Big-Data-Project
Hadoop2.x、Zookeeper、Flume、Hive、Hbase、Kafka、Spark2.x、SparkStreaming、MySQL、Hue、J2EE、websoket、Echarts
項目名稱:新聞日志大資料處理系統
項目簡介
github開源
源碼:https://github.com/changeforeda/Big-Data-Project
目标
1、完成大資料項目的架構設計,安裝部署,架構繼承與開發、使用者可視化互動設計
2、完成實時線上資料分析
3、完成離線資料分析
具體功能
1)捕獲使用者浏覽日志資訊
2)實時分析前20名流量最高的新聞話題
3)實時統計目前線上已曝光的新聞話題
4)統計哪個時段使用者浏覽量最高
5)報表
項目技術點
Hadoop2.x、Zookeeper、Flume、Hive、Hbase
Kafka、Spark2.x、SparkStreaming
MySQL、Hue、J2EE、websoket、Echarts
開發工具
虛拟機: VMware、centos
虛拟機ssh: SecureCRT(在windows上連結多個虛拟機)
修改源碼:idea
檢視各種資料:notepad++(安裝NppFTP插件,修改虛拟機中配置檔案,好用的一批)
項目架構
圖檔來自于卡夫卡公司
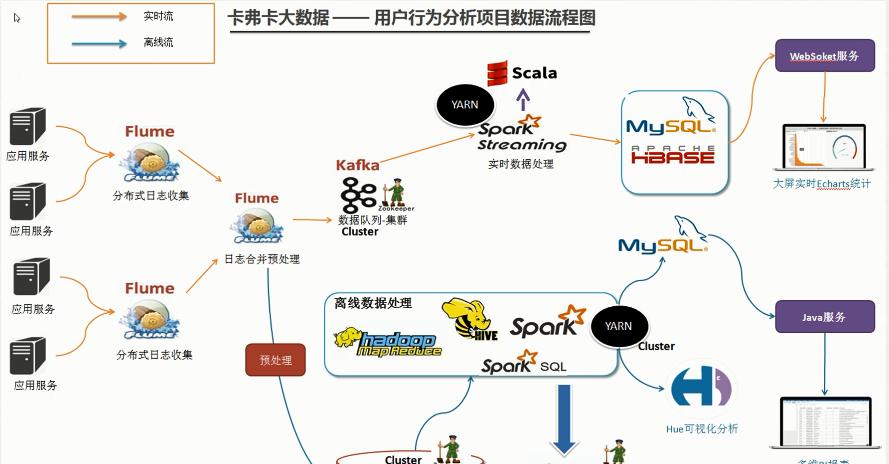
叢集資源規劃
利用VMware虛拟機+centos完成,基本要求筆記本電腦記憶體在8G以上。
最低要去克隆出3台虛拟機,每台給2G記憶體。

項目實作步驟
1、第一章:項目需求分析與設計
2、第二章:linux環境準備與設定
3、第三章:Hadoop2.X分布式叢集部署
4、第四章:Zookeeper分布式叢集部署
5、第五章:hadoop的高可用配置(HA)
6、第六章:hadoop的HA下的高可用HBase部署
7、第七章:Kafka簡介和分布式部署
8、第八章:Flume簡介和分布式部署
9、第九章:Flume源碼修改與HBase+Kafka內建
10、第十章:Flume+HBase+Kafka內建全流程測試
11、第十一章:mysql、Hive安裝與內建
12、第十二章:Hive與Hbase內建
13、第十三章:Cloudera HUE大資料可視化分析
14、第十四章:Spark2.X叢集安裝與spark on yarn部署
15、第十五章:基于IDEA環境下的Spark2.X程式開發
16、第十六章:Spark Streaming實時資料處理