EIE為韓松博士在ISCA 2016上的論文。實作了壓縮的稀疏神經網絡的硬體加速。與其近似方法的ESE獲得了FPGA2017的最佳論文。
目錄
一、背景與介紹
1.1 Motivation
1.2 前期工作
1.3 貢獻點
二、方法
2.1 公式描述
神經網絡的基本運算
對于神經元的運算
Deep compression後的公式
查表與值
2.2 矩陣表示(重要)
三、硬體實作
3.1 CCU與PE
3.2 Activation Queue and Load Balancing
3.3 Pointer Read Unit
3.4 Sparse Matrix Read Unit
3.5 Arithmetic Unit
3.6 Activation Read/Write
3.7 Distributed Leading Non-Zero Detection
3.8 Central Control Unit(CCU)
3.9 布局情況
四、實驗情況
4.1 速度與功耗
4.2 負載平衡中FIFO隊列的長度
4.3 SRAM的位寬度
4.4 運算精度
4.5 并行PE數對速度的提升
4.6 與同類工作的對比
五、重要資訊總結
平台為ASIC
重要貢獻
運算吞吐量
一、背景與介紹
1.1 Motivation
最新的DNN模型都是運算密集型和存儲密集型,難以硬體部署。
1.2 前期工作
Deep compression 通過剪枝,量化,權值共享等方法極大的壓縮了模型。Deep compression解析見下連結
https://blog.csdn.net/weixin_36474809/article/details/80643784
1.3 貢獻點
- 提出了EIE (Efficient Inference Engine)的方法,将壓縮模型應用與硬體。
- 對于壓縮網絡來說,EIE可以帶來120 GOPS/s 的處理效率,相當于同等未壓縮的網絡 3TGOP/s的處理效率。(AlexNet需要1.4GOPS,ResNet-152需要22.6GOPS)
- 比CPU和GPU帶來24000x和3400x的功率提升。
- 比CPU,GPU和Mobile GPU速度快189x, 13x,307x
二、方法
2.1 公式描述
神經網絡的基本運算
對于神經網絡中的一個Fc層,相應的運算公式是下面的:
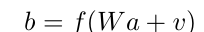
其中,a為輸入,v為偏置,W為權重,f為非線性的映射。b為輸出。此公式即神經網絡中的最基本操作。
對于神經元的運算
針對每一個具體的神經元,上面的公式可以簡化為下面這樣:

輸入a與權重矩陣W相乘,然後進行激活,輸出為b
Deep compression後的公式
Deep compression将相應的權重矩陣壓縮為一個稀疏的矩陣,将權值矩陣Wij壓縮為一個稀疏的4比特的Index Iij,然後共享權值存入一個表S之中,表S有16種可能的權值。是以相應的公式可以寫為:
即位置資訊為i,j,非零值可以通過Iij找到表S中的位置恢複出相應的權值。
查表與值
權值的表示過程經過了壓縮。即CSC與CRC的方法找到相應的權值,即
具體可以參考Deep compression或者網上有詳細的講解。
https://blog.csdn.net/weixin_36474809/article/details/80643784
例如上面的稀疏矩陣A。我們将每一個非零值存下來在AA中。
JA表示換行時候的第一個元素在AA中的位置。例如A中第二列第一個元素在A中為第四個,第3行元素在A中為第6個。
IC為對應AA每一個元素的列。這樣通過這樣一個矩陣可以很快的恢複AA表中的行和列。
2.2 矩陣表示(重要)
這是一個稀疏矩陣相乘的過程,輸入向量a,乘以矩陣W,輸出矩陣為b,然後經過了ReLU。
用于實作相乘累加的單元稱為PE,相同顔色的相乘累加在同一個PE中實作。例如上面綠色的都是PE0的責任。則PE0隻需要存下來權值的位置和權值的值。是以上面綠色的權值在PE0中的存儲為下面這樣:
通過CSC存儲,我們可以很快看出virtual weight的值。(CSC不懂見上一節推導)。行标與元素的行一緻,列标可以恢複出元素在列中的位置。
向量a可以并行的傳入每個PE之中,0元素則不并行入PE,非零元素則同時進入每一個PE。若PE之中對應的權重為0,則不更新b的值,若PE之中對應的權重非零,則更新b的值。
三、硬體實作
3.1 CCU與PE
CCU(Central control unit中央控制器)用于查找非零值,廣播給PE(Processing Element處理單元,可以并行的單元,也是上文中的PE)。上圖a為CCU,b為單個PE
PE即上面算法中的PE單元, 實作将CCU廣播過來的資料進行卷積的相乘累加和ReLU激活。下面為每個具體單元的作用。
3.2 Activation Queue and Load Balancing
資料序列與負載平衡
上圖之中的連接配接PE與CCU之間的序列。如果CCU直接将資料廣播入PE,則根據木桶短闆效應,最慢的PE是所有PE的時間的時長。
是以我們在每個PE之前設定一個隊列,用于存儲,這樣PE之間不同同步,隻用處理各自隊列上的值。
- 隻要隊列未滿,CCU就向PE的隊列廣播資料
- 隻要隊列之中有值,PE就處理隊列之中的值
這樣,PE之間就能最大限度的處理資料。
3.3 Pointer Read Unit
根據目前需要運算的行與列生成相應的指針傳入稀疏矩陣讀取單元。運用目前的列j(CCU傳來的資料是資料和資料的列j)來生成相應的指針pj(此指針用于給Sparse Matrix Read Unit來讀取對應的權值)
3.4 Sparse Matrix Read Unit
根據前面傳入的指針值,從稀疏矩陣的存儲之中讀取出權重。即用前面傳來的指針pj讀取權重v,并将資料x一并傳給ArithMetic Unit。即傳給Arithmetic Unit的值為(v,x)
3.5 Arithmetic Unit
進行卷積之中的權重與feature相乘,然後累加的操作。從前面Sparse Matrix Read Unit中讀出相乘得兩個值,從後面的 Act R/W中讀出偏移和加上後結果寫入。
3.6 Activation Read/Write
取出偏置給Arithmetic Unit并且将Arithmetic Unit運算之後的結果傳給激活ReLU層。即實作+bx的過程和傳給最終結果給ReLU
3.7 Distributed Leading Non-Zero Detection
LNZD node,用于寫入每層計算feature,下一層計算的時候直接傳給CCU到下一層。在寫入過程直接寫入,運算過程可以探測非零值然後傳給CCU。
這個因為神經網絡計算方式,本層計算結果作為下一層的計算輸入,激活神經元要被分發到多個PE裡乘以不同的權值(神經網絡計算中,上一層的某個神經元乘以不同的權值并累加,作為下一層神經元),Leading非零值檢測是說檢測東南西北四個方向裡第一個不為0(激活)的神經元,就是每個PE都接受東南西北4個方向來的輸入,這4個輸入又分别是其他PE的輸出,是需要計算的,那我這個PE計算時取哪個方向來的資料呢?用LNZD判斷,誰先算完就先發射誰,盡量占滿流水線。
PE之間用H-tree結構,可以保證PE數量增加時布線長度以log函數增長(增長最緩慢的形式)
3.8 Central Control Unit(CCU)
用于将LZND子產品之中的值取出來然後傳入PE的隊列之中。
IO模式:當所有PE空閑的時候, the activations and weights in every PE can be accessed by a DMA connected with the Central Unit
運算模式:從LZND子產品之中,取出相應的非零值傳入PE的隊列之中。
3.9 布局情況
作者運用台積電TSMC的45nm的處理器。上圖為單個PE的布局情況。
表II為各個子產品的功率消耗與區域占用情況。(其實我們看出,主要的功率消耗和區域占用在于稀疏矩陣讀取單元SpmatRead,而不是直覺上的運算單元ArithmUnit)
四、實驗情況
實作平台
作者運用Verilog将EIE實作為RTL,synthesized EIE using the Synopsys Design Compiler (DC) under the TSMC 45nm GP standard VT library with worst case PVT corner. 運用台積電45nm和最差的PVT corner。作者用較差的平台來展現壓縮及設計帶來的資料提升。
We placed and routed the PE using the Synopsys IC compiler (ICC).We annotated the toggle rate from the RTL simulation to the gate-level netlist, which was dumped to switching activity interchange format (SAIF), and estimated the power using Prime-Time PX.
4.1 速度與功耗
運算平台:不同顔色是不同架構的運算平台,如CPU為Intel core i7 5930k,GPU為NVIDIA GeForce GTX Titan X,mobilt GPU為NVIDIA的cuBLAS GEMV。我們看到EIE起到了最快的效果。
運作的神經網絡:如下:
運作時間見下表
4.2 負載平衡中FIFO隊列的長度
負載平衡見3.2 ,FIFO為先進先出隊列,用于存儲CCU發來的資料給PE進行處理。FIFO越長越利于負載平衡
因為每個PE分得的是否為稀疏的數量為獨立同分布的,是以FIFO越長,其總和的方差越小。是以增大FIFO會有利于PE之間的負載平衡。
4.3 SRAM的位寬度
SRAM的位寬度接口,位寬越寬則擷取資料越快,讀取資料次數越少(下圖綠線),但是會增大功耗(藍色條)。如下圖:
總體的能量消耗需要兩者相乘,如下:
4.4 運算精度
作者運用的是16bit定點運算。會比32bit浮點減少6.2x的功率消耗,但是會降低精度。
4.5 并行PE數對速度的提升
4.6 與同類工作的對比
内容較多,感興趣自行檢視原文。
五、重要資訊總結
平台為ASIC
EIE的platform Type為ASIC(專門目的定制內建電路)。現在的大部分ASIC設計都是以半定制和FPGA形式完成的。半定制和FPGA可程式設計ASIC設計的元件成本比較:CBIC元件成本IC價格的2-5倍。但是半定制ASIC必須以數量取勝,否者,其設計成本要遠遠大于FPGA的設計成本。
重要貢獻
速率和功耗。例如9層全連接配接層之中,
- 速率比CPU,GPU,mobile GPU速率快了189x,13x,307x,
- 功率降低24000x,3400x,2700x
運算吞吐量
稀疏網絡達到102 GOPS/s,相當于未壓縮的網絡 3TOPS/s