python網絡爬蟲與資訊提取
學習視訊連結:
https://www.icourse163.org/learn/BIT-1001870001?tid=1464881473#/learn/announce
知識點:
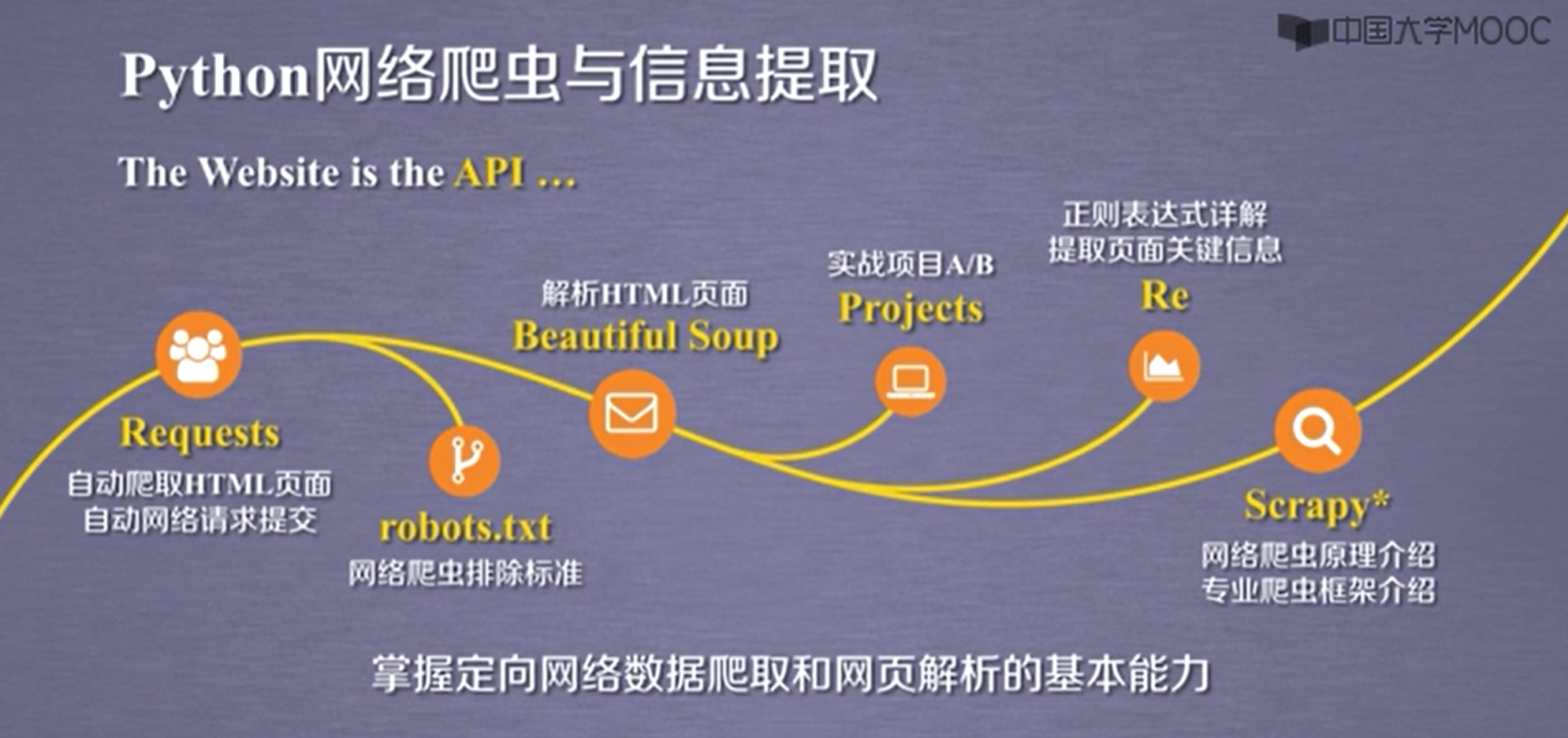
工具:

一、網絡爬蟲之規則
1.requests庫入門
安裝requests庫
request庫的7個主要方法
-
requests.request()
-
requests.get()
-
requests.post()
-
requests.head()
-
requests.put()
-
requests.patch()
-
requests.delete()
後面六個方法調用第一個方法實作的
get方法:
url:拟擷取頁面的url連結
params:url中的額外參數,字典或位元組流格式,可選
**kwargs:12個控制通路的參數
Response對象
包含爬蟲傳回的内容
Response對象的屬性:
-
r.status_code
-
r.text http
-
r.encoding
-
r.apparent_encoding
-
r.content
了解編碼:
r.encoding:如果header中不存在charset,則認為編碼為ISO-8859-1,但不能解析中文。
r.apparent_encoding:根據網頁内容分析編碼格式
Request庫的異常:
requests.ConnectionError:網絡連接配接異常,如DNS查詢失敗,拒絕連接配接
requests.HTTPError:HTTP連接配接異常
requests.URLRequired:URL缺失異常
requests.TooManyRequests:超過最大重定向次數,産生重定向異常
requests.ConnectTimeout:連接配接遠端伺服器逾時異常(僅指連接配接)
requests.Timeout 請求URL逾時,産生逾時異常,(發出URL請求到獲得整個内容)
r.raise_for_status()
能夠判斷狀态碼,不是200,産生requests.HTTPError
爬取網頁的通用代碼架構
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() # 如果狀态不是200,引發HTTPError異常
r.encoding=r.apparent_encoding
return r.text
except:
return "産生異常"
if __name__=="__main__":
url="https://www.baidu.com"
print(getHTMLText(url))
http方法:
patch和put的差別:
假設URL位置有一組資料UserInfo,包括UserID、UserName等20個字段。
需求:用于修改了UserName,其他不變。
- 采用patch,僅需向URL送出UserName的局部更新請求
- 采用put,必須将所有20個字段一并送出到URL,未送出字段将被删除
head方法,擷取網絡資源的概要資訊
post方法,向網頁送出資訊
request方法,最基礎的方法
requests.request(method,url,**kwargs)
**kwargs 通路控制參數,均為可選項
- params:字典或位元組序列,作為參數添加到url中
- data:字典、位元組序列、檔案對象,作為Request的内容
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - json:JSON格式的資料,作為Request的内容向伺服器送出
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - headers:字典,HTTP定制頭
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - cookies:字典或CookieJar,Request中的cookie
- auth:元組,支援HTTP認證功能
- files:字典類型,傳輸送出檔案
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - timeout:設定逾時時間,秒為機關
- proxies:字典類型,設定通路代理伺服器,可以增加登入驗證
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - allow_redirects:True/False,預設為True,重定向開關
- stream:True/False,預設為True,擷取内容立即下載下傳開關
- verify:True/False,預設為True,認證SSL證書開關
- cert:本地SSL證書路徑
requests.get(url,params=None,**kwargs)
requests.head(url,**kwargs)
requests.post(url,data=None,json=None,**kwargs)
requests.put(url,params=None,**kwargs)
requests.patch(url,params=None,**kwargs)
requests.delete(url,**kwargs)
2.網絡爬蟲的Robots協定
網絡爬蟲問題:
伺服器性能騷擾、資料法律侵權、隐私洩露
Robots協定:
Robots Exclusion Standard 網絡爬蟲排除标準
作用:告知,哪些内容可以爬取,哪些内容不可以爬取
形式:在網站根目錄下的
robots.txs檔案
Robots協定規定如果一個網站不提供robots.txt檔案,預設允許被爬取。
3.requests庫網絡爬蟲實戰(5個執行個體)
執行個體1:京東商品頁面的爬取
執行個體2:亞馬遜商品的爬取
【注意】定制headers,避免被網站伺服器識别為爬蟲
一般隻需要修改:
執行個體3:百度搜尋關鍵詞送出(用程式自己送出關鍵詞并搜尋)
執行個體4:網絡圖檔的爬取并儲存下來
import requests
import os
url="https://c-ssl.duitang.com/uploads/item/201608/09/20160809112917_ZkVCP.jpeg"
root="F://csnotes//notes//crawler//code//img"
path=root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("檔案儲存成功")
else:
print("檔案已存在")
except:
print("爬取失敗")
使用圖檔的原名字,隻需要截取/最後的名稱
執行個體5:ip位址的歸屬地
在網絡上找API
網站上面的人機互動方式,“圖形文本框點選”在正式向伺服器送出的時候都是以連結的形式送出,隻要我們知道連結形式,就可以通過Python程式去送出。
網絡上任何一個東西都對應一個url,理論上都可以爬取
二、網路爬蟲之爬取
1.beautifulsoup4庫
安裝beautiful soup:
pip install beautifulsoup4
Beautiful Soup 是一個可以從HTML或XML檔案中提取資料的python庫
使用beautifulsoup4解析 字元串格式的html代碼
字元串格式的html代碼
import bs4
from bs4 import BeautifulSoup
soup=BeautifulSoup(r.text,'html.parser')
soup2=BeautifulSoup("<html>data</html>",'html.parser') # html字元串形式
soup3=BeautifulSoup(open("D://demo.html"),'html.parser') #html以打開檔案形式導入
- beautifulsoup本身解析的是html和xml的文檔,與标簽樹一一對應,通過bs4轉換為一個BeautifulSoup類。
- 通過beautifulsoup庫使得标簽樹成為一個變量。即BeautifulSoup類對應一個HTML/XML文檔的全部内容
beautifulsoup庫解析器
主要使用html.parser解析器
beautifulsoup類的基本元素
元素擷取:
from bs4 import BeautifulSoup
import requests
r=requests.get("https://python123.io/ws/demo.html")
soup=BeautifulSoup(r.text,"html.parser")
# 獲得标簽
print(soup.title)
print(soup.a)
# 獲得标簽的名字
tag=soup.a
print(tag.name)
print(tag.parent.name)
# 獲得标簽的屬性
print(tag.attrs)
print(tag.attrs["class"])
print(tag.attrs["href"])
# 标簽的類型
print(type(tag)) #<class 'bs4.element.Tag'>
# 标簽屬性的類型
print(type(tag.attrs)) #<class 'dict'>
基于bs4庫的對html标簽樹周遊
html文檔标簽樹
下行周遊:
- .contents和.children:獲得下一層兒子節點清單,可以使用下标
- .descendants:擷取所有子孫節點清單
.contents傳回清單類型
.children和.descentdants傳回疊代類型,隻能用在for循環中
tag=soup.body
# .contents的使用
print(type(tag.contents)) #<class 'list'>
print(tag.contents[1])
# .children的使用,周遊兒子節點
print(type(tag.children)) #<class 'list_iterator'>
for child in soup.body.children:
print(child)
# .descendants的使用,周遊子孫節點
print(type(tag.descendants)) #<class 'generator'>
for child in soup.body.descendants:
print(child)
上行周遊:
- .parent:傳回父親節點
- .parents:傳回先輩節點
# .parent的使用
print(type(soup.title.parent)) #<class 'bs4.element.Tag'> 父親隻有一個
print(soup.title.parent)
# .parents的使用
print(type(soup.a.parents)) #<class 'generator'> 先輩需要周遊
for parent in soup.a.parents:
if(parent is None):
print(parent)
else:
print(parent.name)
平行周遊:
- .next_sibling:傳回後一個平行節點标簽
- .previous_sibling:傳回前一個平行節點标簽
- .next_siblings:傳回後面所有平行節點标簽
- .previous_siblings:傳回前面所有平行節點标簽
所有的平行周遊發生在同一個父節點下
平行周遊的下一個節點不一定是标簽類型,可能是NavigableString類型
<p>
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a>
and
<a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>
</p>
基于bs4庫的html格式輸出:prettify()方法
讓html友好的輸出
- 為html文本的标簽和内容增加換行符
- 也可以對每個标簽做處理
編碼問題:bs4庫将每一個讀入的html檔案或字元串都轉換為utf-8編碼
2.資訊标記與提取方法
資訊标記語言
資訊标記三種形式
-
**XML(eXtensible Markup Language)**通過标簽形式來建構所有資訊
XML是基于html發展的一種通用的資訊表達形式
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 XML執行個體:将每一個資訊域定義相關标簽,采用嵌套形式組織起來 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - JSON(javaScript Object Notation) 有類型的鍵值對key:value,采用雙引号表示類型
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 對于javascript等程式設計語言,可以直接将json格式作為程式的一部分
JSON執行個體:
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - YAML(YAML Ain’t Markup Language)無類型的鍵值對key:value 通過縮進表示所屬關系
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 減号表達并列關系 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 | 表示整塊資料 #表示注釋 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 YAML執行個體: python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構
比較:
-
XML:最早的通用資訊标記語言,可拓展性好,但繁瑣。
主要應用在:Internet上的資訊互動與傳遞,如html
-
JSON:資訊有類型,适合程式處理(js),較XML簡潔。
主要應用在:移動應用雲端和節點的資訊通信,無注釋。
用在程式對接口處理的地方,json資料在經過傳輸之後能夠作為程式代碼的一部分并被程式直接運作,這樣json格式中對資料類型的定義才能最大化發揮作用
缺陷:無法使用注釋
-
YAML:資訊無類型,文本資訊比例最高,可讀性好。
主要應用在:各類系統的配置檔案,有注釋易讀
資訊提取的一般方法
資訊提取指從标記後的資訊中,提取出所關注的内容
-
方法一:完整解析資訊的标記形式,再提取關鍵資訊
XML、JSON、YAML
需要表及解析器 例如:bs4庫的标簽樹周遊
優點:資訊解析準确
缺點:提取過程繁瑣,速度慢
-
方法二:無視标記形式,直接搜尋關鍵資訊
搜尋
對資訊的文本,查找函數即可
優點:提取過程簡潔,速度較快
缺點:提取結果準确性與資訊内容直接相關
-
【使用多】融合方法:結合形式解析與搜尋方法,提取關鍵資訊
XML、JSON、YAML +搜尋
标記解析器+文本查找函數
執行個體:提取HTML中所有的URL連接配接
demo.html
思路:
- 找到所有的
<a>
- 解析
<a>
for link in soup.find_all('a'):
print(link.get('href'))
<>.find_all()
<>.find_all()
# 1.name:字元串檢索 标簽
# 查找所有a标簽
print(soup.find_all('a'))#傳回清單類型
# 查找所有a标簽或b标簽,or
print(soup.find_all(['a','b']))
# 标簽名稱為true,傳回所有标簽
print(soup.find_all(True))
import re
# 查找所有以b開頭的所有資訊
soup.find_all(re.compile('b'))
# 2.attrs:字元串檢索 屬性
# 帶有class='course'屬性的p标簽
soup.find_all('p','course')
# 屬性中id='link1'
soup.find_all(id='link1')
# 正規表達式,id以'link'開頭
soup.find_all(id=re.compile('link'))
# 3.recursive是否對子孫全部檢索,預設為true。
# 隻搜尋目前節點的兒子,可置為false
soup.find_all('a',recursive=False)
# 4.string 字元串檢索 标簽中字元串域
# 精确檢索
soup.find_all(string="Basic Python")
# 模糊檢索,正規表達式
soup.find_all(string=re.compile("python"))
進行文字檢索時:使用find_all函數+正規表達式可以很有效的在html和xml文本中檢索到所需要資訊或者獲得所需要資訊的相關區域
find_all()簡寫形式:
7個擴充方法:
3.執行個體1:中國大學排名爬取
url:
【軟科排名】2021年最新軟科中國大學排名|中國最好大學排名 (shanghairanking.cn)
功能描述:
- 輸入:大學排名url連結
- 輸出:大學排名資訊的螢幕輸出(排名,大學名稱,總分)
- 技術路線:requests-bs4
定向爬蟲
程式設計:
- request擷取網頁内容
getHTMLTest()
- bs4提取網頁内容到合适資料結構
fillUnivList()
- 展示輸出結果(存儲到資料庫)
PrintUnivList()
老師課堂教學執行個體:url不可用,僅代碼
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLTest(url):
try:
r=requests.get(url,timeout=30,headers={'user-agent':'Mazilla/5.0'})
r.raise_for_status()
r.encodingk=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td') #找到tr标簽裡面的所有td
ulist.append([tds[0].string,tds[1].string,tds[3].string]) #将每個大學的資訊組成一個清單,放到大清單中
def printUnivList(ulist,num):
tplt="{0:^10}\t{1:{3}^10}'t{2:^10}" #中文輸出對齊問題
print(tplt.format("排名","學校名稱","總分"),chr(12288)) #表頭的設定
for i in range(num): #列印學校資訊
u=ulist[i]
print(tplt..format(u[0],u[1],u[2]),chr(12288))
def main():
uinfo=[]
url="https://m.dxsbb.com/news/38833.html" # 此處與老師的url不一緻
html=getHTMLTest(url) #html=r.text 為字元串
fillUnivList(uinfo,html)
printUnivList(uinfo,20) # 隻列出20所學校的相關資訊
三、網絡爬蟲之實戰
1.Re庫
概念、文法
正規表達式——是用來簡潔表示一組字元串的表達式。
- 通用的字元串表達架構
- 簡潔,表達一組字元串的特征或者模式,的表達式
- 針對字元串表達“簡潔”和“特征”思想的工具
- 判斷某個字元串是否屬于某個類型
作用
- 表達文本類型的特征(病毒、入侵等)
- 同時查找或替換一組字元串
- 比對字元串的全部或部分特征
主要應用在字元串比對中
使用
**編譯:**将符合正規表達式文法的字元串 轉換成正規表達式特征
編譯後的特征與一組字元串對應,編譯之前的正規表達式 隻是符合正規表達式文法的單一字元串,并不是真正意義上的正規表達式
文法
由字元+操作符構成
常用操作符:
基本使用
Re庫是Python的标準庫,主要用于字元串比對
raw string類型(原生字元串類型)
re庫采用raw string類型表示正規表達式,表示為:
r’text’
如:
r’[1-9]\d{5}'
和
r’\d{3}-\d{8}\\d{4}=\d{7}‘
’
raw string是指不包含轉義符的字元串
正規表達式的表示類型
當正規表達式中包含“轉義字元”時,使用raw string來表示
Re庫主要功能函數
re.search()函數
re.match()函數
此時未比對到,match為空變量
re.findall()函數,傳回清單
spolit()函數
将比對的部分去掉,剩下的部分作為各單個元素放到清單裡面
re.finder()函數
re.sub()函數
用一個新的字元串 替換比對上的字元串
re庫的另一種等價用法
re.compile()函數
字元串或者或者原生字元串并不是正規表達式,它隻是一種表示。
通過compile編譯生成的一個對象regex才是正規表達式,它代表了一組字元串
正規表達式對象 的概念
正規表達式對象 的方法
隻需要直接給出相關的字元串就可以了
re庫的match對象
match對象就是一次比對的結果,包含了很多比對的相關資訊
match對象的屬性
match對象的方法
match對象包含了一次正規表達式比對過程中,出現的更多的資訊。
隻包含一次比對的結果,如果需要得到每一個傳回的對象,需要用finditer()函數實作傳回疊代器類型
Re庫的貪婪比對和最小比對
re庫預設采用貪婪比對,即最長比對
最小比對
小結:
正規表達式,是用來簡潔表達一組字元串的表達式
re庫提供了六個方法
兩種調用方式,将資質證表達式編譯成正規表達式對象
程式設計使用中,文本處理和操縱是最常使用的功能,正規表達式很好的支援了文本比對和文本替換
2.淘寶商品比價定向爬蟲
功能描述
- 目标:擷取淘寶搜尋頁面的資訊,提取其中的商品名稱和價格。
- 了解:淘寶的搜尋接口、翻頁的處理
- 技術路線:requests+re
url連結接口
程式的結構設計
- 送出商品搜尋請求,循環擷取頁面
- 對于每個頁面,提取商品名稱和價格資訊
- 将資訊輸出到螢幕上
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 解析網頁:不使用beautifulSoup庫提取商品資訊,隻采用正規表達式,提取價格和标題
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) #傳回的是清單
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1]) #eval能去掉最外層雙引号和單引号
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "價格", "商品名稱"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '書包'
depth = 3 #爬取深度
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = [] # 輸出結果
for i in range(depth): # 對每一個頁面進行爬取
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url) #擷取網頁
parsePage(infoList, html) #解析頁面
except:
continue #某個頁面解析失敗跳過繼續往後解析
printGoodsList(infoList)
main()
本執行個體中因為具體資料是script腳本給出的,并非靜态html頁面,是以采用正規表達式擷取
3.股票資料定向爬蟲
功能描述
- 目标:擷取上交所和深交所所有股票的名稱和交易資訊
- 輸出:儲存到檔案中
- 技術路線:requests+bs4+re
候選資料網站的選擇
- 選取原則:股票資訊靜态存在于HTML頁面中,非js代碼生成,沒有Robots協定限制。
- 選取方法:檢視源代碼
- 選取心态:不要糾結于某個網站,多找資訊源嘗試
程式結構設計
- 從東方财富網擷取股票清單
- 根據股票清單逐個到百度股票擷取個股資訊
- 将結果存儲到檔案
import requests
from bs4 import BeautifulSoup
import re
import traceback
def getHTMLText(url):
try:
r=requests.get(url,headers={'user-agent':'Mazilla/5.0'},timeout=30)
print(r.status_code)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst,stockURL): #lst為傳回的股票清單 stockURL為擷取股票清單的網址
html=getHTMLText(stockURL)
soup=BeautifulSoup(html,'html.parser')
a=soup.find_all('a')
for i in a:
try:
href=i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}',href)) #【重要】利用正規表達式擷取beautifulSoup處理後的文本
except:
continue
def getStockInfo(lst,stockURL,fpath): #lst為股票清單,stockURL為具體股票的連結,fpath為檔案位址
for stock in lst:
url=stockURL+stock+".html"
html=getHTMLText(url)
try:
if html=="":
continue
infoDict={} #存儲個股的所有資訊
soup=BeautifulSoup(html,'html.parser')
stockInfo=soup.find('div',attrs={'class':'stock-bets'})
name=stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名稱':name.text.split()[0]}) #股票名稱後面課程還有其他資訊,删減掉
keyList=stockInfo.find_all('dt') #股票資訊key
valueList=stockInfo.find_all('dd') #股票資訊value
for i in range(len(keyList)):
key=keyList[i].text
val=valueList[i].text
infoDict[key]=val #将資訊存儲到字典中
#将股票資訊儲存到檔案中
with open(fpath,'a',encoding='utf-8') as f:
f.write(str(infoDict)+'\n')
except:
traceback.print_exc() #列印錯誤資訊
continue
def main():
stock_list_url="http://quote.eastmoney.com"
stock_info_url="https://gupiao.baidu.com"
output_file='D://BaiduStockInfo.txt'
slist=[] #股票清單
getStockList(slist,stock_list_url) #擷取股票清單
getStockInfo(slist,stock_info_url,output_file) #根據股票清單到相關網站擷取相應股票資訊,并存儲到檔案中
main()
優化:提升使用者體驗
- 提高速度
在已知網頁編碼情況下,可以直接手動指派編碼
- 增加動态進度顯示
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構
增加“不換行 動态進度條”資訊展示:采用
\r
進度條的
\r
屬性在IDLE中被禁止,可以使用command指令行檢視
完整代碼
import requests
from bs4 import BeautifulSoup
import traceback
import re
def getHTMLText(url, code="utf-8"):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = code
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL, "GB2312")
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}", href)[0])
except:
continue
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html=="":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名稱': name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write( str(infoDict) + '\n' )
count = count + 1
print("\r目前進度: {:.2f}%".format(count*100/len(lst)),end="")
except:
count = count + 1
print("\r目前進度: {:.2f}%".format(count*100/len(lst)),end="")
continue
def main():
stock_list_url = 'https://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:/BaiduStockInfo.txt'
slist=[]
getStockList(slist, stock_list_url)
getStockInfo(slist, stock_info_url, output_file)
main()
小結
- 區分是js擷取的動态網頁還是html靜态頁面
- 合理使用beautifulSoup和re庫,特征明顯的資料可以直接采用正規表達式擷取;一般先采用beautifulSoup庫提取資料,再利用正規表達式詳細提取
- 優化:實作了爬取程序的動态滾動條
四、網絡爬蟲之架構——Scrapy架構
1.概述
安裝scrapy庫(需要關閉vpn)
pip install scrapy
scrapy -h
測試安裝效果
介紹
爬蟲架構結構
5個核心子產品+2個中間件
scrapy架構包含三條主要資料流路徑:在這5個子產品之間,資料包括使用者送出的網絡爬蟲請求以及從網絡上擷取的相關内容 在這些結構之間進行流動,形成了資料流。
- engine從spiders擷取了爬取使用者的請求requests,engine轉發給scheduler子產品,scheduler子產品負責對爬取請求進行排程。
- engine從scheduler獲得下一個要爬取的網絡請求(這個時候的網絡請求是真實的,要去網絡上去爬取的請求),engine通過中間件發送給downloader子產品,downloader子產品拿到請求後真實連接配接網際網路并爬取相關網頁;将爬取的内容封裝形成一個response對象,通過中間件發送給engine,再轉發給spiders。
- spiders處理從網絡上擷取的内容,産生兩個資料類型,一個是爬取項items,另一個是網頁上感興趣的新的爬取請求。将資料發送engine,engine将item轉發給item pipelines,将requests轉發給scheduler
架構入口是spiders,出口是item pipelines
engine,scheduler,downloader都是已有的功能實作
使用者需要編寫spiders子產品和item pipelines子產品,基于模闆的編寫,稱為配置
spiders子產品用來向整個架構提供要通路的url連結,同時要解析從網絡頁面上獲得的内容
item pipelines子產品負責對提取的資訊進行後處理
爬蟲架構解析
engine:不需要使用者修改
- 控制所有子產品之間的資料流
- 根據條件觸發事件
downloader
- 根據請求下載下傳網頁
- 也不需要使用者修改
scheduler
- 對所有爬去請求進行排程管理
- 也不需要使用者修改
engine和downloader之間的中間件 Downloader Middleware
- 目的:實施engine、scheduler和downloader之間進行使用者可配置的控制
-
功能:使用者可以自定義修改、丢棄、新增請求或響應
使用者可以編寫配置代碼,一般使用者可以不更改這個中間件
spiders:最核心,需要使用者編寫配置代碼
- 解析Downloader傳回的響應(Response)
- 産生爬取項(scraped item)
- 産生額外的爬去請求(Request)
Item pipelines
- 以流水線方式處理spider産生的爬取項
- 由一組操作順序組成,類似流水線,每個操作是一個Item Pipeline類型
- 可能的操作包括:對Item的資料進行清理、檢驗、查重爬取項中的HTML資料、将資料存儲到資料庫
- 需要使用者配置
從網頁中提取出來的item資訊,使用者希望怎麼處理
spider Middleware
- 目的:對請求和爬取項的再處理
- 功能:修改、丢棄、新增請求或爬取項
- 使用者可以編寫配置代碼
requests庫和Scrapy庫(架構)比較
相同點:
- 都可以對頁面進行請求和爬取
- 兩者都沒有處理js、送出表單、應對驗證碼等功能(可擴充)
不同點:
非常小的爬取需求:requests
不太小的請求:scrapy架構
自搭架構:requests>scrapy
Scrapy常用指令
scrapy是為持續運作設計的專業爬蟲架構,提供操作的Scrapy指令行
指令行格式:
scrapy常用指令
scrapy架構下一個project是一個最大單元,相當于一個scrapy架構;
架構中可以有多個爬蟲,每一個爬蟲相當于一個spider子產品
2.基本使用
scrapy爬蟲的第一個執行個體
産生scrpy架構:
-
建立Scrapy爬蟲工程
cmd中cd到特定目錄中,
scrapy startproject python123demo
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - 在工程中産生一個Scrapy爬蟲,生成demo.py
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 -
配置産生的spider爬蟲,修改demo.py檔案
修改具體連結
更改爬取方法的具體功能
此處實作:将response中的内容寫到一個檔案中
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - 運作爬蟲,擷取網頁
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構
完整版代碼
yield關鍵字的使用
yield是python33個關鍵字之一
生成器
- 生成器是一個不斷産生值的函數
- 包含yield語句的函數是一個生成器
- 生成器每次産生一個值(yield語句),函數被當機,被喚醒後再産生一個值
生成器的使用一般與循環搭配在一起,可以通過循環調用
普通寫法:列舉所有可能的值,再傳回清單
為什麼要有生成器?
- 生成器相比一次列出所有内容的優勢:更節省存儲空間,響應更迅速,使用更靈活
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 當n很大時,使用生成器寫法 python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 -
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 生成器寫法,urls是一個清單,通過for循環使用yield語句每次送出一個url請求。
start_requests是一個生成器函數,對其調用每次傳回一個url連結
基本使用小結
scrapy爬蟲的使用步驟
- 建立一個工程和Spider模闆
- 編寫spider
- 編寫item Pipeline
- 優化配置政策
Scrapy爬蟲的資料類型
- Request類
-
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 -
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構
-
- Response類
-
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 -
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構
-
- Item類
-
python網絡爬蟲與資訊提取python網絡爬蟲與資訊提取一、網絡爬蟲之規則二、網路爬蟲之爬取三、網絡爬蟲之實戰四、網絡爬蟲之架構——Scrapy架構 - Spider對網頁相關資訊進行擷取後,會提取其中的資訊,把其中的資訊生成鍵值對,并且封裝成字典,這種字典就是item類
-
scrapy爬蟲提取資訊的方法
scrapy爬蟲支援多種HTML資訊提取方法
- BeautifulSoup
- Ixml
- re
- XPath Selector
- CSS Selector
CSS Selector的基本使用
3.執行個體:股票資料Scrapy爬蟲
步驟1:建立工程和Spider模闆
-
\>scrapy startproject BaiduStocks
-
\>cd BaiduStocks
-
\>scrapy genspider stocks baidu.com
- 進一步修改spiders、stocks.py檔案
stock.py
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['https://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{'股票名稱': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict
步驟2:編寫Spider
- 配置stocks.py檔案
- 修改對傳回頁面的處理
- 修改對新增URL爬取請求的處理
步驟3:編寫Pipelines
- 配置pipelines.py檔案
- 定義對爬取項Scraped Item的處理類
-
建立了一個類,找到settings.py,配置ITEM_PIPELINE選項,才能找到這個類
pipelines.py
settings.py# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class BaidustocksPipeline(object): def process_item(self, item, spider): return item class BaidustocksInfoPipeline(object): def open_spider(self, spider): self.f = open('BaiduStockInfo.txt', 'w') def close_spider(self, spider): self.f.close() def process_item(self, item, spider): try: line = str(dict(item)) + '\n' self.f.write(line) except: pass return item# Configure item pipelines # See https://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300, }
生成了一個spider,它能夠從東方财富網獲得股票的清單,并且針對每一個股票清單生成一個百度股票的連結;并向百度股票的連結進行資訊爬取;
對于爬取後的資訊,經過spider的處理,提取出其中關鍵資訊,形成字典,并且将這個字典以item類的形式給到了item pipelinses進行後續處理
執行個體優化