一:Pacemaker和corosync概述:
Pacemaker(心髒起搏器),是一個叢集管理資源器。但是其不提供心跳資訊。pacemaker是一個延續的CRM。Pacemaker到了V3的版本以後
拆分了多個項目,其中pacemaker就是拆分出來的資料總管。
Heart 3.0拆分之後的組成部分:
*Heartbeat:将原來的消息通信層獨立為heartbeat項目,新的heartbeat隻負責維護叢集各個節點的資訊以及他們之間的通信。
*Cluster Glue:相當于一個中間層,它用來将Heartbeat和pacemaker關聯起來,主要包含2個部分,即:LRM和STONITH
*Resource Agent:用來控制服務啟停,監控服務狀态的腳本集合,這些腳本将被LRM調用進而實作各種資源啟動,停止,監控等。
*pacemaker:也就是Cluster Resource Manager(簡稱CRM),用來管理整個HA的控制中心,用戶端通過pacemaker來配置管理監控
整個叢集。
Pacemaker特點:
&主機和應用程式級别的故障檢測和恢複。
&幾乎支援任何備援設定
&同時支援多種叢集配置模式
&配置政策處理法定人數損失
&支援應用啟動和關機順序
&支援多種模式的應用程式(如主/從)
&可以測試任何故障或叢集的狀态
叢集元件說明:
*stonith:心跳系統
*LRMD:本地資源管理守護程序。它提供了一個通用的接口支援的資源類型。直接調用資源代理
*pengine:政策引擎。根據目前狀态和配置叢集計算的下一個狀态。産生一個過渡圖。包含行動和
依賴關系的清單。
*CIB:叢集資訊庫。包含所有叢集選項,節點,資源,他們彼此之間的關系和現狀的定義,同步更新到
所有叢集節點。 CIB使用XML表示叢集的叢集中的所有資源的配置和目前狀态。CIB的内容會被自動在整個叢集中同步
*CRMD:叢集資源管理守護程序。主要是消息代理的PENGINE和LRM,還選舉一個上司者(DC)統籌活動的叢集。
*OPENAIS:OpenAIS的消息和成員層。
*Heartbe:心跳消息層。OpenAIS的一種替代。
*CCM:共識叢集成員
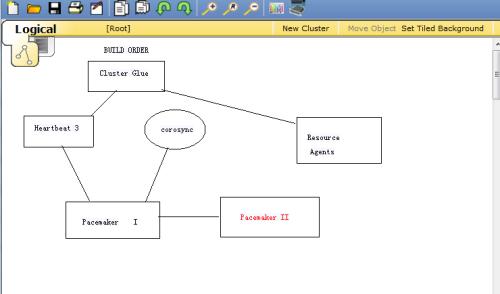
Corosync最初隻是用來示範OpenAIS叢集架構接口規範的一個應用,可以實作HA心跳資訊傳輸功能,RHCS叢集套件就是基于corosync
實作。corosync隻提供了message layer(即實作Heartbeat+CCM),沒有直接提供CRM,一般使用Pacemaker進行資源管理。
Pacemaker是一個開源的高可用資料總管(CRM),位于HA架構中資源管理,資源代理(RA)這個層次,它不能提供底層心跳資訊傳遞的功能。
要想與對方節點通信需要借助底層的心跳傳遞伺服器,将資訊通告給對方。
Corosync主要就是實作叢集中Message layer層的功能:完成叢集心跳及事務資訊的傳遞,Pacemaker主要實作的是管理叢集中的資源(CRM),真正
啟用,停止叢集中的服務是RA(資源代理)這個子元件。RA的類别有下面幾種類型LSB:位于/etc/rc.d/init.d/目錄下。至少支援start,stop
restart,status,reload,force-reload等指令。
OCF:/usr/lib/ocf/resource.d/provider/,類似于LSB腳本,但支援start stop status monitor,meta-data;
STONITH:調用stonith裝置的功能
systemd:unit file, /usr/lib/systemd/system/這類服務必須設定成開機自啟動(enable)。
service:調用使用者的自定義腳本

二:部署Pacemaker+corosync
2.1安裝軟體包
pacemaker依賴corosync,安裝pacemaker包會連帶安裝corosync包;yum -y install pacemaker
[[email protected] ~]# yum -y install pacemaker;ssh [email protected] ‘yum -y install pacemaker‘
[[email protected] ~]# rpm -ql corosync
/etc/corosync
/etc/corosync/corosync.conf.example #配置檔案模闆
/etc/corosync/corosync.conf.example.udpu
/etc/corosync/service.d
/etc/corosync/uidgid.d
/etc/dbus-1/system.d/corosync-signals.conf
/etc/rc.d/init.d/corosync #服務腳本
/etc/rc.d/init.d/corosync-notifyd
/etc/sysconfig/corosync-notifyd
/usr/bin/corosync-blackbox
/usr/libexec/lcrso
/usr/libexec/lcrso/coroparse.lcrso
...
/usr/sbin/corosync
/usr/sbin/corosync-cfgtool
/usr/sbin/corosync-cpgtool
/usr/sbin/corosync-fplay
/usr/sbin/corosync-keygen #生成節點間通信時用到的認證密鑰檔案,預設從/dev/random讀随機數
/usr/sbin/corosync-notifyd
/usr/sbin/corosync-objctl
/usr/sbin/corosync-pload
/usr/sbin/corosync-quorumtool
/usr/share/doc/corosync-1.4.7
...
/var/lib/corosync
/var/log/cluster #日志檔案目錄
2.2◆安裝crmsh
RHEL自6.4起不再提供叢集的指令行配置工具crmsh,預設提供的是pcs;本例中使用crmsh,crmsh依賴于pssh,是以需要一并下載下傳安裝
[[email protected] ~]# yum -y install pssh-2.3.1-2.el6.x86_64.rpm crmsh-1.2.6-4.el6.x86_64.rpm
...
Installed:
crmsh.x86_64 0:1.2.6-4.el6 pssh.x86_64 0:2.3.1-2.el6
Dependency Installed:
python-dateutil.noarch 0:1.4.1-6.el6 redhat-rpm-config.noarch 0:9.0.3-44.el6.centos
Complete!
2.3◆配置corosync
cd /etc/corosync/
cp corosync.conf.example corosync.conf
vim corosync.conf,在其中加入:
service { #以插件化方式調用pacemaker
ver: 0
name: pacemaker
# use_mgmtd: yes
}
[[email protected] ~]# cd /etc/corosync/
[[email protected] corosync]# cp corosync.conf.example corosync.conf
[[email protected] corosync]# vim corosync.conf
# Please read the corosync.conf.5 manual page
compatibility: whitetank
totem {
version: 2
secauth: on #是否進行消息認證;若啟用,使用corosync-keygen生成密鑰檔案
threads: 0
interface {
ringnumber: 0
bindnetaddr: 192.168.30.0 #接口綁定的網絡位址
mcastaddr: 239.255.10.1 #傳遞心跳資訊所使用的多點傳播位址
mcastport: 5405
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
logfile: /var/log/cluster/corosync.log #日志路徑
to_syslog: no
debug: off
timestamp: on #是否記錄時間戳;當日志量很大時關閉該項可提高性能
logger_subsys {
subsys: AMF
debug: off
}
}
#下面這段表示以插件的方式調用pacemaker
service {
ver: 0
name: pacemaker
# use_mgmtd: yes
}
2.4◆啟動corosync
service corosync start
檢視corosync引擎是否正常啟動,是否正常讀取配置檔案:
grep -e "Corosync Cluster Engine" -e "configuration file" /var/log/cluster/corosync.log
檢視初始化成員節點通知是否正常發出:
grep TOTEM /var/log/cluster/corosync.log
檢查啟動過程中是否有錯誤産生:
grep ERROR: /var/log/cluster/corosync.log | grep -v unpack_resources
檢視pacemaker是否正常啟動:
grep pcmk_startup /var/log/cluster/corosync.log
[[email protected] ~]# service corosync start;ssh [email protected] ‘service corosync start‘
Starting Corosync Cluster Engine (corosync): [ OK ]
Starting Corosync Cluster Engine (corosync): [ OK ]
[[email protected] ~]# grep -e "Corosync Cluster Engine" -e "configuration file" /var/log/cluster/corosync.log
Apr 28 02:03:08 corosync [MAIN ] Corosync Cluster Engine (‘1.4.7‘): started and ready to provide service.
Apr 28 02:03:08 corosync [MAIN ] Successfully read main configuration file ‘/etc/corosync/corosync.conf‘.
[[email protected] ~]# grep TOTEM /var/log/cluster/corosync.log
Apr 28 02:03:08 corosync [TOTEM ] Initializing transport (UDP/IP Multicast).
Apr 28 02:03:08 corosync [TOTEM ] Initializing transmit/receive security: libtomcrypt SOBER128/SHA1HMAC (mode 0).
Apr 28 02:03:08 corosync [TOTEM ] The network interface [192.168.30.20] is now up.
Apr 28 02:03:08 corosync [TOTEM ] A processor joined or left the membership and a new membership was formed.
Apr 28 02:03:11 corosync [TOTEM ] A processor joined or left the membership and a new membership was formed.
Apr 28 02:04:10 corosync [TOTEM ] A processor joined or left the membership and a new membership was formed.
[[email protected] ~]# grep ERROR: /var/log/cluster/corosync.log | grep -v unpack_resources #以下錯誤提示可忽略
Apr 28 02:03:08 corosync [pcmk ] ERROR: process_ais_conf: You have configured a cluster using the Pacemaker plugin for Corosync. The plugin is not supported in this environment and will be removed very soon.
Apr 28 02:03:08 corosync [pcmk ] ERROR: process_ais_conf: Please see Chapter 8 of ‘Clusters from Scratch‘ (http://www.clusterlabs.org/doc) for details on using Pacemaker with CMAN
Apr 28 02:03:13 corosync [pcmk ] ERROR: pcmk_wait_dispatch: Child process cib terminated with signal 11 (pid=7953, core=true)
...
[[email protected] ~]# grep pcmk_startup /var/log/cluster/corosync.log
Apr 28 02:03:08 corosync [pcmk ] info: pcmk_startup: CRM: Initialized
Apr 28 02:03:08 corosync [pcmk ] Logging: Initialized pcmk_startup
Apr 28 02:03:08 corosync [pcmk ] info: pcmk_startup: Maximum core file size is: 18446744073709551615
Apr 28 02:03:08 corosync [pcmk ] info: pcmk_startup: Service: 9
Apr 28 02:03:08 corosync [pcmk ] info: pcmk_startup: Local hostname: node2
◆配置接口crmsh的啟動指令是crm,其使用方式有兩種:
指令行模式,例如 # crm ra list ocf
互動式模式,例如:
# crm
crm(live)# ra
crm(live)ra# list ocf
或者:
# crm
crm(live)# ra list ocf
help:檢視幫助資訊
end/cd:切回上一級
exit/quit:退出程式
常用子指令:
①status: 檢視叢集狀态
②resource:
start, stop, restart
promote/demote:提升/降級一個主從資源
cleanup:清理資源狀态
migrate:将資源遷移到另外一個節點上
③configure:
primitive, group, clone, ms/master(主從資源)
具體用法可使用help指令檢視,如crm(live)configure# help primitive
示例:
primitive webstore ocf:Filesystem params device=172.16.100.6:/web/htdocs directory=/var/www/html fstype=nfs op monitor interval=20s timeout=30s
group webservice webip webserver
location, collocation, order
示例:
colocation webserver_with_webip inf: webserver webip
order webip_before_webserver mandatory: webip webserver #mandatory也可換成inf
location webip_on_node2 webip rule inf: #uname eq node2
或location webip_on_node2 webip inf: node2
monitor #pacemaker具有監控資源的功能
monitor <rsc>[:<role>] <interval>[:<timeout>]
例如:monitor webip 30s:20s
very:CIB文法驗證
commit:将更改後的資訊送出寫入CIB(叢集資訊庫)
注意:配置完後要記得very和commit
show:顯示CIB對象
edit:直接以vim模式編輯CIB對象
refresh:重新讀取CIB資訊
delete:删除CIB對象
erase:擦除所有配置
④node:
standby:讓節點離線,強制其成為備節點
online:讓節點重新上線
fence:隔離節點
clearstate:清理節點狀态資訊
delete:删除一個節點
⑤ra:
classes:檢視資源代理有哪些種類
有四種:lsb, ocf, service, stonith
list <class> [<provider>]:列出資源代理
例如:
list ocf #列出ocf類型的資源代理
list ocf linbit #列出ocf類型中,由linbit提供的資源代理
meta/info [<class>:[<provider>:]]<type> #檢視一個資源代理的中繼資料,主要是檢視其可用參數
例如:info ocf:linbit:drbd
或 info ocf:drbd
或 info drbd
providers <type> [<class>]:顯示指定資源代理的提供者
例如:providers apache
crm(live)# help #檢視有哪些子指令或擷取幫助資訊
This is crm shell, a Pacemaker command line interface.
Available commands:
cib manage shadow CIBs
resource resources management #資源管理
configure CRM cluster configuration #叢集配置
node nodes management #節點管理
options user preferences
history CRM cluster history
site Geo-cluster support
ra resource agents information center #資源代理資訊
status show cluster status #顯示叢集狀态
help,? show help (help topics for list of topics)
end,cd,up go back one level
quit,bye,exit exit the program #退出
crm(live)# status #檢視叢集狀态
Last updated: Fri Apr 29 00:19:36 2016
Last change: Thu Apr 28 22:41:38 2016
Stack: classic openais (with plugin)
Current DC: node2 - partition with quorum
Version: 1.1.11-97629de
2 Nodes configured, 2 expected votes
0 Resources configured
Online: [ node1 node2 ]
crm(live)# configure
crm(live)configure# help
...
Commands for resources are: #可配置的資源類型
- `primitive`
- `monitor`
- `group`
- `clone`
- `ms`/`master` (master-slave)
In order to streamline large configurations, it is possible to
define a template which can later be referenced in primitives:
- `rsc_template`
In that case the primitive inherits all attributes defined in the
template.
There are three types of constraints: #可定義的限制
- `location`
- `colocation`
- `order`
...
crm(live)configure# help primitive #檢視使用幫助
...
Usage:
...............
primitive <rsc> {[<class>:[<provider>:]]<type>|@<template>}
[params attr_list]
[meta attr_list]
[utilization attr_list]
[operations id_spec]
[op op_type [<attribute>=<value>...] ...]
attr_list :: [$id=<id>] <attr>=<val> [<attr>=<val>...] | $id-ref=<id>
id_spec :: $id=<id> | $id-ref=<id>
op_type :: start | stop | monitor
...............
Example:
...............
primitive apcfence stonith:apcsmart \
params ttydev=/dev/ttyS0 hostlist="node1 node2" \
op start timeout=60s \
op monitor interval=30m timeout=60s
crm(live)configure# cd #使用cd或end指令切回上一級
crm(live)# ra
crm(live)ra# help
This level contains commands which show various information about
the installed resource agents. It is available both at the top
level and at the `configure` level.
Available commands:
classes list classes and providers
list list RA for a class (and provider)
meta show meta data for a RA
providers show providers for a RA and a class
help show help (help topics for list of topics)
end go back one level
quit exit the program
crm(live)ra# classes
lsb
ocf / heartbeat linbit pacemaker
service
stonith
crm(live)ra# help list
List available resource agents for the given class. If the class
is `ocf`, supply a provider to get agents which are available
only from that provider.
Usage:
...............
list <class> [<provider>]
...............
Example:
...............
list ocf pacemaker
...............
crm(live)ra# list ocf
CTDB ClusterMon Delay Dummy Filesystem
...
...
crm(live)ra# list ocf linbit
drbd
crm(live)ra# help meta
Show the meta-data of a resource agent type. This is where users
can find information on how to use a resource agent. It is also
possible to get information from some programs: `pengine`,
`crmd`, `cib`, and `stonithd`. Just specify the program name
instead of an RA.
Usage:
...............
info [<class>:[<provider>:]]<type>
info <type> <class> [<provider>] (obsolete)
...............
Example:
...............
info apache
info ocf:pacemaker:Dummy
info stonith:ipmilan
info pengine
...............
crm(live)ra# info ocf:linbit:drbd
...
Operations‘ defaults (advisory minimum):
start timeout=240
promote timeout=90
demote timeout=90
notify timeout=90
stop timeout=100
monitor_Slave timeout=20 interval=20
monitor_Master timeout=20 interval=10
crm(live)ra# cd
crm(live)# resource
crm(live)resource# help
At this level resources may be managed.
All (or almost all) commands are implemented with the CRM tools
such as `crm_resource(8)`.
Available commands:
status show status of resources
start start a resource
stop stop a resource
restart restart a resource
promote promote a master-slave resource
demote demote a master-slave resource
...
crm(live)resource# help cleanup
Cleanup resource status. Typically done after the resource has
temporarily failed. If a node is omitted, cleanup on all nodes.
If there are many nodes, the command may take a while.
Usage:
...............
cleanup <rsc> [<node>]
...............
⊙在使用crmsh配置叢集時曾遇到過如下錯誤:
ERROR: CIB not supported: validator ‘pacemaker-2.0‘, release ‘3.0.9‘
ERROR: You may try the upgrade command
大概的意思就是:經檢驗器pacemaker-2.0檢查後發現crm shell版本相對較低,不被CIB(叢集資訊庫)支援,是以建議更新crmsh版本;
其實如果我們執行 cibadmin --query | grep validate 就可看到這條資訊:
<cib crm_feature_set="3.0.9" validate-with="pacemaker-2.0"
為解決此問題,可嘗試另一個辦法,将檢驗器的版本降低:
cibadmin --modify --xml-text ‘<cib validate-with="pacemaker-1.2"/>‘
經測試,使用此方法後故障解除
⑷配置高可用叢集
◆配置叢集工作屬性
本例中隻有兩個節點,沒有stonith裝置和仲裁裝置,而corosync預設啟用了stonith。啟用stonith而又沒有配置相應的stonith裝置時,corosync是不允許資源啟動的,通過以下指令就可得知:
crm_verify -L -V
是以,我們需要做如下設定:
crm configure property stonith-enabled=false
crm configure property no-quorum-policy=ignore
[[email protected] ~]# crm_verify -L -V
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
[[email protected] ~]# crm configure property stonith-enabled=false
[[email protected] ~]# crm configure property no-quorum-policy=ignore
[[email protected] ~]# crm configure show
node node1
node node2
property $id="cib-bootstrap-options" \
dc-version="1.1.11-97629de" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
[[email protected] ~]# crm_verify -L -V
[[email protected] ~]#
◆配置叢集資源
mysqld和drbd是我們要定義的叢集服務,先要確定兩個節點上的服務停止且不會開機自動啟動:
service mysqld stop;chkconfig mysqld off
service drbd stop;chkconfig drbd off
drbd需要同時運作在兩個節點上,且一個節點是Master,另一個節點為Slave(primary/secondary模型);是以,要将其配置為主從資源(特殊的克隆資源),且要求服務剛啟動時兩個節點都處于slave狀态
drbd的RA目前由OCF歸類為linbit,其路徑為/usr/lib/ocf/resource.d/linbit/drbd
⊕配置資源:
primitive myip ocf:heartbeat:IPaddr params ip=192.168.30.100 op monitor interval=30s timeout=20s
primitive mydrbd ocf:linbit:drbd params drbd_resource=mysql op monitor role=Master interval=10s timeout=20s op monitor role=Slave interval=20s timeout=30s op start timeout=240s op stop timeout=100s
主從資源是從一個主資源克隆而來,是以要先配置一個主資源
ms ms_mydrbd mydrbd meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1[ notify=True]
ms表示配置主從資源,ms_mydrbd為主從資源的名稱,後面的mydrbd表示要克隆的資源
clone-max:在叢集中最多能運作多少份克隆資源,預設和叢集中的節點數相同;
clone-node-max:每個節點上最多能運作多少份克隆資源,預設是1;
notify:當成功啟動或關閉一份克隆資源,要不要通知給其它的克隆資源,預設是true
primitive mystore ocf:heartbeat:Filesystem params device=/dev/drbd0 directory=/mydata fstype=ext4 op monitor interval=20s timeout=60s op start timeout=60s op stop timeout=60s
primitive myserver lsb:mysqld op monitor interval=20s timeout=20s
⊕定義限制:
group myservice myip mystore myserver
collocation mystore_with_ms_mydrbd_master inf: mystore ms_mydrbd:Master
儲存設備需要跟随drbd的主節點,且隻能在drbd服務将該節點提升為主節點後才可啟動
order mystore_after_ms_mydrbd_master mandatory: ms_mydrbd:promote mystore
order myserver_after_mystore mandatory: mystore myserver
order myserver_after_myip inf: myip myserver
⊕stickness
資源在節點間每一次的來回流動都會造成那段時間内其無法正常被通路,是以,我們有時候需要在資源因為節點故障轉移到其它節點後,即便原來的節點恢複正常也禁止資源再次流轉回來。這可以通過定義資源的黏性(stickiness)來實作
stickness取值範圍:
0:預設值,資源放置在系統中的最适合位置
大于0:值越高表示資源越願意留在目前位置
小于0:絕對值越高表示資源越願意離開目前位置
INFINITY:如果不是因節點不适合運作資源(節點關機、節點待機、達到migration-threshold 或配置更改)而強制資源轉移,資源總是留在目前位置
-INFINITY
可以通過以下方式為資源指定預設黏性值:
crm configure rsc_defaults resource-stickiness=100
#準備工作
[[email protected] ~]# service mysqld stop
Stopping mysqld: [ OK ]
[[email protected] ~]# umount /mydata
[[email protected] ~]# drbdadm secondary mysql
[[email protected] ~]# cat /proc/drbd
version: 8.4.3 (api:1/proto:86-101)
GIT-hash: 89a294209144b68adb3ee85a73221f964d3ee515 build by [email protected], 2013-11-29 12:28:00
0: cs:Connected ro:Secondary/Secondary ds:UpToDate/UpToDate C r-----
ns:124 nr:0 dw:2282332 dr:4213545 al:7 bm:396 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
[[email protected] ~]# service drbd stop;ssh [email protected] ‘service drbd stop‘
Stopping all DRBD resources: .
Stopping all DRBD resources: .
[[email protected] ~]# chkconfig mysqld off;ssh [email protected] ‘chkconfig mysqld off‘
[[email protected] ~]# chkconfig drbd off;ssh [email protected] ‘chkconfig drbd off‘
#配置資源
crm(live)configure# primitive myip ocf:heartbeat:IPaddr params ip=192.168.30.100 op monitor interval=30s timeout=20s
crm(live)configure# primitive mydrbd ocf:linbit:drbd params drbd_resource=mysql op monitor role=Master interval=10s timeout=20s op monitor role=Slave interval=20s timeout=30s op start timeout=240s op stop timeout=100s
crm(live)configure# ms ms_mydrbd mydrbd meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=True
crm(live)configure# primitive mystore ocf:heartbeat:Filesystem params device=/dev/drbd0 directory=/mydata fstype=ext4 op monitor interval=20s timeout=60s op start timeout=60s op stop timeout=60s
crm(live)configure# primitive myserver lsb:mysqld op monitor interval=20s timeout=20s
#定義限制
crm(live)configure# group myservice myip mystore myserver
crm(live)configure# collocation mystore_with_ms_mydrbd_master inf: mystore ms_mydrbd:Master
crm(live)configure# order mystore_after_ms_mydrbd_master mandatory: ms_mydrbd:promote mystore
crm(live)configure# order myserver_after_mystore mandatory: mystore myserver
crm(live)configure# order myserver_after_myip inf: myip myserver
crm(live)configure# verify #文法驗證
crm(live)configure# commit #送出配置
crm(live)configure# show #檢視配置資訊
node node1
node node2
primitive mydrbd ocf:linbit:drbd \
params drbd_resource="mysql" \
op monitor role="Master" interval="10s" timeout="20s" \
op monitor role="Slave" interval="20s" timeout="30s" \
op start timeout="240s" interval="0" \
op stop timeout="100s" interval="0"
primitive myip ocf:heartbeat:IPaddr \
params ip="192.168.30.100" \
op monitor interval="20s" timeout="30s"
primitive myserver lsb:mysqld \
op monitor interval="20s" timeout="20s"
primitive mystore ocf:heartbeat:Filesystem \
params device="/dev/drbd0" directory="/mydata" fstype="ext4" \
op monitor interval="20s" timeout="60s" \
op start timeout="60s" interval="0" \
op stop timeout="60s" interval="0"
group myservice myip mystore myserver
ms ms_mydrbd mydrbd \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="True"
colocation mystore_with_ms_mydrbd_master inf: mystore ms_mydrbd:Master
order myserver_after_myip inf: myip myserver
order myserver_after_mystore inf: mystore myserver
order mystore_after_ms_mydrbd_master inf: ms_mydrbd:promote mystore
property $id="cib-bootstrap-options" \
dc-version="1.1.11-97629de" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
crm(live)configure# cd
crm(live)# status #檢視叢集狀态
Last updated: Fri Apr 29 13:43:06 2016
Last change: Fri Apr 29 13:42:23 2016
Stack: classic openais (with plugin)
Current DC: node2 - partition with quorum
Version: 1.1.11-97629de
2 Nodes configured, 2 expected votes
5 Resources configured
Online: [ node1 node2 ] #node1和node2均線上
Master/Slave Set: ms_mydrbd [mydrbd]
Masters: [ node1 ] #node1為mydrbd資源的主節點
Slaves: [ node2 ]
Resource Group: myservice #組中的各資源均正常啟動
myip (ocf::heartbeat:IPaddr): Started node1
mystore (ocf::heartbeat:Filesystem): Started node1
myserver (lsb:mysqld): Started node1
#驗證
[[email protected] ~]# ip addr show #使用ip addr檢視配置的新的ip
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:40:35:9d brd ff:ff:ff:ff:ff:ff
inet 192.168.30.10/24 brd 192.168.30.255 scope global eth0
inet 192.168.30.100/24 brd 192.168.30.102 scope global secondary eth0
inet6 fe80::20c:29ff:fe40:359d/64 scope link
valid_lft forever preferred_lft forever
[[email protected] ~]# drbd-overview
0:mysql/0 Connected Primary/Secondary UpToDate/UpToDate C r----- /mydata ext4 2.0G 89M 1.8G 5%
[[email protected] ~]# ls /mydata
binlogs data lost+found
[[email protected] ~]# service mysqld status
mysqld (pid 65079) is running...
[[email protected] ~]# mysql
...
mysql> create database testdb; #建立一個新庫
Query OK, 1 row affected (0.08 sec)
mysql> exit
Bye
模拟故障
[[email protected] ~]# service mysqld stop #手動停止mysqld服務
Stopping mysqld: [ OK ]
[[email protected] ~]# crm status
...
Online: [ node1 node2 ]
Master/Slave Set: ms_mydrbd [mydrbd]
Masters: [ node1 ]
Slaves: [ node2 ]
Resource Group: myservice
myip (ocf::heartbeat:IPaddr): Started node1
mystore (ocf::heartbeat:Filesystem): Started node1
myserver (lsb:mysqld): Started node1
Failed actions:
myserver_monitor_20000 on node1 ‘not running‘ (7): call=70, status=complete, last-rc-change=‘Fri Apr 29 23:00:55 2016‘, queued=0ms, exec=0ms
#因為我們有監控資源,當pacemaker發現資源狀态異常時,會嘗試重新啟動資源,若啟動失敗會嘗試轉移到對方節點
[[email protected] ~]# service mysqld status #可以看到服務已自動重新啟動
mysqld (pid 4783) is running...
模拟資源轉移
crm(live)# node standby #強制資源轉移
crm(live)# status
...
Node node1: standby
Online: [ node2 ]
Master/Slave Set: ms_mydrbd [mydrbd]
Slaves: [ node1 node2 ]
Resource Group: myservice
myip (ocf::heartbeat:IPaddr): Started node2
mystore (ocf::heartbeat:Filesystem): FAILED node2
myserver (lsb:mysqld): Stopped
Failed actions: #顯示有錯誤資訊
mystore_start_0 on node2 ‘unknown error‘ (1): call=236, status=complete, last-rc-change=‘Fri Apr 29 15:45:17 2016‘, queued=0ms, exec=69ms
mystore_start_0 on node2 ‘unknown error‘ (1): call=236, status=complete, last-rc-change=‘Fri Apr 29 15:45:17 2016‘, queued=0ms, exec=69ms
crm(live)# resource cleanup mystore #清理資源mystore的狀态
Cleaning up mystore on node1
Cleaning up mystore on node2
Waiting for 2 replies from the CRMd.. OK
crm(live)# status #恢複正常,可以看到資源已成功轉移至node2
...
Node node1: standby
Online: [ node2 ]
Master/Slave Set: ms_mydrbd [mydrbd]
Masters: [ node2 ]
Stopped: [ node1 ]
Resource Group: myservice
myip (ocf::heartbeat:IPaddr): Started node2
mystore (ocf::heartbeat:Filesystem): Started node2
myserver (lsb:mysqld): Started node2
crm(live)# node online #讓node1重新上線
#驗證
[[email protected] ~]# ip addr show
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:bd:68:23 brd ff:ff:ff:ff:ff:ff
inet 192.168.30.20/24 brd 192.168.30.255 scope global eth0
inet 192.168.30.100/24 brd 192.168.30.255 scope global secondary eth0
inet6 fe80::20c:29ff:febd:6823/64 scope link
valid_lft forever preferred_lft forever
[[email protected] ~]# mysql
...
mysql> show databases; #以node2上可以看到剛才在node1上建立的新庫
+--------------------+
| Database |
+--------------------+
| information_schema |
| hellodb |
| mysql |
| test |
| testdb |
+--------------------+
5 rows in set (0.16 sec)
mysql>