1. 資料的統計名額
整個講解使用Python來進行開發,希望大家已經搭建好了自己熟悉的Python環境和IDE,整個工程主要使用Python的三個資料處理第三方庫,沒有安裝過的可以自己裝一下
如果你沒有很好的Python開發環境,你可以去看看之前的文章:Anaconda——python的內建安裝程式
# Numpy 主要是對數組進行向量化,提供許多向量的操作
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
# Pandas 将資料讀成一個DataFrame,友善進行行操作和列操作,而且有很好的讀寫性能
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
# SciPy 主要是提供了一些特殊計算的功能,比如導數,偏導等等
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple SciPy
上面三個便是Numpy,Pandas以及SciPy的鏡像源安裝,如果你是按照我的文章去搭建的環境,那麼這三個應該就是預設下載下傳好的,無需再重複安裝
依賴包的導入
# 導入division為了確定一個數除以另外一個數的結果盡量不是0
from __future__ import division
# 導入Pandas起名為pd
import pandas as pd
# 導入Numpy起名為np
import numpy as np
# 從SciPy導入stats
from scipy import stats
1.1 資料診斷的目的
- 了解特征的分布,缺失和異常情況
- 統計名額可以直接用于資料的預處理
資料的擷取于讀取:我們可以自己去制作一份,或者就拿現實中所能使用到的資料,這裡我是用Kaggle提供的一些資料,資料連結為:https://www.kaggle.com/c/santander-customer-satisfaction
from __future__ import division
import pandas as pd
import numpy as np
from scipy import stats
# 0. Read Data
df = pd.read_csv("train.csv")
label = df['TARGET']
df = df.drop(['ID', 'TARGET'], axis=1)
1.2 統計值
1. 均值:一組資料中所有資料之和再除以這組資料的個數
2. 中位數:按順序排列的一組資料中居于中間位置的數
3. 最大值:已知的資料中的最大的一個值
4. 最小值:已知的資料中的最小的一個值
5. 計數類:比如0值多少,1值多少,缺失值多少等等
6. 缺失值:指粗糙資料中由于缺少資訊而造成的資料的聚類、分組、删失或截斷
7. 方差:在機率論和統計方差衡量随機變量或一組資料時離散程度的度量
8. 分位點:指将一個随機變量的機率分布範圍分為幾個等份的數值點
9. 值的頻數:變量值中代表某種特征的數(标志值)出現的次數
2. 利用Python制作資料診斷工具
2.1 統計描述——計數類
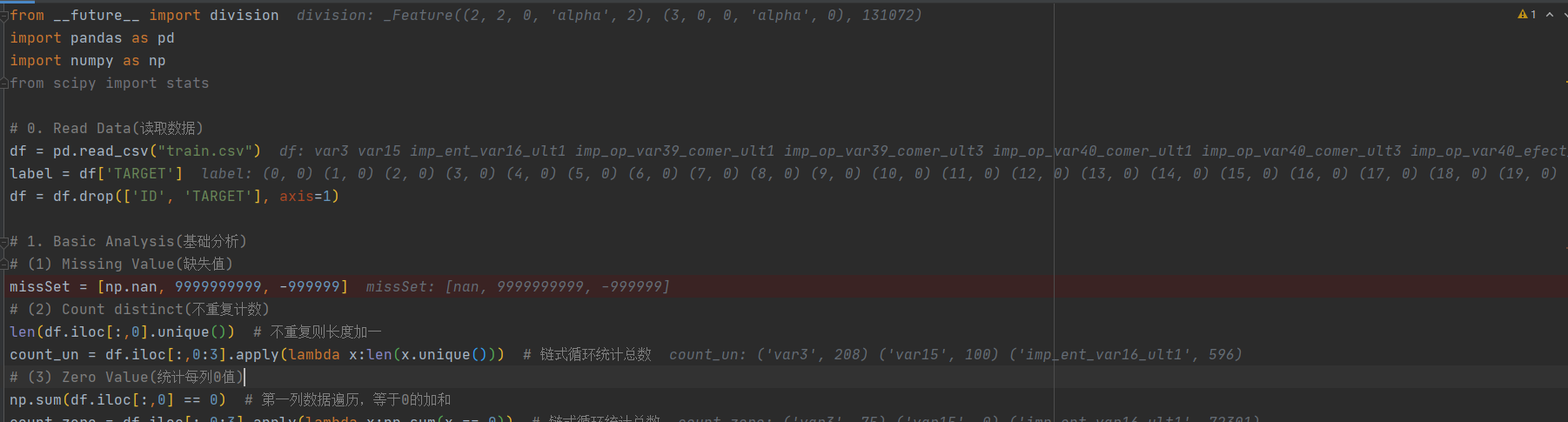
from __future__ import division
import pandas as pd
import numpy as np
from scipy import stats
# 0. Read Data(讀取資料)
df = pd.read_csv("train.csv")
label = df['TARGET']
df = df.drop(['ID', 'TARGET'], axis=1)
# 1. Basic Analysis(基礎分析)
# (1) Missing Value(缺失值)
missSet = [np.nan, 9999999999, -999999]
# (2) Count distinct(不重複計數)
len(df.iloc[:,0].unique()) # 不重複則長度加一
count_un = df.iloc[:,0:3].apply(lambda x:len(x.unique())) # 鍊式循環統計總數
# (3) Zero Value(統計每列0值)
np.sum(df.iloc[:,0] == 0) # 第一列資料周遊,等于0的加和
count_zero = df.iloc[:,0:3].apply(lambda x:np.sum(x == 0)) # 鍊式循環統計總數
Debug模式下簡單檢視運作過程
列印結果

2.2 統計描述——均值和中位數
# (4) Mean Values(平均值)
np.mean(df.iloc[:,0]) # 沒有去除缺失值之前的均值
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
np.mean(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]) # 去除缺失值後進行均值計算
df_mean = df.iloc[:,0:3].apply(lambda x:np.mean(x[~np.isin(x,missSet)]))
# (5) Median Values(中位數)
np.median(df.iloc[:,0]) # 沒有去除缺失值之前的中位數
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
np.median(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]) # 去除缺失值後進行中位數計算
df_median = df.iloc[:,0:3].apply(lambda x:np.median(x[~np.isin(x,missSet)]))
Debug模式下簡單檢視運作過程
列印結果
2.3 統計描述——衆數
# (6) Mode Values(衆數)
df_mode = df.iloc[:,0:3].apply(lambda x: stats.mode((x[~np.isin(x,missSet)]))[0][0])
# (7) Mode percentage(衆數的占比)
df_mode_count = df.iloc[:,0:3].apply(lambda x: stats.mode(x[~np.isin(x,missSet)])[1][0])
df_mode_perct = df_mode_count/df.shape[0]
Debug模式下簡單檢視運作過程
列印結果
2.4 統計描述——最大最小值
# (8) Min Values(最小值)
np.min(df.iloc[:,0])
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
np.min(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]) # 去除缺失值最小值計算
df_min = df.iloc[:,0:3].apply(lambda x:np.min(x[~np.isin(x,missSet)]))
# (9) Max Values(最大值)
np.max(df.iloc[:,0])
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
np.max(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)]) # 去除缺失值最大值計算
df_max = df.iloc[:,0:3].apply(lambda x:np.max(x[~np.isin(x,missSet)]))
Debug模式下簡單檢視運作過程
列印結果
2.5 統計描述——分位點
np.percentile(df.iloc[:,0],(1,5,25,50,75,95,99))
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
np.percentile(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)],(1,5,25,50,75,95,99)) # 去除缺失值後分位點計算
Debug模式下簡單檢視運作過程
列印結果
# (10)Quantile Values(分位點)
np.percentile(df.iloc[:,0],(1,5,25,50,75,95,99))
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
np.percentile(df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)],(1,5,25,50,75,95,99)) # 去除缺失值後分位點計算
# 整理結構
json_quantile = {}
for i,name in enumerate(df.iloc[:,0:3].columns):
print('the {} columns: {}'.format(i,name))
json_quantile[name] = np.percentile(df[name][~np.isin(df.iloc[:,0],missSet)],(1,5,25,50,75,95,99))
df_quantile = pd.DataFrame(json_quantile)[df.iloc[:,0:3].columns].T
print(df_quantile)
2.6 統計描述——頻數
df.iloc[:,0].value_counts().iloc[0:5,]
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)] # 去除缺失值
df.iloc[:,0][~np.isin(df.iloc[:,0],missSet)].value_counts().iloc[0:5] # 去除缺失值頻數的計算
json_fre_name = {}
json_fre_count = {}
def fill_fre_top_5(x):
if(len(x)) <= 5:
new_array = np.full(5,np.nan)
new_array[0:len(x)] = x
return new_array
df['ind_var1_0'].value_counts()
df['imp_sal_var16_ult1'].value_counts()
for i,name in enumerate(df[['ind_var1_0','imp_sal_var16_ult1']].columns):
# 1. Index Name
index_name = df[name][~np.isin(df[name],missSet)].value_counts().iloc[0:5,].index.values
# 1.1. If the length of array is less than 5
index_name = fill_fre_top_5(index_name)
json_fre_name[name] = index_name
# 2. Value Count
values_count = df[name][~np.isin(df[name],missSet)].value_counts().iloc[0:5,].values
# 2.1. If the length of array is less than 5
values_count = fill_fre_top_5(values_count)
json_fre_count[name] = values_count
df_fre_name = pd.DataFrame(json_fre_name)[df[['ind_var1_0','imp_sal_var16_ult1']].columns].T
df_fre_count = pd.DataFrame(json_fre_count)[df[['ind_var1_0','imp_sal_var16_ult1']].columns].T
df_fre = pd.concat([df_fre_name,df_fre_count],axis=1)
print(df_fre)
2.7 統計描述——缺失值
np.sum(np.isin(df.iloc[:,0],missSet)) # 統計确實值
df_miss = df.iloc[:,0:3].apply(lambda x:np.sum(np.isin(x,missSet))) # 周遊每一個周遊的缺失值情況
print(df_miss)
3. 資料診斷工具的整合
from __future__ import division
import pandas as pd
import numpy as np
from scipy import stats
def fill_fre_top_5(x):
if(len(x)) <= 5:
new_array = np.full(5,np.nan)
new_array[0:len(x)] = x
return new_array
def eda_analysis(missSet=None, df=None):
if missSet is None:
missSet = [np.nan, 9999999999, -999999]
# 1.Count
count_un = df.apply(lambda x: len(x.unique()))
count_un = count_un.to_frame('count')
# 2.Count Zero
count_zero = df.apply(lambda x: np.sum(x == 0))
count_zero = count_zero.to_frame('count_zero')
# 3.Mean
df_mean = df.apply(lambda x: np.mean(x[~np.isin(x, missSet)]))
df_mean = df_mean.to_frame('df_mean')
# 4.Median
df_median = df.apply(lambda x: np.median(x[~np.isin(x, missSet)]))
df_median = df_median.to_frame('df_median')
# 5.Mode
df_mode = df.apply(lambda x: stats.mode((x[~np.isin(x, missSet)]))[0][0])
df_mode = df_mode.to_frame('df_mode')
# 6.Mode percentage
df_mode_count = df.apply(lambda x: stats.mode(x[~np.isin(x, missSet)])[1][0])
df_mode_count = df_mode_count.to_frame('df_mode_count')
df_mode_perct = df_mode_count / df.shape[0]
df_mode_perct.columns = ['mode_perct']
# 7.Min
df_min = df.apply(lambda x: np.min(x[~np.isin(x, missSet)]))
df_min = df_min.to_frame('df_min')
# 8.Max
df_max = df.apply(lambda x: np.max(x[~np.isin(x, missSet)]))
df_max = df_max.to_frame('df_max')
# 9.Quantile
json_quantile = {}
for i, name in enumerate(df.iloc[:, 0:3].columns):
json_quantile[name] = np.percentile(df[name][~np.isin(df.iloc[:, 0], missSet)], (1, 5, 25, 50, 75, 95, 99))
df_quantile = pd.DataFrame(json_quantile)[df.columns].T
df_quantile.columns = ['Quantile01', ' Quantile05 ', ' Quantile25', ' Quantile50 ', ' Quantile75', ' Quantile95 ', ' Quantile99']
# 10.Frequent
json_fre_name = {}
json_fre_count = {}
for i, name in enumerate(df.columns):
# 1. Index Name
index_name = df[name][~np.isin(df[name], missSet)].value_counts().iloc[0:5, ].index.values
# 1.1. If the length of array is less than 5
index_name = fill_fre_top_5(index_name)
json_fre_name[name] = index_name
# 2. Value Count
values_count = df[name][~np.isin(df[name], missSet)].value_counts().iloc[0:5, ].values
# 2.1. If the length of array is less than 5
values_count = fill_fre_top_5(values_count)
json_fre_count[name] = values_count
df_fre_name = pd.DataFrame(json_fre_name)[df.columns].T
df_fre_count = pd.DataFrame(json_fre_count)[df.columns].T
df_fre = pd.concat([df_fre_name, df_fre_count], axis=1)
df_fre.columns = ['value1','value2','value3','value4','value5','freq1','freq2','freg3','freq4', 'freq5']
# 11.Miss Values Count
df_miss = df.apply(lambda x:np.sum(np.isin(x,missSet)))
df_miss = df_miss.to_frame('df_miss')
# 12.Combine All Information
df_eda_summary = pd.concat([
count_un,count_zero,df_mean,df_median,df_mode,df_mode_count,df_mode_perct,df_min,df_max,df_fre,df_miss
],axis=1)
return df_eda_summary