Spark之本地模式與叢集模式
1.spark-shell的本地模式和叢集模式
1.1 local本地模式
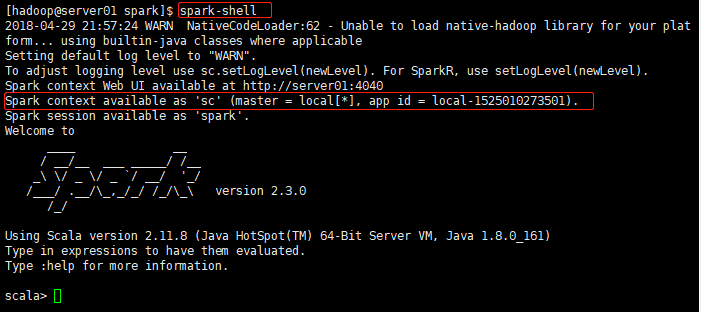
直接啟動spark-shell指令視窗
腳本啟動後,會生成一個
SparkContext
的上下文對象
sc
。并且啟動的是本地模式(local)。如圖:
1.1.1 加載本地資料
sc.textFile("file:///home/hadoop/words.txt").flatMap(_.split(",")).map((_,)).reduceByKey(_+_).sortBy(_._2,true).collect()

1.1.2 加載hdfs資料
# 因為在spark-env.sh中配置了HADOOP_CONF_DIR目錄,是以預設使用hdfs檔案系統。
# /spark/words.txt:表示hdfs檔案系統目錄
sc.textFile("/spark/words.txt").flatMap(_.split(",")).map((_,)).reduceByKey(_+_).sortBy(_._2,true).collect()
1.2 叢集模式
1.2.1 啟動叢集模式的
spark-shell
視窗
參數介紹:
--master spark://server01:7077:指定master程序的機器
--total-executor-cores :指定executor的核數(worker數量)
--executor-memory g:指定executor執行的記憶體大小
1.2.2 代碼執行
sc.textFile("/spark/words.txt").flatMap(_.split(",")).map((_,)).reduceByKey(_+_).sortBy(_._2).collect()
1.2.3 結果檢視
通過叢集模式送出的任務,在web頁面上是有展示的
本地模式(local)和叢集模式的差別
1.本地模式不運作在叢集上,運作在目前執行的機器上
2.本地模式的任務不會在web頁面顯示
3.本地模式是采用線程來模拟叢集的worker程序
2. scala api實作的本地模式和叢集模式
3.1 local本地模式
object WordCountLocal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount").setMaster("local[2]")
val sc = new SparkContext(conf)
sc.textFile("file:///d:/a.txt").flatMap(_.split(",")).map((_, )).reduceByKey(_ + _).sortBy(_._2).saveAsTextFile("file:///d:/out")
}
}
因為本地安裝了spark,是以可以直接在本地運作,在本地運作。
setMaster("local[2]")
中
local
表示本地運作,
[2]
表示是使用2個線程。
3.2 生成jar送出到叢集
代碼:
object WordCountMaster {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCountMaster")
val sparkContext = new SparkContext(conf)
sparkContext.textFile(args()).flatMap(_.split(",")).map((_, )).reduceByKey(_ + _).sortBy(_._2).saveAsTextFile(args())
}
}
送出到叢集:
spark-submit \
--master spark://server01:7077 \
--executor-memory g \
--total-executor-cores \
--class com.yundoku.spark.WordCountMaster \
/home/hadoop/sparkscalawordcount.jar \
/spark/words.txt \
/spark/scala_wordcount_out
參數講解:
--master:指定叢集的master
--executor-memory:executor的記憶體大小(worker)
--total-executor-cores :executor核數為(worker的執行個數)
--class com.yundoku.spark.WordCountMaster:包含main的類,程式的入口
/home/hadoop/sparkscalawordcount.jar :jar檔案
/spark/words.txt:輸入參數1
/spark/scala_wordcount_out:輸入參數2
運作結果:
這裡會生成
part-000000
和
part-000001
2個結果檔案,表示有2個分區。
原因是,在spark的讀取檔案時預設是使用的最小分區為2
defaultMinPartitions的值初始化,如下圖所示