底層資料結構
首先通過源碼,類中的field如下,
transient Node<K,V>[] table;
transient Set<Map.Entry<K,V>> entrySet;
transient int size;
transient int modCount;
int threshold;
final float loadFactor; 其中
Node
,
Map.Entry
是兩個比較核心的資料結構,先看下Node的定義
1. Map.Entry
Map.Entry
Map接口中内部定義的接口, 提供了操作Map中鍵值對的基本方法
一個
Entry
對象,代表了Map中的一個鍵值對,可以通過它擷取key,value也可以重新設定value
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
} 依次說明下上面的每個方法的作用
擷取鍵 : K getKey()
K getKey()
擷取值 : V getValue()
V getValue()
設定值 : V setValue(V value)
V setValue(V value)
haseCode 方法
傳回entry 的
hash code
, 定義如下:
(e.getKey()==null ? 0 : e.getKey().hashCode()) ^
(e.getValue()==null ? 0 : e.getValue().hashCode())
```
確定兩個 Entry對象 equals傳回true,則hashcode的值必然相同
#### equals 方法
當兩個entry對象表示的是同一個映射關系時,傳回true
規則如下
```java
(e1.getKey()==null ? e2.getKey()==null : e1.getKey().equals(e2.getKey())) &&
(e1.getValue()==null ? e2.getValue() ==null : e1.getValue().equals(e2.getValue()))
<div class="se-preview-section-delimiter"></div> 2. Node<K, V>
Node<K, V>
作為HashMap中對 Map.Entry的實作,具體邏輯如下
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
<div class="se-preview-section-delimiter"></div> 說明
-
hash
- 為什麼要有一個
next
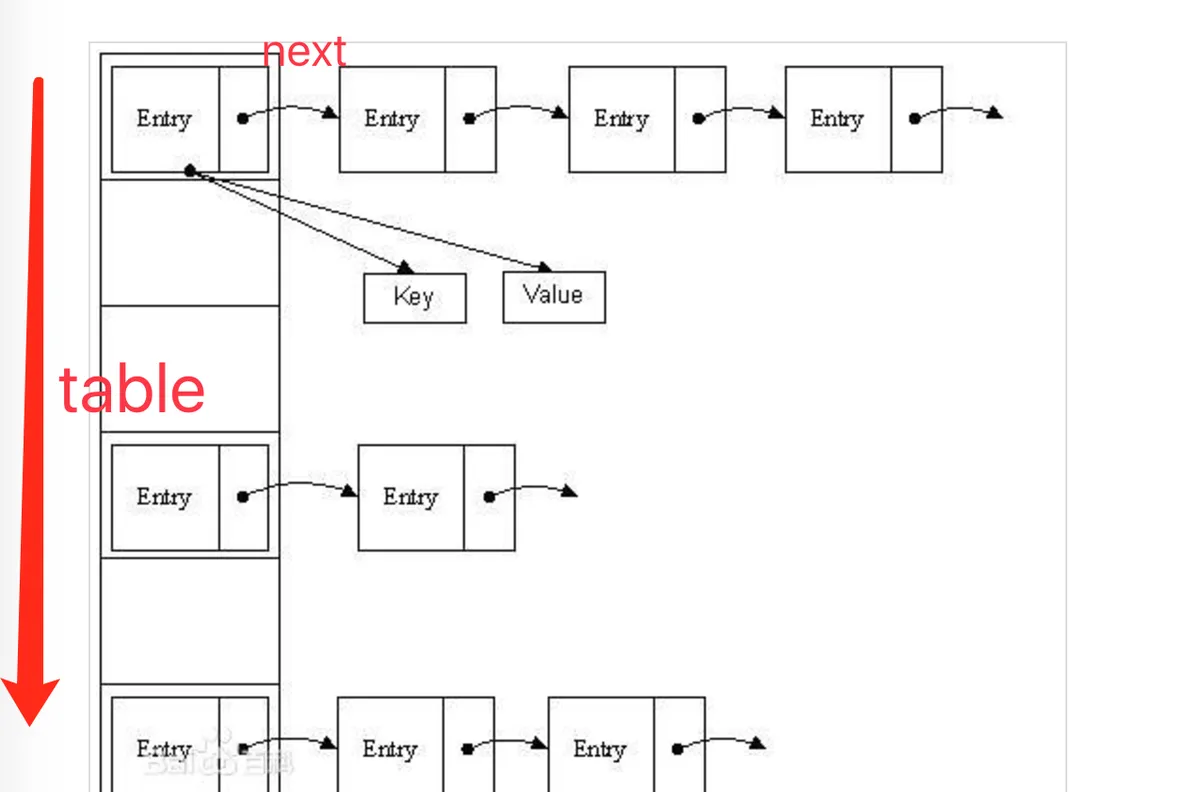
3. Node<K,V>[] table;
Node<K,V>[] table;
按我們的了解,map是一個kv結構,每個Node對象表示的就是一個kv對,那麼這個table
應該就是儲存所有的kv對的資料結構了
為什麼會是一個數組? 怎麼根據key來定位kv對在數組中的位置?
a. 前置說明
table數組大小,必須為2的n次方,首次使用是初始化,必要時(如添加新的kv對時)可以擴充容量
要了解這個數組的使用過程,最佳的思路就是通過三個方法來定位了
-
new HashMap<>()
-
put(k,v)
-
get(k)
b. 建立對象
構造方法如下,主要是設定了閥值,
loadFactory
(後面說其用處)
public HashMap(int initialCapacity, float loadFactor) {
// 參數合法性校驗省略
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
/**
* 找到大于等于cap的最小的2的幂.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
<div class="se-preview-section-delimiter"></div> 上面的構造,并沒有如我們預期的初始化
table
數組,接下來看put方法,是否有設定
table
數組呢
c. 添加kv : put(k,v)
put(k,v)
實作如下,邏輯比較複雜,會直接在代碼中給出一些注釋
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash (key的hash值,通過hash方法計算)
* @param key the key
* @param value the value to put
* @param onlyIfAbsent true表示在不存在kv時,才塞入資料
* @param evict if false, the table is in creation mode.
* @return 傳回原來的value(如果之前不存在,傳回null)
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 首先是将tab局部變量指向 table數組
if ((tab = table) == null || (n = tab.length) == 0) {
// 當table數組沒有初始化時,進行初始化,并傳回數組長度
n = (tab = resize()).length;
}
if ((p = tab[i = (n - 1) & hash]) == null) {
// 根據數組長度和key的hash值,計算出key放入數組的位置,若該位置沒有值,則直接建立一個新的Entry(即Node),放在該位置即可
tab[i] = newNode(hash, key, value, null);
} else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) {
// 若根據key的hash值,從數組中擷取的Entry對象,其key正好是我們指定的key,則直接修改這個Entry的value值即可
e = p;
}
// 下面則表示出現hash碰撞,雖然key的hash值相同,但是這個Entry的key并不是我們指定的key
else if (p instanceof TreeNode) {
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
} else {
// 疊代Entry的next節點,知道找到Entry.Key 正好是我們指定的Key為止
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 若一直都不存在,則建立一個新的Entry對象,并塞入table
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
<div class="se-preview-section-delimiter"></div> 邏輯拆解:
- 判斷
table
- 計算key的hash值(通過
hash()
- 以key的hash值計算索引,到
table
Node
- 若不存在,則建立一個Node節點,塞入該位置
- 若存在,則繼續判斷該節點的key是否和傳入的key相同or相等(
equals()
- 是,則直接修改這個Node節點的value值即可
- 否,表示出現hash碰撞了,需要周遊Node節點内部的next節點,直到到next節點為null(建立一個Node節點)或next節點就是我們希望的節點(更新該節點value值)為止
到這裡就可以解決在介紹Node類結構的兩個問題
- Node中的hash字段幹嘛的?
- hash字段儲存的是Key通過
hash()
- 可以用于判斷一個
Node
- Node中為什麼有next節點
- next節點存的是相同
hash
HashMap
- 當出現hash碰撞時,即對于計算key的hash值相同的Node節點,以連結清單結構存在
d. table數組初始化
push(k,v)
從上面的的代碼可以看出,調用
resize()
方法進行的初始化(此外這個方法也負責數組的擴容)
源碼實作比較長,這裡主要關注初始化過程,以以下面這段邏輯進行執行個體分析
Map map = new HashMap<>();
map.put(xx, xx);
<div class="se-preview-section-delimiter"></div> 對resize方法中一些邏輯配合上面的使用方式進行簡化處理, 抽出代碼如下
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // null
int oldCap = 0;
int oldThr = 0;
int newCap, newThr = 0;
// zero initial threshold signifies using defaults
newCap = 16; // DEFAULT_INITIAL_CAPACITY;
newThr = 12; // (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
return newTab;
}
<div class="se-preview-section-delimiter"></div> 上面是簡化resize的内部邏輯,單獨剝離出初始化
table
數組的代碼塊;
說明
- 初始化的數組長度為16
- threshold 閥值為12 :
0.75 * 數組長度
e. hash方法
計算key的hash值,這個直接決定hash碰撞的機率
實作如下
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
} 到這裡自然就會有一個疑問
如何根據
hash
值與
table
數組進行關聯,又如何保證碰撞較小?
這個問題單獨成篇,再将這個,這裡先記下
小結
1. 存儲結構
HashMap 的底層資料結構是一個Node數組,配合Node連結清單的方式進行kv存儲
2. 初始化
數組的初始化延遲在首次向Map中添加元素時進行
預設數組長度為16,閥值為12
閥值定義為:
The next size value at which to resize (capacity * load factor).
“`
邏輯拆解:
- 判斷
table
- 計算key的hash值(通過
hash()
- 以key的hash值計算索引,到
table
Node
- 若不存在,則建立一個Node節點,塞入該位置
- 若存在,則繼續判斷該節點的key是否和傳入的key相同or相等(
equals()
- 是,則直接修改這個Node節點的value值即可
- 否,表示出現hash碰撞了,需要周遊Node節點内部的next節點,直到到next節點為null(建立一個Node節點)或next節點就是我們希望的節點(更新該節點value值)為止
到這裡就可以解決在介紹Node類結構的兩個問題
- Node中的hash字段幹嘛的?
- hash字段儲存的是Key通過
hash()
- 可以用于判斷一個
Node
- Node中為什麼有next節點
- next節點存的是相同
hash
HashMap
- 當出現hash碰撞時,即對于計算key的hash值相同的Node節點,以連結清單結構存在
d. table數組初始化
push(k,v)
從上面的的代碼可以看出,調用
resize()
方法進行的初始化(此外這個方法也負責數組的擴容)
源碼實作比較長,這裡主要關注初始化過程,以以下面這段邏輯進行執行個體分析
4. 擷取Entry對象
-
hash()
- hash值定位
table
- 取出數組中的
Node
- null,表示不存在
- 非null,判斷Node節點的key是否等同輸入key
- 是直接傳回
- 否則周遊
Node
next
參考
- HashMap源碼注解 之 靜态工具方法hash()、tableSizeFor()(四)
![Java1.8 對HashMap的resize()的了解[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)