multiplier);
} 找到base_level_size,一般來說也就是cur_level_size.
// Find base level (where L0 data is compacted to).
base_level_ = first_non_empty_level;
while (base_level_ > 1 && cur_level_size > base_bytes_max) {
--base_level_;
cur_level_size = static_cast<uint64_t>(
cur_level_size / options.max_bytes_for_level_multiplier);
}
if (cur_level_size > base_bytes_max) {
// Even L1 will be too large
assert(base_level_ == 1);
base_level_size = base_bytes_max;
} else {
base_level_size = cur_level_size;
} 然後給level_max_bytes指派
uint64_t level_size = base_level_size;
for (int i = base_level_; i < num_levels_; i++) {
if (i > base_level_) {
level_size = MultiplyCheckOverflow(level_size, level_multiplier_);
}
level_max_bytes_[i] = std::max(level_size, base_bytes_max);
} 3.1.4 挑選參與compaction的檔案
其中Compact的所有操作都在DBImpl::BackgroundCompaction中進行,是以接下來我們來分析 這個函數. 首先是從compaction_queue_隊列中讀取第一個需要compact的column family.
// cfd is referenced here
auto cfd = PopFirstFromCompactionQueue();
// We unreference here because the following code will take a Ref() on
// this cfd if it is going to use it (Compaction class holds a
// reference).
// This will all happen under a mutex so we don't have to be afraid of
// somebody else deleting it.
if (cfd->Unref()) {
delete cfd;
// This was the last reference of the column family, so no need to
// compact.
return Status::OK();
} 沒有禁止自動compaction的時候,接下來通過PickCompaction選取目前CF中所需要compact的内容.
if (!mutable_cf_options->disable_auto_compactions && !cfd->IsDropped()) {
c.reset(cfd->PickCompaction(*mutable_cf_options, log_buffer));
...
} 而這個函數會根據設定的不同的Compact政策調用不同的方法,這裡我們隻看預設的LevelCompact的對應函數.
Compaction* LevelCompactionBuilder::PickCompaction() {
// Pick up the first file to start compaction. It may have been extended
// to a clean cut.
SetupInitialFiles();
if (start_level_inputs_.empty()) {
return nullptr;
}
assert(start_level_ >= 0 && output_level_ >= 0);
// If it is a L0 -> base level compaction, we need to set up other L0
// files if needed.
if (!SetupOtherL0FilesIfNeeded()) {
return nullptr;
}
// Pick files in the output level and expand more files in the start level
// if needed.
if (!SetupOtherInputsIfNeeded()) {
return nullptr;
}
// Form a compaction object containing the files we picked.
Compaction* c = GetCompaction();
TEST_SYNC_POINT_CALLBACK("LevelCompactionPicker::PickCompaction:Return", c);
return c;
} 這裡PickCompaction分别調用了三個主要的函數.
- SetupInitialFiles 這個函數主要用來初始化需要Compact的檔案.
- SetupOtherL0FilesIfNeeded 如果需要compact的話,那麼還需要再設定對應的L0檔案
- SetupOtherInputsIfNeeded 選擇對應的輸出檔案
先來看SetupInitialFiles,這個函數他會周遊所有的level,然後來選擇對應需要compact的input和output.
這裡可看到,他會從之前計算好的的compact資訊中得到對應的score.
void LevelCompactionBuilder::SetupInitialFiles() {
// Find the compactions by size on all levels.
bool skipped_l0_to_base = false;
for (int i = 0; i < compaction_picker_->NumberLevels() - 1; i++) {
start_level_score_ = vstorage_->CompactionScore(i);
start_level_ = vstorage_->CompactionScoreLevel(i);
assert(i == 0 || start_level_score_ <= vstorage_->CompactionScore(i - 1));
................................................................
} 隻有當score大于一才有必要進行compact的處理(所有操作都在上面的循環中).這裡可以看到如果是level0的話,那麼output_level 則是vstorage_->base_level(),否則就是level+1. 這裡base_level()可以認為就是level1或者是最小的非空的level(之前***CalculateBaseBytes***中計算).
if (start_level_score_ >= 1) {
if (skipped_l0_to_base && start_level_ == vstorage_->base_level()) {
// If L0->base_level compaction is pending, don't schedule further
// compaction from base level. Otherwise L0->base_level compaction
// may starve.
continue;
}
output_level_ =
(start_level_ == 0) ? vstorage_->base_level() : start_level_ + 1;
if (PickFileToCompact()) {
// found the compaction!
if (start_level_ == 0) {
// L0 score = `num L0 files` / `level0_file_num_compaction_trigger`
compaction_reason_ = CompactionReason::kLevelL0FilesNum;
} else {
// L1+ score = `Level files size` / `MaxBytesForLevel`
compaction_reason_ = CompactionReason::kLevelMaxLevelSize;
}
break;
} else {
// didn't find the compaction, clear the inputs
......................................................
}
}
} 上面的代碼中我們可以看到最終是通過***PickFileToCompact***來選擇input以及output檔案.是以我們接下來就來分這個函數.
首先是得到目前level(start_level_)的未compacted的最大大小的檔案
// Pick the largest file in this level that is not already
// being compacted
const std::vector<int>& file_size =
vstorage_->FilesByCompactionPri(start_level_);
const std::vector<FileMetaData*>& level_files =
vstorage_->LevelFiles(start_level_); 緊接着就是這個函數最核心的功能了,它會開始周遊目前的輸入level的所有待compact的檔案,然後選擇一些合适的檔案然後compact到下一個level.
unsigned int cmp_idx;
for (cmp_idx = vstorage_->NextCompactionIndex(start_level_);
cmp_idx < file_size.size(); cmp_idx++) {
..........................................
} 然後我們來詳細分析上面循環中所做的事情 首先選擇好檔案之後,将會擴充目前檔案的key的範圍,得到一個”clean cut”的範圍, 這裡”clean cut”是這個意思,假設我們有五個檔案他們的key range分别為:
f1[a1 a2] f2[a3 a4] f3[a4 a6] f4[a6 a7] f5[a8 a9] 如果我們第一次選擇了f3,那麼我們通過clean cut,則将還會選擇f2,f4,因為他們都是連續的. 選擇好之後,會再做一次判斷,這次是判斷是否正在compact的out_level的檔案範圍是否和我們選擇好的檔案的key有重合,如果有,則跳過這個檔案. 這裡之是以會有這個判斷,主要原因還是因為compact是會并行的執行的.
int index = file_size[cmp_idx];
auto* f = level_files[index];
// do not pick a file to compact if it is being compacted
// from n-1 level.
if (f->being_compacted) {
continue;
}
start_level_inputs_.files.push_back(f);
start_level_inputs_.level = start_level_;
if (!compaction_picker_->ExpandInputsToCleanCut(cf_name_, vstorage_,
&start_level_inputs_) ||
compaction_picker_->FilesRangeOverlapWithCompaction(
{start_level_inputs_}, output_level_)) {
// A locked (pending compaction) input-level file was pulled in due to
// user-key overlap.
start_level_inputs_.clear();
continue;
} 選擇好輸入檔案之後,接下來就是選擇輸出level中需要一起被compact的檔案(output_level_inputs). 實作也是比較簡單,就是從輸出level的所有檔案中找到是否有和上面選擇好的input中有重合的檔案,如果有,那麼則需要一起進行compact.
Ps:這裡的輸出并不是說已經完成輸出的過程了,而是提前計算後續将要輸出到 哪一層
InternalKey smallest, largest;
compaction_picker_->GetRange(start_level_inputs_, &smallest, &largest);
CompactionInputFiles output_level_inputs;
output_level_inputs.level = output_level_;
vstorage_->GetOverlappingInputs(output_level_, &smallest, &largest,
&output_level_inputs.files);
if (!output_level_inputs.empty() &&
!compaction_picker_->ExpandInputsToCleanCut(cf_name_, vstorage_,
&output_level_inputs)) {
start_level_inputs_.clear();
continue;
}
base_index_ = index;
break; 繼續分析PickCompaction,我們知道在RocksDB中level-0會比較特殊,那是因為隻有level-0中的檔案是無序的,而在上面的操作中, 我們是假設在非level-0,是以接下來我們需要處理level-0的情況,這個函數就是 SetupOtherL0FilesIfNeeded.
這裡如果start_level_為0,也就是level-0的話,才會進行下面的處理,就是從level-0中得到所有的重合key的檔案,然後加入到start_level_inputs中.
實作上通過調用 GetOverlappingL0Files 來實作
assert(level0_compactions_in_progress()->empty());
InternalKey smallest, largest;
GetRange(*start_level_inputs, &smallest, &largest);
// Note that the next call will discard the file we placed in
// c->inputs_[0] earlier and replace it with an overlapping set
// which will include the picked file.
start_level_inputs->files.clear();
vstorage->GetOverlappingInputs(0, &smallest, &largest,
&(start_level_inputs->files));
// If we include more L0 files in the same compaction run it can
// cause the 'smallest' and 'largest' key to get extended to a
// larger range. So, re-invoke GetRange to get the new key range
GetRange(*start_level_inputs, &smallest, &largest);
if (IsRangeInCompaction(vstorage, &smallest, &largest, output_level,
parent_index)) {
return false;
}
assert(!start_level_inputs->files.empty()); 假設start_level_inputs被擴充了,那麼對應的output也需要被擴充,因為非level0的其他的level的檔案key都是不會overlap的. 那麼此時就是會調用 SetupOtherInputsIfNeeded .
if (output_level_ != 0) {
output_level_inputs_.level = output_level_;
if (!compaction_picker_->SetupOtherInputs(
cf_name_, mutable_cf_options_, vstorage_, &start_level_inputs_,
&output_level_inputs_, &parent_index_, base_index_)) {
return false;
}
compaction_inputs_.push_back(start_level_inputs_);
if (!output_level_inputs_.empty()) {
compaction_inputs_.push_back(output_level_inputs_);
}
// In some edge cases we could pick a compaction that will be compacting
// a key range that overlap with another running compaction, and both
// of them have the same output level. This could happen if
// (1) we are running a non-exclusive manual compaction
// (2) AddFile ingest a new file into the LSM tree
// We need to disallow this from happening.
if (compaction_picker_->FilesRangeOverlapWithCompaction(compaction_inputs_,
output_level_)) {
// This compaction output could potentially conflict with the output
// of a currently running compaction, we cannot run it.
return false;
}
compaction_picker_->GetGrandparents(vstorage_, start_level_inputs_,
output_level_inputs_, &grandparents_);
} else {
compaction_inputs_.push_back(start_level_inputs_);
}
return true; 回到 PickCompaction 函數,最終就是構造一個compact傳回
// Form a compaction object containing the files we picked.
Compaction* c = GetCompaction();
TEST_SYNC_POINT_CALLBACK("LevelCompactionPicker::PickCompaction:Return", c);
return c; 3.1.5 Compaction job根據擷取到資料配置設定compaction 線程
最後再回到BackgroundCompaction中,這裡就是在得到需要compact的檔案之後,進行具體的compact. 這裡我們可以看到核心的資料結構就是CompactionJob,每一次的compact都是一個job,最終對于檔案的compact都是在 CompactionJob::run中實作.
CompactionJob compaction_job(
job_context->job_id, c.get(), immutable_db_options_,
env_options_for_compaction_, versions_.get(), &shutting_down_,
preserve_deletes_seqnum_.load(), log_buffer, directories_.GetDbDir(),
GetDataDir(c->column_family_data(), c->output_path_id()), stats_,
&mutex_, &bg_error_, snapshot_seqs, earliest_write_conflict_snapshot,
snapshot_checker, table_cache_, &event_logger_,
c->mutable_cf_options()->paranoid_file_checks,
c->mutable_cf_options()->report_bg_io_stats, dbname_,
&compaction_job_stats);
compaction_job.Prepare();
NotifyOnCompactionBegin(c->column_family_data(), c.get(), status,
compaction_job_stats, job_context->job_id);
mutex_.Unlock();
compaction_job.Run();
TEST_SYNC_POINT("DBImpl::BackgroundCompaction:NonTrivial:AfterRun");
mutex_.Lock();
status = compaction_job.Install(*c->mutable_cf_options());
if (status.ok()) {
InstallSuperVersionAndScheduleWork(
c->column_family_data(), &job_context->superversion_context,
*c->mutable_cf_options(), FlushReason::kAutoCompaction);
}
*made_progress = true; 在RocksDB中,Compact是會多線程并發的執行,而這裡怎樣并發,并發多少線程都是在CompactionJob中實作的,簡單來說,當你的compact的檔案range不重合的話,那麼都是可以并發執行的。
我們先來看CompactionJob::Prepare函數,在這個函數中主要是做一些執行前的準備工作,首先是取得對應的compact的邊界,這裡每一個需要并發的compact都被抽象為一個sub compaction.是以在 GenSubcompactionBoundaries 會解析到對應的sub compaction以及邊界.解析完畢之後,則将會把對應的資訊全部加入sub_compact_states中。
void CompactionJob::Prepare() {
..........................
if (c->ShouldFormSubcompactions()) {
const uint64_t start_micros = env_->NowMicros();
GenSubcompactionBoundaries();
MeasureTime(stats_, SUBCOMPACTION_SETUP_TIME,
env_->NowMicros() - start_micros);
assert(sizes_.size() == boundaries_.size() + 1);
for (size_t i = 0; i <= boundaries_.size(); i++) {
Slice* start = i == 0 ? nullptr : &boundaries_[i - 1];
Slice* end = i == boundaries_.size() ? nullptr : &boundaries_[i];
compact_->sub_compact_states.emplace_back(c, start, end, sizes_[i]);
}
MeasureTime(stats_, NUM_SUBCOMPACTIONS_SCHEDULED,
compact_->sub_compact_states.size());
}
......................................
} 是以我們來詳細分析 GenSubcompactionBoundaries ,這個函數比較長,我們來分開分析,首先是周遊所有的需要compact的level,然後取得每一個level的邊界(也就是最大最小key)加入到bounds數組之中。
......
for (size_t lvl_idx = 0; lvl_idx < c->num_input_levels(); lvl_idx++) {
int lvl = c->level(lvl_idx);
if (lvl >= start_lvl && lvl <= out_lvl) {
const LevelFilesBrief* flevel = c->input_levels(lvl_idx);
size_t num_files = flevel->num_files;
......
if (lvl == 0) {
// For level 0 add the starting and ending key of each file since the
// files may have greatly differing key ranges (not range-partitioned)
for (size_t i = 0; i < num_files; i++) {
bounds.emplace_back(flevel->files[i].smallest_key);
bounds.emplace_back(flevel->files[i].largest_key);
}
} else {
// For all other levels add the smallest/largest key in the level to
// encompass the range covered by that level
bounds.emplace_back(flevel->files[0].smallest_key);
bounds.emplace_back(flevel->files[num_files - 1].largest_key);
if (lvl == out_lvl) {
// For the last level include the starting keys of all files since
// the last level is the largest and probably has the widest key
// range. Since it's range partitioned, the ending key of one file
// and the starting key of the next are very close (or identical).
for (size_t i = 1; i < num_files; i++) {
bounds.emplace_back(flevel->files[i].smallest_key);
}
}
}
}
}
...... 然後就對擷取到的bounds進行排序去重
std::sort(bounds.begin(), bounds.end(),
[cfd_comparator](const Slice& a, const Slice& b) -> bool {
return cfd_comparator->Compare(ExtractUserKey(a),
ExtractUserKey(b)) < 0;
});
// Remove duplicated entries from bounds
bounds.erase(
std::unique(bounds.begin(), bounds.end(),
[cfd_comparator](const Slice& a, const Slice& b) -> bool {
return cfd_comparator->Compare(ExtractUserKey(a),
ExtractUserKey(b)) == 0;
}),
bounds.end()); 接近着就來計算理想情況下所需要的subcompactions的個數以及輸出檔案的個數.
// Group the ranges into subcompactions
const double min_file_fill_percent = 4.0 / 5;
int base_level = v->storage_info()->base_level();
uint64_t max_output_files = static_cast<uint64_t>(std::ceil(
sum / min_file_fill_percent /
MaxFileSizeForLevel(*(c->mutable_cf_options()), out_lvl,
c->immutable_cf_options()->compaction_style, base_level,
c->immutable_cf_options()->level_compaction_dynamic_level_bytes)));
uint64_t subcompactions =
std::min({static_cast<uint64_t>(ranges.size()),
static_cast<uint64_t>(c->max_subcompactions()),
max_output_files}); 最後更新boundaries_,這裡會根據根據檔案的大小,通過平均的size,來吧所有的range分為幾份,最終這些都會儲存在boundaries_中.
if (subcompactions > 1) {
double mean = sum * 1.0 / subcompactions;
// Greedily add ranges to the subcompaction until the sum of the ranges'
// sizes becomes >= the expected mean size of a subcompaction
sum = 0;
for (size_t i = 0; i < ranges.size() - 1; i++) {
sum += ranges[i].size;
if (subcompactions == 1) {
// If there's only one left to schedule then it goes to the end so no
// need to put an end boundary
continue;
}
if (sum >= mean) {
boundaries_.emplace_back(ExtractUserKey(ranges[i].range.limit));
sizes_.emplace_back(sum);
subcompactions--;
sum = 0;
}
}
sizes_.emplace_back(sum + ranges.back().size);
} else {
// Only one range so its size is the total sum of sizes computed above
sizes_.emplace_back(sum);
} 然後我們來看CompactJob::Run的實作,在這個函數中,就是會周遊所有的sub_compact,然後啟動線程來進行對應的compact工作,最後等到所有的線程完成,然後退出.
std::vector<port::Thread> thread_pool;
thread_pool.reserve(num_threads - 1);
for (size_t i = 1; i < compact_->sub_compact_states.size(); i++) {
thread_pool.emplace_back(&CompactionJob::ProcessKeyValueCompaction, this,
&compact_->sub_compact_states[i]);
}
// Always schedule the first subcompaction (whether or not there are also
// others) in the current thread to be efficient with resources
ProcessKeyValueCompaction(&compact_->sub_compact_states[0]);
// Wait for all other threads (if there are any) to finish execution
for (auto& thread : thread_pool) {
thread.join();
} 可以看到run中的邏輯是 ,通過 ProcessKeyValueCompaction 拿到的sub_compact_states進行真正的compaction處理實際key-value的資料。
通過這樣冗長的調用鍊,終于進入到了下一個階段~~~
3.2 Process keys
主要做如下幾件事情
- 将 目前subcompaction 的k-v的資料取出,維護一個疊代器來進行通路(此時會構造一個堆排序的存儲結構,來通過疊代器通路堆頂元素)
-
·這裡指用戶端對指定的key下發的merge操作,包括list append, add …之類的操作)
合并的過程主要是 取到目前internal key的最新的snapshot對應的操作(主要針對put/delete,保留range_deletion)
- 将合并好的資料傳回,交給疊代器一個一個 進行通路,并進行後續的write操作(每通路一個,pop堆頂,并重建堆,再取堆頂元素)
- 建立輸出的檔案,并綁定builder 和 writer,友善後續的資料寫入
大體過程如下 圖3.2
圖3.2 compaction process key部分,這一部分主要做key之間的排序以及inernal key 的merge操作
3.2.1 構造能夠通路所有key的疊代器
首先我們進入到***ProcessKeyValueCompaction***函數之中,通過之前步驟中填充的sub_compact資料取出對應的key-value資料,構造一個InternalIterator。
std::unique_ptr<InternalIterator> input(versions_->MakeInputIterator(
sub_compact->compaction, &range_del_agg, env_options_for_read_)) 構造的過程是通過函數MakeInputIterator進行的,我們進入到該函數,這個函數構造疊代器的邏輯同樣區分level-0和level-其他
- 先擷取目前sub_compact所屬的cfd
- 針對level-0,為其中的每一個sst檔案建構一個table_cache疊代器,放入list之中
-
針對其他非level-0的層,每一層直接建立一個及聯的疊代器并放入list之中。也就是這個疊代器從它的start就能夠順序通路到該層最後一個sst檔案的最後一個key
因為非level-0的sst檔案之間本身是有序的,不像level-0的sst檔案之間可能有重疊。
- 将所有層的疊代器添加到一個疊代器數組之中,拿到該數組,通過 NewMergingIterator 疊代器維護一個底層的排序堆結構,完成所有層之間的key-value的排序
擷取到目前sub_compact的cfd
auto cfd = c->column_family_data() 針對level-0中的每一個sst檔案,構造一個table_cache的疊代器
if (c->level(which) == 0) {
const LevelFilesBrief* flevel = c->input_levels(which);
for (size_t i = 0; i < flevel->num_files; i++) {
list[num++] = cfd->table_cache()->NewIterator(
read_options, env_options_compactions, cfd->internal_comparator(),
*flevel->files[i].file_metadata, range_del_agg,
c->mutable_cf_options()->prefix_extractor.get(),
/*table_reader_ptr=*/nullptr,
/*file_read_hist=*/nullptr, TableReaderCaller::kCompaction,
/*arena=*/nullptr,
/*skip_filters=*/false, /*level=*/static_cast<int>(which),
/*smallest_compaction_key=*/nullptr,
/*largest_compaction_key=*/nullptr);
}
} 對于非level-0的層,直接将該層構造一整體的疊代器
// Create concatenating iterator for the files from this level
list[num++] = new LevelIterator(
cfd->table_cache(), read_options, env_options_compactions,
cfd->internal_comparator(), c->input_levels(which),
c->mutable_cf_options()->prefix_extractor.get(),
/*should_sample=*/false,
/*no per level latency histogram=*/nullptr,
TableReaderCaller::kCompaction, /*skip_filters=*/false,
/*level=*/static_cast<int>(which), range_del_agg,
c->boundaries(which)); 最後将擷取到的疊代器數組交給 NewMergingIterator ,進行排序結構的維護。接下來我們看一下這個底層自動堆排序的疊代器是如何建立起來的。
如果list是空的,則直接傳回空
如果隻有一個,那麼認為這個疊代器本身就是有序的,不需要建構一個堆排序的疊代器(level-0 的sst内部是有序的,之前建立的時候是為level-0每一個sst建立一個list元素;非level-0的整層都是有序的)
如果多個,那麼直接通過MergingIterator來建立堆排序的疊代器
InternalIterator* NewMergingIterator(const InternalKeyComparator* cmp,
InternalIterator** list, int n,
Arena* arena, bool prefix_seek_mode) {
assert(n >= 0);
if (n == 0) {
return NewEmptyInternalIterator<Slice>(arena);
} else if (n == 1) {
return list[0];
} else {
if (arena == nullptr) {
return new MergingIterator(cmp, list, n, false, prefix_seek_mode);
} else {
auto mem = arena->AllocateAligned(sizeof(MergingIterator));
return new (mem) MergingIterator(cmp, list, n, true, prefix_seek_mode);
}
}
} 接下來看一下 MergingIterator 這個疊代器的實作,通過将傳入的list也就是函數中的children中的所有元素添加到一個vector中,再周遊其中的每一個key-value,通過函數 AddToMinHeapOrCheckStatus 構造堆排序的底層結構,關于該資料結構中的元素順序是由使用者參數option.comparator指定,預設是 BytewiseComparator 支援的lexicographical order,也就是字典順序。
children_.resize(n);
for (int i = 0; i < n; i++) {
children_[i].Set(children[i]);
}
for (auto& child : children_) {
AddToMinHeapOrCheckStatus(&child);
}
current_ = CurrentForward(); 關于函數AddToMinHeapOrCheckStatus中的構造過程通過函數,完成
void upheap(size_t index) {
T v = std::move(data_[index]);
while (index > get_root()) {
const size_t parent = get_parent(index);
if (!cmp_(data_[parent], v)) { //這個比較器由使用者傳入,預設是字典序,即data[parent] < v 傳回true
break; // break的時候表示v已經無法下降,data_[parent]的字典序比v大,就退出循環吧
}
data_[index] = std::move(data_[parent]);
index = parent;
}
data_[index] = std::move(v);
reset_root_cmp_cache();
} 構造最小堆的過程無非就是讓插入的元素字典序中越小,越向上,如果沒法上升則就放在原地,具體過程代碼已經很明确了。
到此我們已經完成了整個key-value疊代器的建構,且擷取到之後疊代器内部的元素是一個最大堆的形态。
3.2.2 通過SeekToFirst和Next指針 處理元素
回到 ProcessKeyValueCompaction 函數,使用構造好的internalIterator再構造一個包含所有狀态的CompactionIterator,直接初始化就可以,構造完成需要将 CompactionIterator 的内部指針放在整個疊代器最開始的部位,通過Next指針來擷取下一個key-value,同時還需要需要在每次疊代器元素内部移動的時候除了調整底層堆中的字典序結構之外,還兼顧處理各個不同type的key資料,将kValueType,kTypeDeletion,kTypeSingleDeletion,kValueDeleteRange,kTypeMerge 等不同的key type處理完成。這一部分内容有非常多的邏輯,本篇還是先專注于compaction的主體邏輯。
關于kTypeDeleteRange的處理邏輯,感興趣的夥伴可以參考Rocksdb DeleteRange實作原理。
c_iter->SeekToFirst();
......
while (status.ok() && !cfd->IsDropped() && c_iter->Valid()) {
// Invariant: c_iter.status() is guaranteed to be OK if c_iter->Valid()
// returns true.
const Slice& key = c_iter->key();
const Slice& value = c_iter->value();
......
c_iter->Next();
...
} 這個while循環内部的邏輯除了Next()指針内部背景元素的處理之外,就是我們下面要講的寫入key-value到output的邏輯了。
3.3 Write keys
這一步其實是在ProcessKeyValueCompaction函數之内,其實主要是寫入SST檔案之中
-
确認key 的valueType類型,如果是data_block或者index_block類型,則放入builder狀态機中
優先建立filter_buiilder和index_builder,index builer建立成 分層格式(兩層index leve, 第一層多個restart點,用來索引具體的datablock;第二層索引第一層的index block),友善加載到記憶體進行二分查找,節約記憶體消耗,加速查找;其次再寫data_block_builder
- 如果key的 valueType類型是 range_deletion,則加入到range_delete_block_builder之中
- 先将data_block builder 利用綁定的輸出的檔案的writer寫入底層檔案
- 将filter_block / index_builder / compress_builder/range_del_builder/properties_builder 按照對應的格式加入到 meta_data_builder之中,利用綁定ouput 檔案的 writer寫入底層存儲
- 利用meta_data_handle 和 index_handle 封裝footer,寫入底層存儲
如下 圖3.3 為write key部分
圖3.3 write key部分,這一部分主要是将key-value資料按照其所屬的區域固化到底層sst檔案之中
3.3.1 将builder與輸出檔案的writer綁定
這裡的寫入建議大家先看一下SST檔案詳細格式源碼解析,
預設的 blockbase table SST 檔案有很多不同的block,除了data block之外,其他的block都是需要先寫入到一個臨時的資料結構 builder,然後由builder通過其綁定的output 檔案的writer寫入到底層磁盤形成磁盤的sst檔案結構
這裡的邏輯就是将builder與output檔案的writer進行綁定,建立好table builder
// Open output file if necessary
if (sub_compact->builder == nullptr) {
status = OpenCompactionOutputFile(sub_compact);
if (!status.ok()) {
break;
}
} 3.3.2 通過table_builder的狀态機添加block資料
然後調用builder->Add函數構造對應的builder結構,添加的過程主要是通過擁有三個狀态的狀态機完成不同block的builder建立,狀态機是由構造tablebuilder的時候建立的。
- kBuffered 為狀态機的初始狀态。處于這個狀态的時候,記憶體有較多緩存的未壓縮的datablock。在該狀态的過程中,通過 EnterUnbuffered 函數構造compression block,依此建構對應的index block和filterblock。最終将狀态置為下一個狀态的:kUnbuffered
- kUnbuffered 這個狀态時,compressing block已經通過之前的buffer中的data初步構造完成,且接下來将在這個狀态通過 Finish 完成各個block的寫入 或者通過 Abandon 丢棄目前的寫入
- kClosed 這個狀态之前已經完成了table builder的finish或者abandon,那麼接下來将析構目前的table builder
對于第一個狀态我們,進入如下邏輯,如果data block能夠滿足flush的條件,則直接flush datablock的資料到目前bulider對應的datablock存儲結構中。
接着進入EnterUnbuffered函數之中:
if (should_flush) {
assert(!r->data_block.empty());
Flush();
if (r->state == Rep::State::kBuffered &&
r->data_begin_offset > r->target_file_size) {
EnterUnbuffered();
} EnterUnbuffered 函數主要邏輯是構造compression block,如果我們開啟了compression的選項則會構造。
同時依據之前flush添加到datablock中的資料來構造index block和filter block,用來索引datablock的資料。選擇在這裡構造的話主要還是因為flush的時候表示一個完整的datablock已經寫入完成,這裡需要通過一個完整的datablock資料才有必要構造一條indexblock的資料。
其中data_block_and_keys_buffers數組存放的是未經過壓縮的datablock資料
for (size_t i = 0; ok() && i < r->data_block_and_keys_buffers.size(); ++i) {
const auto& data_block = r->data_block_and_keys_buffers[i].first;
auto& keys = r->data_block_and_keys_buffers[i].second; //多個datablock,取其中的一個
assert(!data_block.empty());
assert(!keys.empty());
for (const auto& key : keys) {
if (r->filter_builder != nullptr) {
r->filter_builder->Add(ExtractUserKey(key));
}
r->index_builder->OnKeyAdded(key);
}
WriteBlock(Slice(data_block), &r->pending_handle, true /* is_data_block */);
if (ok() && i + 1 < r->data_block_and_keys_buffers.size()) {
Slice first_key_in_next_block =
r->data_block_and_keys_buffers[i + 1].second.front();
Slice* first_key_in_next_block_ptr = &first_key_in_next_block;
r->index_builder->AddIndexEntry(&keys.back(), first_key_in_next_block_ptr,
r->pending_handle);
}
} 這裡構造index block的原則還是說 提升索引datablock的效率之外還想要減少記憶體的消耗,是以這裡會儲存一段經過壓縮的key的資料作為一個data block的偏移索引。
舉例如下:
上一個data block的end key是"the queen"
下一個data block的start key是"the tea"
那麼針對下一個data block的索引key就可以儲存為"the s",這樣既能保證比上一個datablock中的key都要大,也能保證比下一個datablock中的資料都要小,也能減少記憶體的消耗。
這裡初始化的index builer的類型根據blockbased的option來建立:
- 如果指定了kTwoLevelIndexSearch,則初始化為PartitionedIndexBuilder,它的index 結構是前n-1層是用來存儲索引datablock的資料,最後一層是存儲索引前n-1層index block的資料。
-
如果是預設的kBinarySearch,則就是支援二分查找的,則就是ShortenedIndexBuilder
還有其他的三種不同的index type
kHashSearch
kTwoLevelIndexSearch
kBinarySearchWithFirstKey 關于四種不同的index block,後續将專門分析,三種不同的資料結構,索引算法和效率也有差異。
在 EnterUnbuffered 函數建立index block
if (table_options.index_type ==
BlockBasedTableOptions::kTwoLevelIndexSearch) {
p_index_builder_ = PartitionedIndexBuilder::CreateIndexBuilder(
&internal_comparator, use_delta_encoding_for_index_values,
table_options);
index_builder.reset(p_index_builder_);
} else {
index_builder.reset(IndexBuilder::CreateIndexBuilder(
table_options.index_type, &internal_comparator,
&this->internal_prefix_transform, use_delta_encoding_for_index_values,
table_options));
} 回到 ProcessKeyValueCompaction 中的while循環中,我們不斷的周遊疊代器中的key,将其添加到對應的datablock,并完善indeblock和filter block,以及compression block。
3.3.3 通過建構的meta_index_builder和Footer完成資料的固化
接下來将 通過 FinishCompactionOutputFile 之前添加的builder資料 進行整合,處理一些delete range 的block以及更新目前compaction的邊界。
這個函數調用是當之前累計的builder中block資料的大小達到可以寫入的sst檔案本身的大小 max_output_file_size ,會觸發目前函數
Status input_status;
if (sub_compact->compaction->output_level() != 0 &&
sub_compact->current_output_file_size >=
sub_compact->compaction->max_output_file_size()) {
// (1) this key terminates the file. For historical reasons, the iterator
// status before advancing will be given to FinishCompactionOutputFile().
input_status = input->status();
output_file_ended = true;
}
......
if (output_file_ended) {
const Slice* next_key = nullptr;
if (c_iter->Valid()) {
next_key = &c_iter->key();
}
CompactionIterationStats range_del_out_stats;
status =
FinishCompactionOutputFile(input_status, sub_compact, &range_del_agg,
&range_del_out_stats, next_key);
RecordDroppedKeys(range_del_out_stats,
&sub_compact->compaction_job_stats);
} FinishCompactionOutputFile函數内部最終調用s = sub_compact->builder->Finish();完成所有資料的固化寫入
bool empty_data_block = r->data_block.empty();
Flush(); //再次執行 先嘗試将key-value的資料刷到datablock
if (r->state == Rep::State::kBuffered) {
EnterUnbuffered(); // 依據datablock資料建構index ,filter和compression block資料
}
// To make sure properties block is able to keep the accurate size of index
// block, we will finish writing all index entries first.
if (ok() && !empty_data_block) {
r->index_builder->AddIndexEntry(
&r->last_key, nullptr /* no next data block */, r->pending_handle);
}
......
BlockHandle metaindex_block_handle, index_block_handle;
MetaIndexBuilder meta_index_builder;
WriteFilterBlock(&meta_index_builder); //filter_builder資料添加到 meta_index_builder
WriteIndexBlock(&meta_index_builder, &index_block_handle);//添加index_builder
WriteCompressionDictBlock(&meta_index_builder); //添加compression block
WriteRangeDelBlock(&meta_index_builder); //添加range tombstone
WritePropertiesBlock(&meta_index_builder); //添加最終的屬性資料
if (ok()) {
// flush the meta index block
WriteRawBlock(meta_index_builder.Finish(), kNoCompression,
&metaindex_block_handle);
}
if (ok()) {
WriteFooter(metaindex_block_handle, index_block_handle); //寫Footer資料
}
r->state = Rep::State::kClosed; //最終傳回table_builder的close狀态,析構目前的table builer
return r->status;
} 4. Compaction 的一些周邊功能
這裡主要介紹一些Compaction 的周邊功能,包括remote compaction 以及 手動Compaction 的一些排程政策。
4.1 Remote Compaction
因為Rocksdb 社群擁有自己的 on 雲上的 分析 型資料庫 Rockset,其底層引擎是Rocksdb,但是實際的資料存儲是在共享存儲之上。在雲上的存儲服務 因為CPU 是最為昂貴的,而 rocksdb 的compaction 則是cpu/io 密集型的操作,i/o 問題已經在共享存儲上解決了,但是CPU問題 肯定不能讓使用者用自己的 cpu 去做。
是以就對 rocksdb 提出了 remote compaction的需求,當然對于現如今大多數的 rocksdb 使用者來說 ,其都是在shared-nothing 架構上建構的服務,這個功能基本就沒什麼收益了(畢竟shared-nothing 下,compaction 帶來的io 對上層應用的長尾影響可不是一般的大)。
更多的設計細節可以直接跳到: Rocksdb Remote Compaction 設計實作。
4.2 CompactRange
這個功能是為使用者提供的手動觸發 compaction 的接口,接口形态如下:
virtual Status CompactRange(const CompactRangeOptions& options,
ColumnFamilyHandle* column_family,
const Slice* begin, const Slice* end) = 0;
virtual Status CompactRange(const CompactRangeOptions& options,
const Slice* begin, const Slice* end) {
return CompactRange(options, DefaultColumnFamily(), begin, end);
} 兩個接口,一個是指定某一個 cf 的 compaction,另一個就是 default cf的 compaction排程。
使用的過程中 可以指定 針對一個key-range 進行 Compaction的排程 [start,end]。
如果想要排程 full compaction,則 指定 start 和 end 都為 nullptr即可。
CompactRange 如果想要排程 fullcompaction ,并不是一次排程所有層的所有檔案,而是在接口實作中拆分成按層排程的compaction job,還是主要關注 level compaction的實作排程。
DBImpl::CompactRange
......
// 前面做了一些篩選,取到了目前LSM-tree 擁有sst檔案的最大層
for (int level = 0; level <= max_level_with_files; level++) {
int output_level;
// in case the compaction is universal or if we're compacting the
// bottom-most level, the output level will be the same as input one.
// level 0 can never be the bottommost level (i.e. if all files are in
// level 0, we will compact to level 1)
...
// 對于level compaction,ouput level 是目前層 + 1.
output_level = level + 1;
if (cfd->ioptions()->compaction_style == kCompactionStyleLevel &&
cfd->ioptions()->level_compaction_dynamic_level_bytes &&
level == 0) {
output_level = ColumnFamilyData::kCompactToBaseLevel;
}
// 對目前層排程 compaction
s = RunManualCompaction(cfd, level, output_level, options, begin, end,
exclusive, false, max_file_num_to_ignore);
...... 對于level compaction來說,在按層循環排程compaction 的過程中 output level 是目前level +1。如果配置了 level_compaction_dynamic_level_bytes ,且目前level 是0,則會有優先 compact到最後一層 (num_levels -1 )。
需要注意一點:
因為這個接口被很多人用來 和compaction filter 搭配 做過期版本清理,然後在 compaction filter 的輸出字段中看到并沒有排程 full compaction。
fullcompaction 的判斷是通過 check compaction job 排程的參與的檔案個數 與目前 current version總檔案個數是否相等,相等則認為是 fullcompaction。
CompactRange 排程時,如果有多層 L0, L1,L2,L3都有檔案,則這個接口會排程3個job 去進行compaction,這段時間沒有寫入的情況下 前兩個job 肯定不是 full compaction,到第三個job 也就是 L2–>L3的時候才會是一個full compaciton标記。
如果有需要,
RunManualCompaction
這個接口也可以單獨用來排程 指定某一層的compaction。
4.3 MarkCompaction
MarkCompaction 是 rocksdb 通過 table collector 為外部使用者暴露的 調整不同 sst 的compaction 優先級的機制。
應用場景是 使用者想要讓包含指定key 或者 指定數量的 sst compaction 速度更快一些,比如 delete 版本,或者 過期版本。這樣,能加速空間的回收 以及 版本的清理,間接提升scan性能。
細節可以參考 通過 MarkCompaction 加速 Delete 版本清理,給了使用者足夠的定制化空間進行自己行為的排程。
5. 總結
到此,Compaction的主體三個步驟就已經描述完成,從Prepare keys到Write keys。
從實作的代碼邏輯上,可以說是真的很複雜,而且說實話,代碼細節以及進階文法沒得說。但是函數封裝這裡,動不動就幾百行的長函數,可能這也是這個單機 引擎難啃的原因之一吧。
- Prepare keys過程,pickcompaction函數中clean cut算法的實作原理,有點像B樹的查找,但具體實作還需要研究
- Process keys過程,那麼多複雜的疊代器轉來轉去 從開始的Internal Iterator,mergeIterator, CompactionIterator…不同疊代器之間是什麼關系呢?
- Write keys的過程細節最多,設計也是最多的。
- Filter block的實作 – block base filter和full filter兩種基本實作,效率和實作算法之間的差異
- index filter中的四種不同的index filter實作,索引datablock的效率如何展現在實作的查找算法之上。
- Compression block的實作,rocksdb支援常見的snappy,zlib,lz4等壓縮算法,在compersion block中這一些壓縮算法是怎麼實作的,都需要仔細研究揣摩。