與 RDD 類似,DStream 也提供了自己的一系列操作方法,這些操作可以分成 3 類:普通的轉換操作、視窗轉換操作和輸出操作。
普通的轉換操作
普通的轉換操作如表 1 所示
| Suo | 描述 |
|---|---|
| map(func) | 源 DStream 的每個元素通過函數 func 傳回一個新的 DStream。 |
| flatMap(func) | 類似于 map 操作,不同的是,每個輸入元素可以被映射出 0 或者更多的輸出元素 |
| filter(func) | 在源 DStream 上選擇 func 函數的傳回值僅為 true 的元素,最終傳回一個新的 DStream。 |
| repartition(numPartitions) | 通過輸入的參數 numPartitions 的值來改變 DStream 的分區大小 |
| union(otherStream) | 傳回一個包含源 DStream 與其他 DStream 的元素合并後的新 DStream |
| count() | 對源 DStream 内部所含有的 RDD 的元素數量進行計數,傳回一個内部的 RDD 隻包含一個元素的 DStream |
| reduce(func) | 使用函數 func(有兩個參數并傳回一個結果)将源 DStream 中每個 RDD 的元素進行聚合操作,傳回一個内部所包含的 RDD 隻有一個元素的新 DStream |
| countByValue() | 計算 DStream 中每個 RDD 内的元素出現的頻次并傳回新的 DStream(<K,Long>),其中,K 是 RDD 中元素的類型,Long 是元素出現的頻次 |
| reduceByKey(func,[numTasks]) | 當一個類型為 <K,V> 鍵值對的 DStream 被調用的時候,傳回類型為鍵值對的新 DStream,其中每個鍵的值 V 都是使用聚合函數 func 彙總的。可以通過配置 numTasks 設定不同的并行任務數 |
| join(otherStream,[numTasks]) | 當被調用類型分别為 <K,V> 和 <K,W> 鍵值對的兩個 DStream 時,傳回一個類型為 <K,<V,W>> 鍵值對的新 DStream |
| cogroup(otherStream,[numTasks]) | 當被調用的兩個 DStream 分别含有 <K,V> 和 <K,W>鍵值對時,傳回一個 <K,Seq[V],seq[W]> 類型的新的 DStream |
| transform(func) | 通過對源 DStream 的每個 RDD 應用 RDD-to-KDD 函數,傳回一個新的 DStream,這可以用來在 DStream 中做任意 RDD 操作 |
| updateStateByKey(func) | 傳回一個新狀态的 DStream,其中每個鍵的新狀态是基于前一個狀态和其新值通過函數 func 計算得出的。這個方法可以被用來維持每個鍵的任何狀态資料 |
在表 1 列出的操作中,transform(func) 方法和 updateStateByKey(fhnc) 方法值得再深入地探讨一下。
1. transform(func) 方法
transform 方法及類似的 transformWith(func) 方法允許在 DStream 上應用任意 RDD-to-RDD 函數,它們可以被應用于未在 DStream API 中暴露的任何 RDD 操作中。
例如,每批次的資料流與另一資料集的連接配接功能不能直接暴露在 DStream API 中,但可以輕松地使用 transform(func) 方法來做到這一點,這使得 DStream 的功能非常強大。
例如,可以通過連接配接預先計算的垃圾郵件資訊的輸入資料流,來做實時資料清理的篩選。事實上,也可以在 transform(func) 方法中使用機器學習和圖形計算的算法。
2. updateStateByKey(func) 方法
updateStateByKey(func) 方法可以保持任意狀态,同時允許不斷有新的資訊進行更新。要使用此功能,必須進行以下兩個步驟。
1)定義狀态:狀态可以是任意的資料類型。
2)定義狀态更新函數:用一個函數指定如何使用先前的狀态和從輸入流中擷取的新值更新狀态。
用一個例子來說明,假設要進行文本資料流中單詞計數。在這裡,正在運作的計數是狀态而且它是一個整數。更新功能定義如下。
def updateFunction(newValues : seq[Int], runningCount:option[Int]);
Option[Int] = {
val newCount = … //給前序 runningCount 添加新值,擷取新 count
Some(newCount)
}
此函數應用于含有鍵值對的 DStream 中(例如,在前面的單詞計數示例中,在 DStream 含有 <word,1> 鍵值對)。它會針對裡面的每個元素(如 WordCount 中的 Word)調用更新函數,其中,newValues 是最新的值,runningCount 是之前的值。
val runningCounts = pairs.updateStateByKey[Int](updateFunction._)
視窗轉換操作
Spark Streaming 還提供了視窗的計算,它允許通過滑動視窗對資料進行轉換,視窗轉換操作如表 2 所示
| 轉換 | 描述 |
|---|---|
| window(windowLength,slideInterval) | 傳回一個基于源 DStream 的視窗批次計算得到新的 DStream |
| countByWindow(windowLength,slideInterval) | 傳回基于滑動視窗的 DStream 中的元素的數量 |
| reduceByWindow(func,windowLength,slideInterval) | 基于滑動視窗對源 DStream 中的元素進行聚合操作,得到一個新的 DStream |
| reduceByKeyAndWindow(func,windowLength,slideInterval,[numTasks]) | 基于滑動視窗對 <K,V> 鍵值對類型的 DStream 中的值按 K 使用聚合函數 func 進行聚合操作,得到一個新的 DStream |
| reduceByKeyAndWindow(func,invFunc,windowLength,slideInterval,[numTasks]) | 一個更高效的實作版本,先對滑動視窗中新的時間間隔内的資料進行增量聚合,再移去最早的同等時間間隔内的資料統計量。 例如,計算 t+4 秒這個時刻過去 5 秒視窗的 WordCount 時,可以将 t+3 時刻過去 5 秒的統計量加上 [t+3,t+4] 的統計量,再減去 [t-2,t-1] 的統計量,這種方法可以複用中間 3 秒的統計量,提高統計的效率 |
| countByValueAndWindow(windowLength,slideInterval,[numTasks]) | 基于滑動視窗計算源 DStream 中每個 RDD 内每個元素出現的頻次,并傳回 DStream[<K,Long>],其中,K 是 RDD 中元素的類型,Long 是元素頻次。Reduce 任務的數量可以通過一個可選參數進行配置 |
在 Spark Streaming 中,資料處理是按批進行的,而資料采集是逐條進行的,是以在 Spark Streaming 中會先設定好批處理間隔,當超過批處理間隔的時候就會把采集到的資料彙總起來成為一批資料交給系統去處理。
對于視窗操作而言,在其視窗内部會有 N 個批處理資料,批處理資料的大小由視窗間隔決定,而視窗間隔指的就是視窗的持續時間。
在視窗操作中,隻有視窗的長度滿足了才會觸發批資料的處理。除了視窗的長度,視窗操作還有另一個重要的參數,即滑動間隔,它指的是經過多長時間視窗滑動一次形成新的視窗。滑動間隔預設情況下和批次間隔相同,而視窗間隔一般設定得要比它們兩個大。在這裡必須注意的一點是,滑動間隔和視窗間隔的大小一定得設定為批處理間隔的整數倍。
如圖 1 所示,批處理間隔是 1 個時間機關,視窗間隔是 3 個時間機關,滑動間隔是 2 個時間機關。對于初始的視窗(time 1~time 3),隻有視窗間隔滿足了才會觸發資料的處理。
這裡需要注意,有可能初始的視窗沒有被流入的資料撐滿,但是随着時間的推進/視窗最終會被撐滿。每過 2 個時間機關,視窗滑動一次,這時會有新的資料流入視窗,視窗則移去最早的 2 個時間機關的資料,而與最新的 2 個時間機關的資料進行彙總形成新的視窗(time 3~ time 5)。
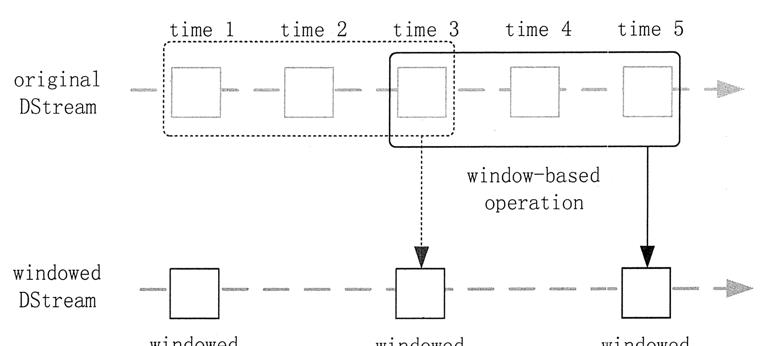
圖 1 DStream的批處理間隔示意
對于視窗操作,批處理間隔、視窗間隔和滑動間隔是非常重要的 3 個時間概念,是了解視窗操作的關鍵所在。
輸出操作
Spark Streaming 允許 DStream 的資料被輸出到外部系統,如資料庫或檔案系統。輸出操作實際上使 transformation 操作後的資料可以被外部系統使用,同時輸出操作觸發所有 DStream 的 transformation 操作的實際執行(類似于 RDD 操作)。表 3 列出了目前主要的輸出操作。
| 轉換 | 描述 |
|---|---|
| print() | 在 Driver 中列印出 DStream 中資料的前 10 個元素 |
| saveAsTextFiles(prefix,[suffix]) | 将 DStream 中的内容以文本的形式儲存為文本檔案,其中,每次批處理間隔内産生的檔案以 prefix-TIME_IN_MS[.suffix] 的方式命名 |
| saveAsObjectFiles(prefix,[suffix]) | 将 DStream 中的内容按對象序列化,并且以 SequenceFile 的格式儲存,其中,每次批處理間隔内産生的檔案以 prefix—TIME_IN_MS[.suffix]的方式命名 |
| saveAsHadoopFiles(prefix,[suffix]) | 将 DStream 中的内容以文本的形式儲存為 Hadoop 檔案,其中,每次批處理間隔内産生的檔案以 prefix-TIME_IN_MS[.suffix] 的方式命名 |
| foreachRDD(func) | 最基本的輸出操作,将 func 函數應用于 DStream 中的 RDD 上,這個操作會輸出資料到外部系統,例如,儲存 RDD 到檔案或者網絡資料庫等。需要注意的是,func 函數是在該 Streaming 應用的 Driver 程序裡執行的 |
dstream.foreachRDD 是一個非常強大的輸出操作,它允許将資料輸出到外部系統。但是,如何正确高效地使用這個操作是很重要的,下面來講解如何避免一些常見的錯誤。
通常情況下,已經為大家精心準備了大資料的系統學習資料,從Linux-Hadoop-spark-......,需要的小夥伴可以點選将資料寫入到外部系統需要建立一個連接配接對象(如 TCP 連接配接到遠端伺服器),并用它來發送資料到遠端系統。出于這個目的,開發者可能在不經意間在 Spark Driver 端建立了連接配接對象,并嘗試使用它儲存 RDD 中的記錄到 Spark Worker 上,代碼如下。
dstream.foreachRDD { rdd =>
val connection = createNewConnection() //在 Driver 上執行
rdd.foreach { record =>
connection.send(record) // 在 Worker 上執行
}
}
這是不正确的,這需要連接配接對象進行序列化并從 Driver 端發送到 Worker 上。連接配接對象很少在不同機器間進行這種操作,此錯誤可能表現為序列化錯誤(連接配接對不可序列化)、初始化錯誤(連接配接對象需要在 Worker 上進行初始化)等,正确的解決辦法是在 Worker 上建立連接配接對象。
通常情況下,建立一個連接配接對象有時間和資源開銷。是以,建立和銷毀的每條記錄的連接配接對象都可能會導緻不必要的資源開銷,并顯著降低系統整體的吞吐量。
一個比較好的解決方案是使用 rdd.foreachPartition 方法建立一個單獨的連接配接對象,然後将該連接配接對象輸出的所有 RDD 分區中的資料使用到外部系統。
還可以進一步通過在多個 RDDs/batch 上重用連接配接對象進行優化。一個保持連接配接對象的靜态池可以重用在多個批處理的 RDD 上,進而進一步降低了開銷。
需要注意的是,在靜态池中的連接配接應該按需延遲建立,這樣可以更有效地把資料發送到外部系統。另外需要要注意的是,DStream 是延遲執行的,就像 RDD 的操作是由 Actions 觸發一樣。預設情況下,輸出操作會按照它們在 Streaming 應用程式中定義的順序逐個執行。
持久化
與 RDD 一樣,DStream 同樣也能通過 persist() 方法将資料流存放在記憶體中,預設的持久化方式是 MEMORY_ONLY_SER,也就是在記憶體中存放資料的同時序列化資料的方式,這樣做的好處是,遇到需要多次疊代計算的程式時,速度優勢十分的明顯。
而對于一些基于視窗的操作,如 reduceByWindow、reduceByKeyAndWindow,以及基于狀态的操作,如 updateStateBykey, 其預設的持久化政策就是儲存在記憶體中。
對于來自網絡的資料源(Kafka、Flume、Sockets 等),預設的持久化政策是将資料儲存在兩台機器上,這也是為了容錯性而設計的。
![一道某高大上網際網路公司的筆試題分享[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)