本文轉載自:https://www.cnblogs.com/mafuqiang/p/7161592.html
乘積量化
1。簡介
乘積量化(PQ)算法是和VLAD算法是由法國INRIA實驗室一同提出來的,為的是加快圖像的檢索速度,是以它是一種檢索算法,在矢量量化(Vector Quantization,VQ)的基礎上發展而來,雖然PQ不算是新算法,但是這種思想還是挺有用處的,本文沒有添加公式。
它原文中是接在VLAD算法後面,假設我們使用VLAD算法獲得了1M的圖像表達向量,向量的次元為D=128,則對于一幅查詢圖像來說,我們需要計算1M個餘弦距離,這樣實時性就比較差。是以如何加快這種距離的計算速度就是PQ算法所要完成的任務。當然為了解決這個問題,已經有很多算法被提出了,如KDTree,LSH,ITQ等都是為解決這個問題而提出的,屬于KNN或ANN範疇。
2。空間切分
首先,PQ先将D維空間切分成M份:即将128維空間切分成M個D/M維的子空間,如下圖所示M=8(在原文中,作者由于是在PCA之後進行的PQ檢索,是以進行了一個随機旋轉,因為PCA之後特征值的順序是按照從大到小排列的)
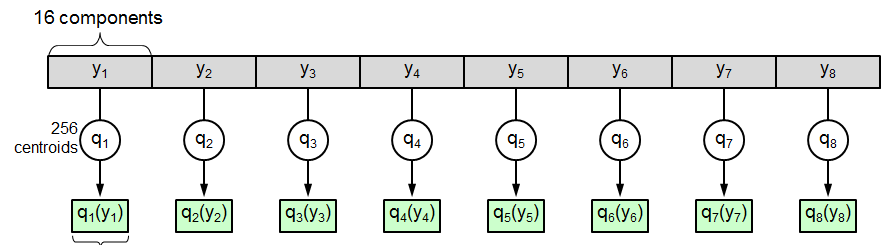
用代碼表示就是把向量次元切分:
int ds= d / nsq;
for ( int i = 0; i < nsq; i ++ )
{
for ( int j = 0; j < ds; j ++ )
{
vs.push_back( vtrain.row( i*ds + j ) );
}
}
//vtrain的轉置是原始128維向量,vs是其中的一個子向量 3。量化
這樣就可以在每個子空間内都會有1M個短向量,我們為每個子空間單獨訓練一本碼書,圖中碼書規模為k=256,次元d=D/M=128/8=16,代碼隻要在上面的外循環中添加k-means聚類即可:
kmeans( vs, ks, labelssub, TermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, 50, 0.001 ),
3, KMEANS_PP_CENTERS, centers ); 到這裡我們就有M=8本子碼書,下面我們依次量化每個子空間的資料,量化的過程就是計算每個短向量距離最近的聚類中心,距離就是L2距離,可以調用OpenCV函數,也可以自己寫一個距離計算函數,但是要統一,如:
float my_norm_L2( Mat mat1, Mat mat2 )
{
int d = mat1.cols;
float sum_d = 0.0;
for ( int i = 0; i < d; i ++ )
{
float pp = mat1.at<float>( 0, i ) - mat2.at<float>( 0, i );
sum_d = sum_d + pp*pp;
}
return sum_d;
} 4。壓縮
現在考慮一個D=128維的原始向量,它被切分成了M=8個d=16維的短向量,同時每個短向量都對應一個量化的索引值,索引值即該短向量距離最近的聚類中心的編号,每一個原始向量就可以壓縮成M個索引值構成的壓縮向量,隻要設計好了資料結構,就可以獲得所有1M資料的壓縮向量。壓縮向量其實就是M個索引值,每個索引值對應一個聚類中心,是以要同時儲存壓縮向量和聚類中心。
其實一個向量被8個索引值同時索引,而如果把這8個索引值轉換成一個的話是多大呢,k的M次方,這裡應該是256的8次方,這是一個很大很大的數,而上面的操作就等效于生成了一個這麼大規模的碼書。為什麼這麼說呢,因為每一個短向量(或稱子向量)量化的過程都有k個選擇,而一個原始向量有M個選擇,類似于8位256進制的數可以表示的最大數值:

對于query圖像的原始向量也經過上述流程的切分和量化過程,最後生成同樣的M維壓縮向量。
5。距離計算
對于訓練資料和測試資料都壓縮完成後,接下來就是讨論如何計算兩個壓縮向量之間的距離呢?而且是快速的計算。
作者提供了兩種距離計算方式,分别為 “對稱距離計算” 和 “非對稱距離計算” ,分别如下左右圖所示:
對稱距離計算:直接使用兩個壓縮向量x,y的索引值所對應的碼字q(x),q(y)之間的距離代替之,而q(x),q(y)之間的距離可以離線計算,是以可以把q(x),q(y)之間的距離制作成查找表,隻要按照壓縮向量的索引值進行對應的查找就可以了,是以速度非常快;
非對稱距離計算:使用x,q(y)之間的距離代替x,y之間的距離,其中x是測試向量。雖然y的個數可能有上百萬個,但是q(y)的個數隻有k個,對于每個x,我們隻需要在輸入x之後先計算一遍x和k個q(y)的距離,制成查找表(因為隻有k個,是以速度是非常快的),然後按照y對應的壓縮向量索引值進行取值操作就可以了。
Mat sumidxtab( Mat &D, Mat&x, Mat & dis )
{
dis = Mat::zeros( 1, x.rows, CV_32FC1 );
for ( int i = 0; i < x.rows; i ++ )
{
float distmp = 0;
for ( int j = 0; j < D.cols; j ++ )
{
distmp = distmp + D.at<float>( x.at<int>( i, j ), j ) ;//ADC距離計算方式;
}
dis.at<float>( 0, i ) = distmp;
}
return dis;
}
//D為查找表,x為壓縮向量,dis為最終的距離 6。總結
不管哪種計算方法都可以實作快速的距離計算,但是非對稱距離計算由于隻量化了y,是以計算的距離精度更高,效果也更好。距離計算過程中隻需要存儲碼書和對應的索引值就可以完全抛棄原始的圖像表達向量,實作資料的壓縮和距離的快速計算。
但是需要明白的是,這種算法是基于量化的,是以必然存在量化誤差,是以距離的計算并不是完全準确的。通常通過這種算法迅速傳回N個結果,然後再在N個結果中進行進一步的比對計算,得到比較準确的結果。
在原文中,還有基于PQ的非線性計算方法IVFADC,它的速度更快,精度反而更高了,有時間再介紹。其實後續人們不斷改進了PQ算法,如OPQ,Multi-ADC,DPQ,AQ/APQ,TQ,LOPQ等等,其中OPQ,Multi-ADC的提升效果還是比較明顯的。