本文将CNN和NLP結合;
介紹了一系列的對比實驗,實驗結果說明了:
- 一個簡單的(單層神經網絡)的CNN模型
- 一點超參數的調節(Filter的個數)
- static word vector
- 另外,對cnn模型進行了小改動:将static vectors和non static vectors變成cnn模型中的兩個channels,尤如圖像中的rgb三通道。
non-static就是詞向量随着模型訓練變化,這樣的好處是詞向量可以根據資料集做适當調整
static就是直接使用word2vec訓練好的詞向量即可
卷積之後得到的列向量次元也是不同的,可以通過pooling來消除句子之間長度不同的差異
Pre-trained Word Vectors
當手頭上沒有large supervised training dataset的時候,用word2vec(或相似的unsupervised nlp模型得到)初始化word vectors能提高performance。
Model
這是本文的模型,基本也就是CNN的結構
左邊是一個n*k的矩陣,表示一句話的n個詞語,每個詞語是一個k維向量
(這裡word2vec)
然後設定一個滑窗的長度h,用這個滑窗滑過整個矩陣,然後通過下面這個公式的計算,算出h對應的一個特征的向量c
w是權重,b是偏移量
f就是一個非線性函數
(卷積核)
形成這個向量,稱為feature map
我們可以通過改變h的大小,生成很多feature maps
然後對于每個feature map,采取選出這個向量中的最大值,(意在找到最重要的特征)
同時也解決了每個feature map不等長,統一了次元的問題
然後再将這個傳遞到 全連接配接層
這是一個softmax層(因為涉及到句子的分類問題)
輸出的就是對于不同的label的機率分布
資料集相對較小,很容易就會發生過拟合現象
是以這裡引如dropout來減少過拟合現象。
就是産生一定的機率來mask掉一些點
Model Variations
- CNN-rand : 所有的word vector都是随機初始化的,在訓練過程中更新
- CNN-static : word vector用word2vec得出的結果,在整個train process中所有的words保持不變,隻學習其他參數
- CNN-non-static : pretrained vector在訓練過程中要被fine-tuned
- CNN-multichannel : two sets of word vectors. 初始化時兩個channel都直接指派word2vec得出的結果,每個filter也會分别applied到兩個channel,但是訓練過程中隻有一個channel會進行BP
模型中除了這些參數改變,其他參數相同。
模型根據詞向量的不同分為四種:
- CNN-rand,所有的詞向量都随機初始化,并且作為模型參數進行訓練。
- CNN-static,即用word2vec預訓練好的向量(Google News),在訓練過程中不更新詞向量,句中若有單詞不在預訓練好的詞典中,則用随機數來代替。
- CNN-non-static,根據不同的分類任務,進行相應的詞向量預訓練。
- CNN-multichannel,兩套詞向量構造出的句子矩陣作為兩個通道,在誤差反向傳播時,隻更新一組詞向量,保持另外一組不變。
在七組資料集上進行了對比實驗,證明了單層的CNN在文本分類任務中的有效性,同時也說明了用無監督學習來的詞向量對于很多nlp任務都非常有意義。
static模型中word2vec預訓練出的詞向量會把good和bad當做相似的詞,在sentiment classification任務中将會導緻錯誤的結果,而non-static模型因為用了目前task dataset作為訓練資料,不會存在這樣的問題。具體可參看下圖:

關于two channels of word vectors
one channel将word2vec得到的結果直接static的傳入整個模型,另一個channel在BP訓練過程中要進行fine-tune。每一個filter都要分别應用到這兩個channels上。
例如上圖中就能看出,系統有2 filters,對2個channels分别卷積後得到4 stacks。
Regularization
這裡用到了dropout和l2正則項,避免過拟合
dropout就是将pooling之後的結果随機mask一部分值
比如,我們在這裡pooling之後的結果是z,我們将z處理成y之後向前傳遞的時候,
然後我們就做一個 and 操作
每一次梯度下降,調整參數的時候,依靠這個門檻值s來限制中間的參數
Static vs. Non-static Representations
一句話,non-static更适應specific task
Conclusion
CNN在NLP的一個嘗試,并且效果還不錯
說明了,pre-trained的word vector 是deep learning在NLP領域重要的組成部分
神經網絡各層
- 對于文本任務,輸入層自然使用了word embedding來做input data representation。
- 接下來是卷積層,大家在圖像進行中經常看到的卷積核都是正方形的,比如44,然後在整張image上沿寬和高逐漸移動進行卷積操作。但是nlp中輸入的“image”是一個詞矩陣,比如n個words,每個word用200維的vector表示的話,這個”image”就是n200的矩陣,卷積核隻在高度上已經滑動,在寬度上和word vector的次元一緻(=200),也就是說每次視窗滑動過的位置都是完整的單詞,不會将幾個單詞的一部分“vector”進行卷積,這也保證了word作為語言中最小粒度的合理性。(當然,如果研究的粒度是character-level而不是word-level,需要另外的方式處理)
- 由于卷積核和word embedding的寬度一緻,一個卷積核對于一個sentence,卷積後得到的結果是一個vector, shape=(sentence_len - filter_window + 1, 1),那麼,在max-pooling後得到的就是一個Scalar。是以,這點也是和圖像卷積的不同之處,需要注意一下。
- 正是由于max-pooling後隻是得到一個scalar,在nlp中,會實施多個filter_window_size(比如3,4,5個words的寬度分别作為卷積的視窗大小),每個window_size又有num_filters個(比如64個)卷積核。一個卷積核得到的隻是一個scalar太孤單了,智慧的人們就将相同window_size卷積出來的num_filter個scalar組合在一起,組成這個window_size下的feature_vector。
- 最後再将所有window_size下的feature_vector也組合成一個single vector,作為最後一層softmax的輸入。
重要的事情說三遍:一個卷積核對于一個句子,convolution後得到的是一個vector;max-pooling後,得到的是一個scalar。
關于model
- filter windows: [3,4,5]
- filter maps: 100 for each filter window
- dropout rate: 0.5
- l2 constraint: 3
- randomly select 10% of training data as dev set(early stopping)
- word2vec(google news) as initial input, dim = 300
- sentence of length: n, padding where necessary
- number of target classes
- dataset size
- vocabulary size
cnn用在NLP
each row is vector that represents a word. Typically, these vectors are word embeddings (low-dimensional representations) like word2vec or GloVe, but they could also be one-hot vectors that index the word into a vocabulary. For a 10 word sentence using a 100-dimensional embedding we would have a 10×100 matrix as our input. That’s our “image”.
In vision, our filters slide over local patches of an image, but in NLP we typically use filters that slide over full rows of the matrix (words). Thus, the “width” of our filters is usually the same as the width of the input matrix. The height, or region size, may vary, but sliding windows over 2-5 words at a time is typical.

TextCNN詳細過程:第一層是圖中最左邊的7乘5的句子矩陣,每行是詞向量,次元=5,這個可以類比為圖像中的原始像素點了。然後經過有 filter_size=(2,3,4) 的一維卷積層,每個filter_size 有兩個輸出 channel。第三層是一個1-max pooling層,這樣不同長度句子經過pooling層之後都能變成定長的表示了,最後接一層全連接配接的 softmax 層,輸出每個類别的機率。
特征:這裡的特征就是詞向量,有靜态(static)和非靜态(non-static)方式。static方式采用比如word2vec預訓練的詞向量,訓練過程不更新詞向量,實質上屬于遷移學習了,特别是資料量比較小的情況下,采用靜态的詞向量往往效果不錯。non-static則是在訓練過程中更新詞向量。推薦的方式是 non-static 中的 fine-tunning方式,它是以預訓練(pre-train)的word2vec向量初始化詞向量,訓練過程中調整詞向量,能加速收斂,當然如果有充足的訓練資料和資源,直接随機初始化詞向量效果也是可以的。
通道(Channels):圖像中可以利用 (R, G, B) 作為不同channel,而文本的輸入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),實踐中也有利用靜态詞向量和fine-tunning詞向量作為不同channel的做法。
一維卷積(conv-1d):圖像是二維資料,經過詞向量表達的文本為一維資料,是以在TextCNN卷積用的是一維卷積。一維卷積帶來的問題是需要設計通過不同 filter_size 的 filter 擷取不同寬度的視野。
Pooling層:利用CNN解決文本分類問題的文章還是很多的,比如這篇 A Convolutional Neural Network for Modelling Sentences** 最有意思的輸入是在 pooling 改成 (dynamic) k-max pooling ,pooling階段保留 k 個最大的資訊,保留了全局的序列資訊。比如在情感分析場景,舉個例子:
“ 我覺得這個地方景色還不錯,但是人也實在太多了 ”
雖然前半部分展現情感是正向的,全局文本表達的是偏負面的情感,利用 k-max pooling能夠很好捕捉這類資訊。
Pooling Layers
Channels
For example, in image recognition you typically have RGB (red, green, blue) channels. You can apply convolutions across channels,
論文翻譯(谷歌翻譯的結果)
摘要
我們報告了一系列用卷積神經網絡(CNN)進行的實驗,這些實驗訓練了用于句子級别分類任務的預訓練詞語驅動器。 我們展示了一個簡單的CNN,具有極大的參數調節和靜态驅動器,可以在多個基準測試中取得優異的結果。 通過微調學習任務特定的向量可以進一步提高性能。 我們還提出了一個對架構的簡單修改,以允許使用任務特定和靜态向量。 本文讨論的CNN模型改善了7項任務中的4項工作,其中包括情緒分析和問題分類。
介紹
近年來,深度學習模型在計算機視覺(Krizhevsky等,2012)和語音識别(Graves et al。,2013)方面取得了顯着的成果。 在自然語言進行中,大部分深入學習方法的工作涉及到通過神經語言模型學習單詞向量表達(Bengio et al。,2003; Yih et al。,2011; Mikolov et al。,2013 ),并對所學習的詞向量執行分類(Collobert等,2011)。 詞彙向量,其中單詞從稀疏的1-V編碼(這裡V是詞彙大小)經由隐藏層投影到較低次元向量空間上,本質上是對其次元中的單詞的語義特征進行編碼的特征提取器。 在這種密集的表示中,語義上緊密的詞在低維向量空間中同樣是近似的歐幾裡德或餘弦距離。
卷積神經網絡(CNN)利用應用于局部特征的卷積濾波器的層(LeCun等,1998)。 最初為計算機視覺發明,CNN模型随後被證明對NLP有效,在語義解析(Yih et al。,2014),搜尋查詢檢索(Shen et al。,2014),語言模組化(Kalch - brenner et al。,2014)和其他傳統的NLP任務(Collobert等,2011)。
在目前的工作中,我們在從無監督神經語言模型獲得的單詞向量之上訓練一個簡單的CNN卷積卷積。 這些載體由Mikolov等人 (2013年)在Google新聞1000億位元組,并且是公開的。我們最初保持向量靜态,隻學習模型的其他參數。 盡管對超參數進行了很少的調整,但是這種簡單的模型在多個基準上取得了出色的結果,表明預先訓練的矢量是可以用于各種分類任務的“通用”特征輸出器。 通過微調學習任務特定的向量可以進一步改進。 我們最後描述了對架構的簡單修改,以允許通過具有多個通道來使用預訓練和任務特定向量。
我們的工作在哲學上與Razavian等人相似 (2014)顯示,對于圖像分類,從預先訓練的深度學習模型獲得的特征提取器在各種任務上表現良好 - 包括與原始任務不同的任務,特征提取器 受過訓練
Model
如圖1所示的模型架構是Collobert等人的CNN架構的一個輕微變體。(2011年)。 令xi∈Rk是對應于句子中第i個詞的k維字向量。 長度為n(需要填充)的句子表示為x1:n =x1⊕x2⊕…⊕xn,
其中⊕是級聯算子。 一般來說,令xi:i + j是指xi,xi + 1,…的連接配接。。。 ,xi + j。 卷積運算涉及一個濾波器∈Rhk,該濾波器應用于h字的視窗以産生新的特征。 例如,從單詞xi:i + h-1的視窗生成特征ci
這裡b∈R是偏置項,f是諸如雙曲正切之類的非線性函數。 該過濾器應用于句子{x1:h,x2:h + 1,…中的每個可能的單詞視窗。。。 ,xn-h + 1:n}以産生特征圖
其中c∈Rn-h + 1。 然後,我們然後在特征圖上應用最大逾時池操作(Collobert等,2011),并将最大值c = max {c}作為與該特定過濾器對應的特征。 這個想法是為每個特征圖捕獲最重要的功能 - 具有最高價值的特征。 這種彙總方案自然地處理可變句長度。
我們描述了從一個過濾器中提取一個特征的過程。 該模型使用多個過濾器(具有不同的視窗大小)來獲得多個功能。 這些特征形成倒數第二層,并傳遞給完全連接配接的softmax層,其輸出是标簽上的機率分布。
在其中一個模型變體中,我們嘗試使用兩個“向量通道”,一個在訓練中保持靜态,另一個通過反向傳播進行微調(第3.2節).2在多通道架構中,如圖1所示 ,将每個濾波器應用于兩個通道,并将結果加到計算公式(2)中的ci。 該模型在其他方面相當于單通道架構。
Regularization
為了正規化,我們在倒數第二層上采用辍學,對權重向量的l2範數有限制(Hinton et al。,2012)。 辍學可以防止隐藏單元随機退出的共同适配,即在後置傳播過程中隐藏單元的設定為零。 也就是說,給定倒數第二層z = [c1,...,cm](注意這裡我們有m個濾波器),而不是使用
用于正向傳播中的輸出單元y,dropout使用
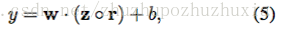
其中◦是元素乘法運算符,r∈Rm是機率p為1的伯努利随機變量的“掩蔽”向量。僅通過未屏蔽機關反向傳播漸變。 在測試時間,所學習的權重向量按p進行縮放,使得w = pw,并且使用w(不丢失)來評估不可見的靈敏度。 我們另外通過在梯度下降步驟之後,當|| w || 2> s重新縮放w以使|| w || 2 = s限制權重向量的l2正則。
Datasets and Experimental Setup資料集和實驗設定
MR:每次評論一個句子的電影評論。 分類涉及檢測陽性/陰性評估(Pang和Lee,2005)
SST-1:斯坦福情報樹組織 - MR的擴充,但提供火車/ dev /測試分裂和細粒度标簽(非常有意義,積極,中立,消極,非常負面),由Socher et人。(2013)0.4
SST-2:與SST-1相同,但中性回複被删除,二進制标簽。
•Subj:主觀性資料集,其任務是将句子分類為主觀或客觀的(Pang和Lee,2004)。
•TREC:TREC問題資料集 - 任務将問題分為6個問題類型(問題是關于人,地點,數字資訊等)(Li和Roth,2002).5
•CR:各種産品(相機,MP3等)的客戶評價。 任務是預測潛在/負面評價(胡和劉,2004)
•MPQA:MPQA資料集的意見極性檢測子任務(Wiebe et al。,2005).7
Hyperparameters and Training超參和訓練
對于我們使用的所有資料集:整流線性機關,濾波器視窗(h)為3,4,5,每個具有100個特征圖,辍學率(p)為0.5,l2限制(s)為3,小批量為50 這些值是通過SST-2開發集上的網格搜尋來選擇的。
除了早期停止開發集之外,我們不會執行任何資料集特定的調優。 對于沒有标準開發集的資料集,我們随機選擇10%的教育訓練資料作為開發集dev。 訓練是通過Addersta更新規則(Zeiler,2012)随機降級的混合小批量完成的。
Pre-trained Word Vectors
使用從無監督神經語言模型獲得的詞矢量初始化是一種流行的方法,在沒有大型監督訓練集的情況下提高性能(Collobert等,2011; Socher等,2011; Iyyer等,2014)。 我們使用公開提供的word2vec向量,這些向量來自Google新聞1000億字。 載體的維數為300,并使用連續的詞彙架構進行訓練(Mikolov等,2013)。 在一組預訓練詞中不存在的詞被随機地初始化。
Model Variations
我們嘗試模型的幾個變體。
•CNN-rand:我們的基準模型,其中所有單詞随機初始化,然後在訓練過程中進行修改。
•CNN-static:具有來自word2vec的預訓練矢量的模型。 所有的單詞 - 包括未知的 - 被初始化的單詞 - 保持靜态,隻有模型的其他參數被學習。
•CNN非靜态:與上述相同,但對每個任務進行微調。
•CNN多通道:具有兩組字矢量的模型。 每組向量被視為“通道”,每個濾波器都應用于兩個通道,但梯度隻能通過其中一個通道進行反向傳播。 是以,該模型能夠微調一組向量,同時保持其他靜态。 兩個通道都用word2vec初始化。
為了解決上述變化與其他随機因素的影響,我們消除了其他随機因素 - CV-折疊簽名,初始化未知字向量,初始化CNN參數 - 通過保持均勻 在每個資料集内。
Results and Discussion
我們的模型與其他方法的結果列于表2.我們的基準模型與所有随機初始化的單詞(CNN-rand)本身并不完美。 雖然我們通過使用預訓練的駕駛員來預期性能上的提升,但是我們對增益的幅度感到驚訝。 即使是一個具有靜态向量(CNN靜态)的簡單模型也表現得非常出色,對于采用複雜的池計劃(Kalchbrenner et al。,2014)的更複雜的深度學習模型,或提前計算解析樹, Socher等,2013)。 這些結果表明,預先訓練的矢量是好的,“普遍”的特征提取器,可以跨資料集使用。 對每個任務的預訓練矢量進行微調給出了進一步的改進(CNN非靜态)。
Multichannel vs. Single Channel Models
我們最初希望多通道架構可以防止過度拟合(通過確定所學習的矢量不會偏離原始值),是以比單通道模型更好,特别是在較小的資料集上。 然而,結果是混合的,并且有必要進一步調整微調過程的正确性。 例如,不是為非靜态部分使用附加通道,而是可以保持單個通道,但是需要在訓練期間允許修改的額外尺寸。
Static vs. Non-static Representations
與單通道非靜态模型的情況一樣,多通道模型能夠微調非靜态通道,使其更具體于手頭任務。 例如,良好與word2vec中的差異最相似,大概是因為它們(幾乎)在文法上相當。 但是對于在SST-2資料集中進行了微調的非靜态通道中的向量,情況就不再這樣了(表3)。 同樣,好的可以說是更接近于善于表達情感的偉大,這确實展現在學習的向量中。
對于不經過預訓練矢量集的(随機初始化)标記,微調使他們能夠學習更有意義的表示:網絡學習感歎号與流行表達相關聯,并且逗号是連接配接的(表3)。
Further Observations
我們報告一些進一步的實驗和觀察:
•Kalchbrenner et al。 (2014)報道,CNN的結構與我們的單通道模型基本相同。 例如,具有随機初始化字的Max-TDNN(時間延遲神經網絡)在SST-1資料集上獲得了37.4%,而我們的模型則為45.0%。 我們将這種差異歸因于我們的CNN具有更多的容量(多個濾波器寬度和特征圖)。
•辍學被證明是一個很好的正規者,使用更大的必要網絡是很好的,隻是讓辍學正規化。 辍學一直增加了2%-4%的相對性能。
當随機初始化word2vec中的單詞時,我們通過從U [-a,a]中抽取每個次元來獲得輕微的改進,其中a被選擇為使得随機初始化的向量與預先訓練的向量具有相同的方差。 有趣的是,如果使用更複雜的方法來反映初始化過程中預先訓練的矢量的分布,将進一步改進。
•我們簡要地嘗試了由Collobert等人訓練的另外一組可公開提供的字向量。 (2011)維基百科8,發現word2vec具有更高的性能。 不清楚這是由于Mikolov等人 (2013)的架構或1000億字Google新聞資料集。
•Adadelta(Zeiler,2012)給出了與Adagrad類似的結果(Duchi et al。,2011),但需要更少的時期。
結論
在目前的工作中,我們已經描述了在word2vec之上建構的卷積神經網絡的一系列實驗。 盡管很少調整超參數,但是具有一層卷積的簡單的CNN執行得非常好。 我們的結果增加了明确的證據,即不受監督的字矢量預訓練是NLP深入學習的重要組成部分。