首先講一下背景,公司現在要做流式,最後敲定用flink來做(考慮flink在阿裡的巨大成功)。我們的資料讀取Kafka ,經過處理之後會存儲到ES中。現在還處在研究階段,把一些基本的東西跑通,寫這篇部落格希望做一個記錄 也希望能給剛開始搞flinkd 朋友們一點幫助。
用到的技術:flink on yarn (1.7.0) kafka(1.1.1) es(1.7) maven(3.04) 我用idea編輯器 scala(2.11)語言寫的 flink 本地也是可以跑的 沒有hadoop叢集的小夥伴可以在本地測試
package info
import java.util.Properties
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.state.StateTtlConfig.TimeCharacteristic
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.elasticsearch.{ElasticsearchSink, ElasticsearchSinkFunction}
import org.elasticsearch.action.index.IndexRequest
import org.elasticsearch.client.Requests
import org.elasticsearch.common.transport.{InetSocketTransportAddress, TransportAddress}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer010}
object Test03 {
def main(args: Array[String]) {
//擷取flink執行環境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// env.enableCheckpointing(5000)
val config = new java.util.HashMap[String, String]
config.put("cluster.name", "elasticsearch1")
// 加上這個條件 按每個事件處理 不加會走buff
config.put("bulk.flush.max.actions", "1")
env.enableCheckpointing(1000)
val transportAddresses = new java.util.ArrayList[TransportAddress]
transportAddresses.add(new InetSocketTransportAddress("ESIp", 9300))
val properties: Properties = new Properties();
properties.setProperty("bootstrap.servers","kafkaIp:9092")
properties.setProperty("zookeeper.connect","zookeeperIp:2181")
properties.put("auto.offset.reset", "earliest")
properties.put("enable.auto.commit", "true")
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("group.id","testgroup12")
val kafkaConsumer = new FlinkKafkaConsumer010(
"test2",//topic
new SimpleStringSchema,
properties)
val messageStream = env
.addSource(kafkaConsumer)
messageStream.print()
messageStream.addSink(new ElasticsearchSink(config,transportAddresses,new ElasticsearchSinkFunction[String](){
def createIndexRequest(element: String): IndexRequest = {
val json = new java.util.HashMap[String, String]
json.put("data", element)
Requests.indexRequest()
.index("fktest")
.`type`("streaming")
.source(json)
}
import org.apache.flink.api.common.functions.RuntimeContext
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer
def process(element:String,ctx: RuntimeContext,indexer: RequestIndexer):Unit= {
indexer.add(createIndexRequest(element))
}
}))
env.execute("StreamESTest")
}
}
在idea 中啟動代碼 然後再kafka的機器上 起一個生産者 輸入一些資料 看能否出結果
起生産者指令: %KAFKA_HOME%/bin/kafka-console-producer.sh --broker-list 1 kafkaIp:9092 --topic test2
ES中查詢出的資料
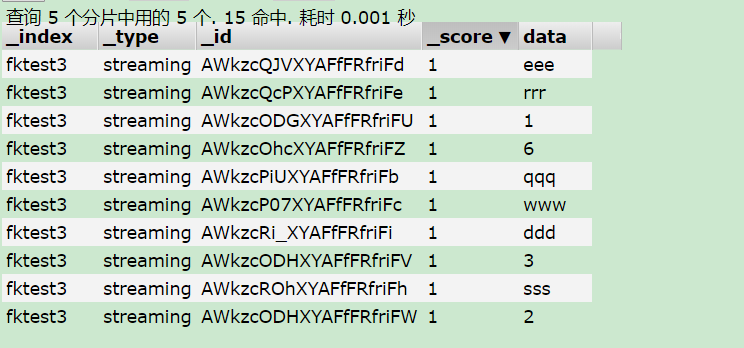
看到這個結果出來 基本上kafka-flink-es 就通了
![kafka使用筆記-librdkafka支援sasl認證[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)