神經網絡的預備知識
-
特征提取的高效性
大家可能會疑惑,對于同一個分類任務,我們可以用機器學習的算法來做,為什麼要用神經網絡呢?大家回顧一下,一個分類任務,我們在用機器學習算法來做時,首先要明确feature和label,然後把這個資料”灌”到算法裡去訓練,最後儲存模型,再來預測分類的準确性。但是這就有個問題,即我們需要實作确定好特征,每一個特征即為一個次元,特征數目過少,我們可能無法精确的分類出來,即我們所說的欠拟合,如果特征數目過多,可能會導緻我們在分類過程中過于注重某個特征導緻分類錯誤,即過拟合。
舉個簡單的例子,現在有一堆資料集,讓我們分類出西瓜和冬瓜,如果隻有兩個特征:形狀和顔色,可能沒法分區來;如果特征的次元有:形狀、顔色、瓜瓤顔色、瓜皮的花紋等等,可能很容易分類出來;如果我們的特征是:形狀、顔色、瓜瓤顔色、瓜皮花紋、瓜蒂、瓜籽的數量,瓜籽的顔色、瓜籽的大小、瓜籽的分布情況、瓜籽的XXX等等,很有可能會過拟合,譬如有的冬瓜的瓜籽數量和西瓜的類似,模型訓練後這類特征的權重較高,就很容易分錯。這就導緻我們在特征工程上需要花很多時間和精力,才能使模型訓練得到一個好的效果。然而神經網絡的出現使我們不需要做大量的特征工程,譬如提前設計好特征的内容或者說特征的數量等等,我們可以直接把資料灌進去,讓它自己訓練,自我“修正”,即可得到一個較好的效果。
-
資料格式的簡易性
在一個傳統的機器學習分類問題中,我們“灌”進去的資料是不能直接灌進去的,需要對資料進行一些處理,譬如量綱的歸一化,格式的轉化等等,不過在神經網絡裡我們不需要額外的對資料做過多的處理,具體原因可以看後面的詳細推導
-
參數數目的少量性
在面對一個分類問題時,如果用SVM來做,我們需要調整的參數需要調整核函數,懲罰因子,松弛變量等等,不同的參數組合對于模型的效果也不一樣,想要迅速而又準确的調到最适合模型的參數需要對背後理論知識的深入了解(當然,如果你說全部都試一遍也是可以的,但是花的時間可能會更多),對于一個基本的三層神經網絡來說(輸入-隐含-輸出),我們隻需要初始化時給每一個神經元上随機的賦予一個權重w和偏置項b,在訓練過程中,這兩個參數會不斷的修正,調整到最優質,使模型的誤差最小。是以從這個角度來看,我們對于調參的背後理論知識并不需要過于精通(隻不過做多了之後可能會有一些經驗,在初始值時賦予的值更科學,收斂的更快罷了)
為什麼要用卷積神經網絡?
-
傳統神經網絡的劣勢
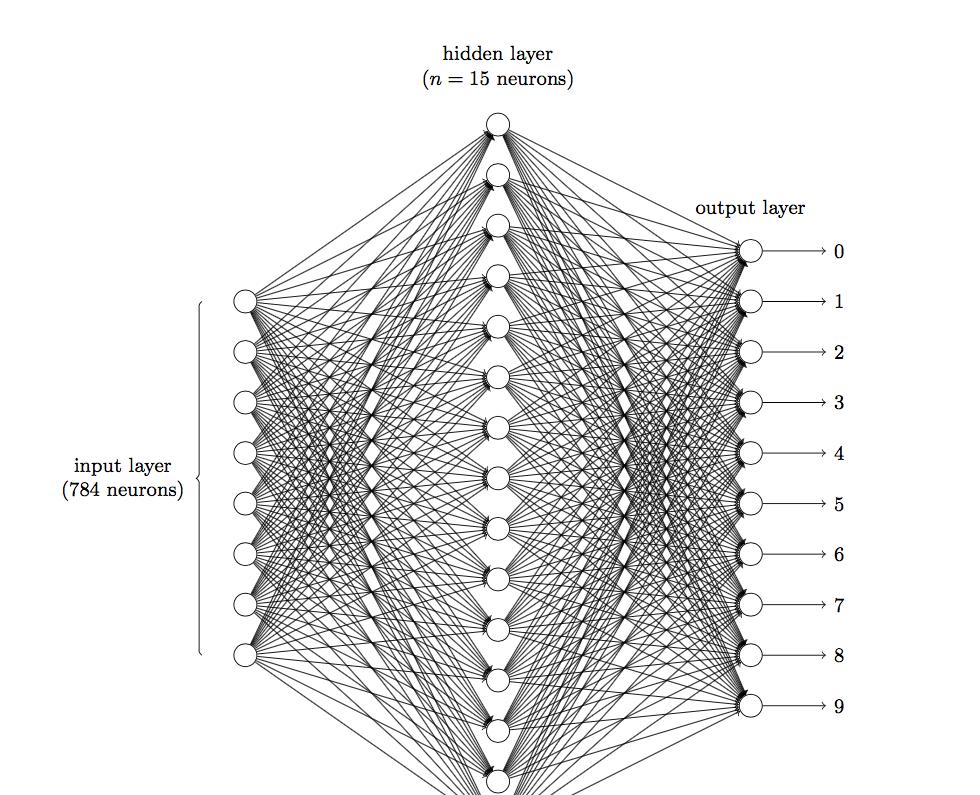
前面說到在圖像領域,用傳統的神經網絡并不合适。我們知道,圖像是由一個個像素點構成,每個像素點有三個通道,分别代表RGB顔色,那麼,如果一個圖像的尺寸是(28,28,1),即代表這個圖像的是一個長寬均為28,channel為1的圖像(channel也叫depth,此處1代表灰色圖像)。如果使用全連接配接的網絡結構,即,網絡中的神經與與相鄰層上的每個神經元均連接配接,那就意味着我們的網絡有28 * 28 =784個神經元,hidden層采用了15個神經元,那麼簡單計算一下,我們需要的參數個數(w和b)就有:784*15*10+15+10=117625個,這個參數太多了,随便進行一次反向傳播計算量都是巨大的,從計算資源和調參的角度都不建議用傳統的神經網絡。(評論中有同學對這個參數計算不太了解,我簡單說一下:圖檔是由像素點組成的,用矩陣表示的,28*28的矩陣,肯定是沒法直接放到神經元裡的,我們得把它“拍平”,變成一個28*28=784 的一列向量,這一列向量和隐含層的15個神經元連接配接,就有784*15=11760個權重w,隐含層和最後的輸出層的10個神經元連接配接,就有11760*10=117600個權重w,再加上隐含層的偏置項15個和輸出層的偏置項10個,就是:117625個參數了)
卷積神經網絡CNN基本原理詳解聲明
卷積神經網絡是什麼?
三個基本層
-
卷積層(Convolutional Layer)
上文提到我們用傳統的三層神經網絡需要大量的參數,原因在于每個神經元都和相鄰層的神經元相連接配接,但是思考一下,這種連接配接方式是必須的嗎?全連接配接層的方式對于圖像資料來說似乎顯得不這麼友好,因為圖像本身具有“二維空間特征”,通俗點說就是局部特性。譬如我們看一張貓的圖檔,可能看到貓的眼鏡或者嘴巴就知道這是張貓片,而不需要說每個部分都看完了才知道,啊,原來這個是貓啊。是以如果我們可以用某種方式對一張圖檔的某個典型特征識别,那麼這張圖檔的類别也就知道了。這個時候就産生了卷積的概念。舉個例子,現在有一個4*4的圖像,我們設計兩個卷積核,看看運用卷積核後圖檔會變成什麼樣。
由上圖可以看到,原始圖檔是一張灰階圖檔,每個位置表示的是像素值,0表示白色,1表示黑色,(0,1)區間的數值表示灰色。對于這個4*4的圖像,我們采用兩個2*2的卷積核來計算。設定步長為1,即每次以2*2的固定視窗往右滑動一個機關。以第一個卷積核filter1為例,計算過程如下:
卷積神經網絡CNN基本原理詳解聲明
feature_map1(,) = * + *(-) + * + *(-) =
feature_map1(,) = * + *(-) + * + *(-) = -
```
feature_map1(,) = * + *(-) + * + *(-) =
可以看到這就是最簡單的内積公式。feature_map1(1,1)表示在通過第一個卷積核計算完後得到的feature_map的第一行第一列的值,随着卷積核的視窗不斷的滑動,我們可以計算出一個3*3的feature_map1;同理可以計算通過第二個卷積核進行卷積運算後的feature_map2,那麼這一層卷積操作就完成了。feature_map尺寸計算公式:[ (原圖檔尺寸 -卷積核尺寸)/ 步長 ] + 1。這一層我們設定了兩個2*2的卷積核,在paddlepaddle裡是這樣定義的:
conv_pool_1 = paddle.networks.simple_img_conv_pool(
input=img,
filter_size=,
num_filters=,
num_channel=,
pool_stride=,
act=paddle.activation.Relu())
這裡調用了networks裡simple_img_conv_pool函數,激活函數是Relu(修正線性單元),我們來看一看源碼裡外層接口是如何定義的:
def simple_img_conv_pool(input,
filter_size,
num_filters,
pool_size,
name=None,
pool_type=None,
act=None,
groups=,
conv_stride=,
conv_padding=,
bias_attr=None,
num_channel=None,
param_attr=None,
shared_bias=True,
conv_layer_attr=None,
pool_stride=,
pool_padding=,
pool_layer_attr=None):
"""
Simple image convolution and pooling group.
Img input => Conv => Pooling => Output.
:param name: group name.
:type name: basestring
:param input: input layer.
:type input: LayerOutput
:param filter_size: see img_conv_layer for details.
:type filter_size: int
:param num_filters: see img_conv_layer for details.
:type num_filters: int
:param pool_size: see img_pool_layer for details.
:type pool_size: int
:param pool_type: see img_pool_layer for details.
:type pool_type: BasePoolingType
:param act: see img_conv_layer for details.
:type act: BaseActivation
:param groups: see img_conv_layer for details.
:type groups: int
:param conv_stride: see img_conv_layer for details.
:type conv_stride: int
:param conv_padding: see img_conv_layer for details.
:type conv_padding: int
:param bias_attr: see img_conv_layer for details.
:type bias_attr: ParameterAttribute
:param num_channel: see img_conv_layer for details.
:type num_channel: int
:param param_attr: see img_conv_layer for details.
:type param_attr: ParameterAttribute
:param shared_bias: see img_conv_layer for details.
:type shared_bias: bool
:param conv_layer_attr: see img_conv_layer for details.
:type conv_layer_attr: ExtraLayerAttribute
:param pool_stride: see img_pool_layer for details.
:type pool_stride: int
:param pool_padding: see img_pool_layer for details.
:type pool_padding: int
:param pool_layer_attr: see img_pool_layer for details.
:type pool_layer_attr: ExtraLayerAttribute
:return: layer's output
:rtype: LayerOutput
"""
_conv_ = img_conv_layer(
name="%s_conv" % name,
input=input,
filter_size=filter_size,
num_filters=num_filters,
num_channels=num_channel,
act=act,
groups=groups,
stride=conv_stride,
padding=conv_padding,
bias_attr=bias_attr,
param_attr=param_attr,
shared_biases=shared_bias,
layer_attr=conv_layer_attr)
return img_pool_layer(
name="%s_pool" % name,
input=_conv_,
pool_size=pool_size,
pool_type=pool_type,
stride=pool_stride,
padding=pool_padding,
layer_attr=pool_layer_attr)
我們在Paddle/python/paddle/v2/framework/nets.py 裡可以看到simple_img_conv_pool這個函數的定義:
def simple_img_conv_pool(input,
num_filters,
filter_size,
pool_size,
pool_stride,
act,
pool_type='max',
main_program=None,
startup_program=None):
conv_out = layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
act=act,
main_program=main_program,
startup_program=startup_program)
pool_out = layers.pool2d(
input=conv_out,
pool_size=pool_size,
pool_type=pool_type,
pool_stride=pool_stride,
main_program=main_program,
startup_program=startup_program)
return pool_out
可以看到這裡面有兩個輸出,conv_out是卷積輸出值,pool_out是池化輸出值,最後隻傳回池化輸出的值。conv_out和pool_out分别又調用了layers.py的conv2d和pool2d,去layers.py裡我們可以看到conv2d和pool2d是如何實作的:
def conv2d(input,
num_filters,
name=None,
filter_size=[, ],
act=None,
groups=None,
stride=[, ],
padding=None,
bias_attr=None,
param_attr=None,
main_program=None,
startup_program=None):
helper = LayerHelper('conv2d', **locals())
dtype = helper.input_dtype()
num_channels = input.shape[]
if groups is None:
num_filter_channels = num_channels
else:
if num_channels % groups is not :
raise ValueError("num_channels must be divisible by groups.")
num_filter_channels = num_channels / groups
if isinstance(filter_size, int):
filter_size = [filter_size, filter_size]
if isinstance(stride, int):
stride = [stride, stride]
if isinstance(padding, int):
padding = [padding, padding]
input_shape = input.shape
filter_shape = [num_filters, num_filter_channels] + filter_size
std = ( / (filter_size[]** * num_channels))**
filter = helper.create_parameter(
attr=helper.param_attr,
shape=filter_shape,
dtype=dtype,
initializer=NormalInitializer(, std, ))
pre_bias = helper.create_tmp_variable(dtype)
helper.append_op(
type='conv2d',
inputs={
'Input': input,
'Filter': filter,
},
outputs={"Output": pre_bias},
attrs={'strides': stride,
'paddings': padding,
'groups': groups})
pre_act = helper.append_bias_op(pre_bias, )
return helper.append_activation(pre_act)
pool2d:
def pool2d(input,
pool_size,
pool_type,
pool_stride=[, ],
pool_padding=[, ],
global_pooling=False,
main_program=None,
startup_program=None):
if pool_type not in ["max", "avg"]:
raise ValueError(
"Unknown pool_type: '%s'. It can only be 'max' or 'avg'.",
str(pool_type))
if isinstance(pool_size, int):
pool_size = [pool_size, pool_size]
if isinstance(pool_stride, int):
pool_stride = [pool_stride, pool_stride]
if isinstance(pool_padding, int):
pool_padding = [pool_padding, pool_padding]
helper = LayerHelper('pool2d', **locals())
dtype = helper.input_dtype()
pool_out = helper.create_tmp_variable(dtype)
helper.append_op(
type="pool2d",
inputs={"X": input},
outputs={"Out": pool_out},
attrs={
"poolingType": pool_type,
"ksize": pool_size,
"globalPooling": global_pooling,
"strides": pool_stride,
"paddings": pool_padding
})
return pool_out
大家可以看到,具體的實作方式還調用了layers_helper.py:[]
import copy
import itertools
from paddle.v2.framework.framework import Variable, g_main_program, \
g_startup_program, unique_name, Program
from paddle.v2.framework.initializer import ConstantInitializer, \
UniformInitializer
class LayerHelper(object):
def __init__(self, layer_type, **kwargs):
self.kwargs = kwargs
self.layer_type = layer_type
name = self.kwargs.get('name', None)
if name is None:
self.kwargs['name'] = unique_name(self.layer_type)
@property
def name(self):
return self.kwargs['name']
@property
def main_program(self):
prog = self.kwargs.get('main_program', None)
if prog is None:
return g_main_program
else:
return prog
@property
def startup_program(self):
prog = self.kwargs.get('startup_program', None)
if prog is None:
return g_startup_program
else:
return prog
def append_op(self, *args, **kwargs):
return self.main_program.current_block().append_op(*args, **kwargs)
def multiple_input(self, input_param_name='input'):
inputs = self.kwargs.get(input_param_name, [])
type_error = TypeError(
"Input of {0} layer should be Variable or sequence of Variable".
format(self.layer_type))
if isinstance(inputs, Variable):
inputs = [inputs]
elif not isinstance(inputs, list) and not isinstance(inputs, tuple):
raise type_error
else:
for each in inputs:
if not isinstance(each, Variable):
raise type_error
return inputs
def input(self, input_param_name='input'):
inputs = self.multiple_input(input_param_name)
if len(inputs) != :
raise "{0} layer only takes one input".format(self.layer_type)
return inputs[]
@property
def param_attr(self):
default = {'name': None, 'initializer': UniformInitializer()}
actual = self.kwargs.get('param_attr', None)
if actual is None:
actual = default
for default_field in default.keys():
if default_field not in actual:
actual[default_field] = default[default_field]
return actual
def bias_attr(self):
default = {'name': None, 'initializer': ConstantInitializer()}
bias_attr = self.kwargs.get('bias_attr', None)
if bias_attr is True:
bias_attr = default
if isinstance(bias_attr, dict):
for default_field in default.keys():
if default_field not in bias_attr:
bias_attr[default_field] = default[default_field]
return bias_attr
def multiple_param_attr(self, length):
param_attr = self.param_attr
if isinstance(param_attr, dict):
param_attr = [param_attr]
if len(param_attr) != and len(param_attr) != length:
raise ValueError("parameter number mismatch")
elif len(param_attr) == and length != :
tmp = [None] * length
for i in xrange(length):
tmp[i] = copy.deepcopy(param_attr[])
param_attr = tmp
return param_attr
def iter_inputs_and_params(self, input_param_name='input'):
inputs = self.multiple_input(input_param_name)
param_attrs = self.multiple_param_attr(len(inputs))
for ipt, param_attr in itertools.izip(inputs, param_attrs):
yield ipt, param_attr
def input_dtype(self, input_param_name='input'):
inputs = self.multiple_input(input_param_name)
dtype = None
for each in inputs:
if dtype is None:
dtype = each.data_type
elif dtype != each.data_type:
raise ValueError("Data Type mismatch")
return dtype
def create_parameter(self, attr, shape, dtype, suffix='w',
initializer=None):
# Deepcopy the attr so that parameters can be shared in program
attr_copy = copy.deepcopy(attr)
if initializer is not None:
attr_copy['initializer'] = initializer
if attr_copy['name'] is None:
attr_copy['name'] = unique_name(".".join([self.name, suffix]))
self.startup_program.global_block().create_parameter(
dtype=dtype, shape=shape, **attr_copy)
return self.main_program.global_block().create_parameter(
name=attr_copy['name'], dtype=dtype, shape=shape)
def create_tmp_variable(self, dtype):
return self.main_program.current_block().create_var(
name=unique_name(".".join([self.name, 'tmp'])),
dtype=dtype,
persistable=False)
def create_variable(self, *args, **kwargs):
return self.main_program.current_block().create_var(*args, **kwargs)
def create_global_variable(self, persistable=False, *args, **kwargs):
return self.main_program.global_block().create_var(
*args, persistable=persistable, **kwargs)
def set_variable_initializer(self, var, initializer):
assert isinstance(var, Variable)
self.startup_program.global_block().create_var(
name=var.name,
type=var.type,
dtype=var.data_type,
shape=var.shape,
persistable=True,
initializer=initializer)
def append_bias_op(self, input_var, num_flatten_dims=None):
"""
Append bias operator and return its output. If the user does not set
bias_attr, append_bias_op will return input_var
:param input_var: the input variable. The len(input_var.shape) is larger
or equal than 2.
:param num_flatten_dims: The input tensor will be flatten as a matrix
when adding bias.
`matrix.shape = product(input_var.shape[0:num_flatten_dims]), product(
input_var.shape[num_flatten_dims:])`
"""
if num_flatten_dims is None:
num_flatten_dims = self.kwargs.get('num_flatten_dims', None)
if num_flatten_dims is None:
num_flatten_dims =
size = list(input_var.shape[num_flatten_dims:])
bias_attr = self.bias_attr()
if not bias_attr:
return input_var
b = self.create_parameter(
attr=bias_attr, shape=size, dtype=input_var.data_type, suffix='b')
tmp = self.create_tmp_variable(dtype=input_var.data_type)
self.append_op(
type='elementwise_add',
inputs={'X': [input_var],
'Y': [b]},
outputs={'Out': [tmp]})
return tmp
def append_activation(self, input_var):
act = self.kwargs.get('act', None)
if act is None:
return input_var
if isinstance(act, basestring):
act = {'type': act}
tmp = self.create_tmp_variable(dtype=input_var.data_type)
act_type = act.pop('type')
self.append_op(
type=act_type,
inputs={"X": [input_var]},
outputs={"Y": [tmp]},
attrs=act)
return tmp
是以這個卷積過程就完成了。從上文的計算中我們可以看到,同一層的神經元可以共享卷積核,那麼對于高位資料的處理将會變得非常簡單。并且使用卷積核後圖檔的尺寸變小,友善後續計算,并且我們不需要手動去選取特征,隻用設計好卷積核的尺寸,數量和滑動的步長就可以讓它自己去訓練了,省時又省力啊。
-
為什麼卷積核有效?
那麼問題來了,雖然我們知道了卷積核是如何計算的,但是為什麼使用卷積核計算後分類效果要由于普通的神經網絡呢?我們仔細來看一下上面計算的結果。通過第一個卷積核計算後的feature_map是一個三維資料,在第三列的絕對值最大,說明原始圖檔上對應的地方有一條垂直方向的特征,即像素數值變化較大;而通過第二個卷積核計算後,第三列的數值為0,第二行的數值絕對值最大,說明原始圖檔上對應的地方有一條水準方向的特征。
仔細思考一下,這個時候,我們設計的兩個卷積核分别能夠提取,或者說檢測出原始圖檔的特定的特征。此時我們其實就可以把卷積核就了解為特征提取器啊!現在就明白了,為什麼我們隻需要把圖檔資料灌進去,設計好卷積核的尺寸、數量和滑動的步長就可以讓自動提取出圖檔的某些特征,進而達到分類的效果啊!
注: 1.此處的卷積運算是兩個卷積核大小的矩陣的内積運算,不是矩陣乘法。即相同位置的數字相乘再相加求和。不要弄混淆了。
2.卷積核的公式有很多,這隻是最簡單的一種。我們所說的卷積核在數字信号處理裡也叫濾波器,那濾波器的種類就多了,均值濾波器,高斯濾波器,拉普拉斯濾波器等等,不過,不管是什麼濾波器,都隻是一種數學運算,無非就是計算更複雜一點。
3.每一層的卷積核大小和個數可以自己定義,不過一般情況下,根據實驗得到的經驗來看,會在越靠近輸入層的卷積層設定少量的卷積核,越往後,卷積層設定的卷積核數目就越多。具體原因大家可以先思考一下,小結裡會解釋原因。
-
池化層(Pooling Layer)
通過上一層2*2的卷積核操作後,我們将原始圖像由4*4的尺寸變為了3*3的一個新的圖檔。池化層的主要目的是通過降采樣的方式,在不影響圖像品質的情況下,壓縮圖檔,減少參數。簡單來說,假設現在設定池化層采用MaxPooling,大小為2*2,步長為1,取每個視窗最大的數值重新,那麼圖檔的尺寸就會由3*3變為2*2:(3-2)+1=2。從上例來看,會有如下變換:
通常來說,池化方法一般有一下兩種: 卷積神經網絡CNN基本原理詳解聲明
MaxPooling:取滑動視窗裡最大的值
AveragePooling:取滑動視窗内所有值的平均值
-
為什麼采用Max Pooling?
從計算方式來看,算是最簡單的一種了,取max即可,但是這也引發一個思考,為什麼需要Max Pooling,意義在哪裡?如果我們隻取最大值,那其他的值被舍棄難道就沒有影響嗎?不會損失這部分資訊嗎?如果認為這些資訊是可損失的,那麼是否意味着我們在進行卷積操作後仍然産生了一些不必要的備援資訊呢?
其實從上文分析卷積核為什麼有效的原因來看,每一個卷積核可以看做一個特征提取器,不同的卷積核負責提取不同的特征,我們例子中設計的第一個卷積核能夠提取出“垂直”方向的特征,第二個卷積核能夠提取出“水準”方向的特征,那麼我們對其進行Max Pooling操作後,提取出的是真正能夠識别特征的數值,其餘被舍棄的數值,對于我提取特定的特征并沒有特别大的幫助。那麼在進行後續計算使,減小了feature map的尺寸,進而減少參數,達到減小計算量,缺不損失效果的情況。
不過并不是所有情況Max Pooling的效果都很好,有時候有些周邊資訊也會對某個特定特征的識别産生一定效果,那麼這個時候舍棄這部分“不重要”的資訊,就不劃算了。是以具體情況得具體分析,如果加了Max Pooling後效果反而變差了,不如把卷積後不加Max Pooling的結果與卷積後加了Max Pooling的結果輸出對比一下,看看Max Pooling是否對卷積核提取特征起了反效果。
-
Zero Padding
是以到現在為止,我們的圖檔由4*4,通過卷積層變為3*3,再通過池化層變化2*2,如果我們再添加層,那麼圖檔豈不是會越變越小?這個時候我們就會引出“Zero Padding”(補零),它可以幫助我們保證每次經過卷積或池化輸出後圖檔的大小不變,如,上述例子我們如果加入Zero Padding,再采用3*3的卷積核,那麼變換後的圖檔尺寸與原圖檔尺寸相同,如下圖所示:
卷積神經網絡CNN基本原理詳解聲明 通常情況下,我們希望圖檔做完卷積操作後保持圖檔大小不變,是以我們一般會選擇尺寸為3*3的卷積核和1的zero padding,或者5*5的卷積核與2的zero padding,這樣通過計算後,可以保留圖檔的原始尺寸。那麼加入zero padding後的feature_map尺寸 =( width + 2 * padding_size - filter_size )/stride + 1
注:這裡的width也可換成height,此處是預設正方形的卷積核,weight = height,如果兩者不相等,可以分開計算,分别補零。
-
Flatten層 & Fully Connected Layer
到這一步,其實我們的一個完整的“卷積部分”就算完成了,如果想要疊加層數,一般也是疊加“Conv-MaxPooing”,通過不斷的設計卷積核的尺寸,數量,提取更多的特征,最後識别不同類别的物體。做完Max Pooling後,我們就會把這些資料“拍平”,丢到Flatten層,然後把Flatten層的output放到full connected Layer裡,采用softmax對其進行分類。
卷積神經網絡CNN基本原理詳解聲明
-
小結
這一節我們介紹了最基本的卷積神經網絡的基本層的定義,計算方式和起的作用。有幾個小問題可以供大家思考一下:
1.卷積核的尺寸必須為正方形嗎?可以為長方形嗎?如果是長方形應該怎麼計算?
2.卷積核的個數如何确定?每一層的卷積核的個數都是相同的嗎?
3.步長的向右和向下移動的幅度必須是一樣的嗎?
如果對上面的講解真的弄懂了的話,其實這幾個問題并不難回答。下面給出我的想法,可以作為參考:
1.卷積核的尺寸不一定非得為正方形。長方形也可以,隻不過通常情況下為正方形。如果要設定為長方形,那麼首先得保證這層的輸出形狀是整數,不能是小數。如果你的圖像是邊長為 28 的正方形。那麼卷積層的輸出就滿足 [ (28 - kernel_size)/ stride ] + 1 ,這個數值得是整數才行,否則沒有實體意義。譬如,你算得一個邊長為 3.6 的 feature map 是沒有實體意義的。 pooling 層同理。FC 層的輸出形狀總是滿足整數,其唯一的要求就是整個訓練過程中 FC 層的輸入得是定長的。如果你的圖像不是正方形。那麼在制作資料時,可以縮放到統一大小(非正方形),再使用非正方形的 kernel_size 來使得卷積層的輸出依然是整數。總之,撇開網絡結果設定的好壞不談,其本質上就是在做算術應用題:如何使得各層的輸出是整數。
2.由經驗确定。通常情況下,靠近輸入的卷積層,譬如第一層卷積層,會找出一些共性的特征,如手寫數字識别中第一層我們設定卷積核個數為5個,一般是找出諸如”橫線”、“豎線”、“斜線”等共性特征,我們稱之為basic feature,經過max pooling後,在第二層卷積層,設定卷積核個數為20個,可以找出一些相對複雜的特征,如“橫折”、“左半圓”、“右半圓”等特征,越往後,卷積核設定的數目越多,越能展現label的特征就越細緻,就越容易分類出來,打個比方,如果你想分類出“0”的數字,你看到這個特征,能推測是什麼數字呢?隻有越往後,檢測識别的特征越多,試過能識别這幾個特征,那麼我就能夠确定這個數字是“0”。
3.有stride_w和stride_h,後者表示的就是上下步長。如果用stride,則表示stride_h=stride_w=stride。
手寫數字識别的CNN網絡結構
上面我們了解了卷積神經網絡的基本結構後,現在來具體看一下在實際資料—手寫數字識别中是如何操作的。上文中我定義了一個最基本的CNN網絡。如下(代碼詳見github)
def convolutional_neural_network_org(img):
# first conv layer
conv_pool_1 = paddle.networks.simple_img_conv_pool(
input=img,
filter_size=,
num_filters=,
num_channel=,
pool_size=,
pool_stride=,
act=paddle.activation.Relu())
# second conv layer
conv_pool_2 = paddle.networks.simple_img_conv_pool(
input=conv_pool_1,
filter_size=,
num_filters=,
num_channel=,
pool_size=,
pool_stride=,
act=paddle.activation.Relu())
# fully-connected layer
predict = paddle.layer.fc(
input=conv_pool_2, size=, act=paddle.activation.Softmax())
return predict
那麼它的網絡結構是:
conv1—-> conv2—->fully Connected layer
非常簡單的網絡結構。第一層我們采取的是3*3的正方形卷積核,個數為20個,深度為1,stride為2,pooling尺寸為2*2,激活函數采取的為RELU;第二層隻對卷積核的尺寸、個數和深度做了些變化,分别為5*5,50個和20;最後連結一層全連接配接,設定10個label作為輸出,采用Softmax函數作為分類器,輸出每個label的機率。
那麼這個時候我考慮的問題是,既然上面我們已經了解了卷積核,改變卷積核的大小是否會對我的結果造成影響?增多卷積核的數目能夠提高準确率?于是我做了個實驗:
* 第一次改進:僅改變第一層與第二層的卷積核數目的大小,其他保持不變。可以看到結果提升了0.06%
* 第二次改進:保持3*3的卷積核大小,僅改變第二層的卷積核數目,其他保持不變,可以看到結果相較于原始參數提升了0.08%
由以上結果可以看出,改變卷積核的大小與卷積核的數目會對結果産生一定影響,在目前手寫數字識别的項目中,縮小卷積核尺寸,增加卷積核數目都會提高準确率。不過以上實驗隻是一個小測試,有興趣的同學可以多做幾次實驗,看看參數帶來的具體影響,下篇文章我們會着重分析參數的影響。
這篇文章主要介紹了神經網絡的預備知識,卷積神經網絡的常見的層及基本的計算過程,看完後希望大家明白以下幾個知識點:
- 為什麼卷積神經網絡更适合于圖像分類?相比于傳統的神經網絡優勢在哪裡?
- 卷積層中的卷積過程是如何計算的?為什麼卷積核是有效的?
- 卷積核的個數如何确定?應該選擇多大的卷積核對于模型來說才是有效的?尺寸必須為正方形嗎?如果是長方形因該怎麼做?
- 步長的大小會對模型的效果産生什麼樣的影響?垂直方向和水準方向的步長是否得設定為相同的?
- 為什麼要采用池化層,Max Pooling有什麼好處?
- Zero Padding有什麼作用?如果已知一個feature map的尺寸,如何确定zero padding的數目?
聲明
本文屬于轉載!!!僅作用于個人學習用的,沒有其他目的,作為一個初學這,我感覺這篇部落格讓我受益匪淺,是以搬到這裡,作為自己學習過程中的一個見證。
轉載自:
- (1)http://www.cnblogs.com/charlotte77/p/7759802.html