厚臉皮引流
自旋鎖是一個很神奇的東西,一個介于高效和低效之間的一個
『薛定谔』?
的互斥機制。
自旋鎖的效率和它的應用場景有很大關系,在實際生産過程中,我們能在很多地方看見它的身影。
比如Linux kernal有挺多地方用到spinlock、 Nginx也有用到spinlock, 但很多時候自旋鎖在很多場景下并不能很好的發揮出它的高效優勢。
究竟什麼時候我們應該使用SpinLock?
首先,要注意的是自旋鎖隻适用于多核心狀态下(這個多核心指的是目前程序可用的核心數 > 1), 比如說你是一個8核Mac,但是你在一個限制1核的Docker環境中用SpinLock,卵用也沒有!!!
本質上,SpinLock之是以有效就是假定,目前存在另外一個CPU核心正在使用你所需要的資源。CPU隻有一個你等也是白等。 (就好像一個癡漢暗戀一個人一樣,劃掉?)
其次,SpinLock之是以在一些場景下很高效是因為旋等消耗的時鐘周期遠小于上下文交換産生的時間。
我們來回顧一下Mutex 睡眠等待的過程。首先是嘗試上一次鎖,如果不行的話就通過排程算法找到一個優先級更高的Thread,然後才是儲存寄存器,寫回被修改的資料,然後才是交換上下文。
可以看到這個代價是十分大的,而且交換上下文的代價是要✖️2的。一般來說,這個代價,在幾千~幾十萬時鐘周期。回顧一下一個4GHz的8代處理器,一個時間周期=0.25ns。交換一次的代價還是挺可觀的。
是以我們使用SpinLock的時候就需要保證我們的臨界區代碼,能夠在這個時鐘周期之類完成所有任務。
是以一般spinLock等待的代碼不會太長,一般幾行(具體需要看晶片和編譯環境),更不可能是I/O等待型的任務。(在XV6中,關于檔案系統的操作都單獨使用基于SpinLock的SleepLock)
然後,其實SpinLock更适合系統态,不太适合使用者态。因為你使用者态沒法知道有沒有另外一個CPU在處理你所需要的資源。而且SpinLock并不适合多線程搶占一個資源的場景,比如說開了60個線程搶占一個一個記憶體資源,這個競争、等待的代價就是超級大的一個數。
是以,其實自旋鎖的優勢、劣勢都很明顯,怎麼來更好的用好它就是程式員??的事情啦。
SpinLock in XV6
XV6其實是一個很Unix的教學作業系統,通過對XV6代碼的閱讀,我們其實能夠以更少代價來了解Unix是怎麼做的。
SpinLock在XV6中定義在<spinlock.h>和<spinlock.c>兩個檔案中,實際上代碼量不過100行,是很好的分析案例。
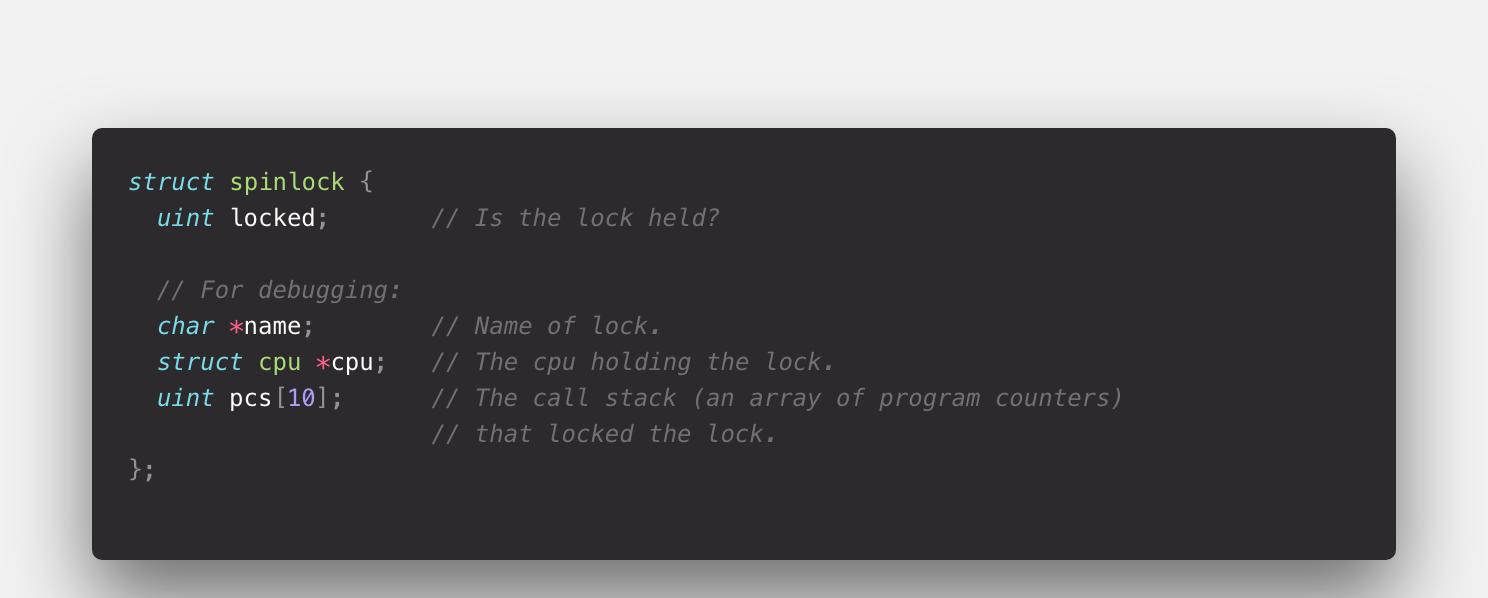
首先, SpinLock類中用了一個unsigned int 來表示是否被上鎖,然後還有lock的名字,被哪個CPU占用,還記錄了系統調用棧(這個實際上就是完全用來調試用的,當然一個健壯的OS需要方方面面考慮到)。

當我們需要去獲得這個鎖的時候,它會先去關中斷,再去檢查這個鎖有沒有被目前的CPU占用,然後是一個嘗試上鎖的循環,最後是标記被占用的CPU,記錄系統調用棧。
總的來說思路比較清晰,我們來看一下具體實作細節。
pushcli函數是用來實作關中斷過程的一個函數,先會去調用readeflags這個函數來讀取堆棧EFLAGS, 然後調用cli來實作關中斷。
如果是第一個進行關中斷的(嵌套關中斷數是0),則還會去再check一下elfags是不是不等于關中斷常量
FL_IF
。
而readeflags()和cli()這兩個函數都是通過内聯彙編來實作的。
readeflags, 就是先去把efalgs寄存器目前内容儲存到EFLAGS堆棧中,然後把EFLAGS堆棧中的值給到eflags變量。
而cli()就很簡單粗暴的調用cli彙編指令。
當我們關中斷之後,會去檢查目前CPU有沒有持有這個SpinLock。
如果已經持有這個SpinLock則會退出。
當完成這一系列正常操作之後,才是最關鍵的擷取鎖的步驟。
他會去調用xchg()這個内聯彙編函數。會去執行
lock; xchgl %0, %1
這個彙編代碼。
最關鍵的實際上是
xchgl
這個指令, 從效果上看xchgl 做的是一個交換兩個變量,并傳回第一個變量這個事情。
實際上這個指令,首先是一個原子性的操作,當然,這我們可以了解畢竟是多核狀态,如果有好幾個CPU核心來搶占同一個SpinLock,需要保證互斥性, 需要排他來通路這塊記憶體空間。
其次xchgl是一個Intel CPU的鎖總線操作,對應到彙編上,就是自帶lock指令字首,就算前面沒有加
lock;
這個操作也是原子性的。
其次,既然是鎖總線操作,就有可能失敗,這個指令式非阻塞的,每次執行隻是一次嘗試,是以這個while就說的通了。通過循環嘗試上鎖,來實作旋鎖機制。
最後,這條指令還用到了一個 read-modify-write的操作,這個操作,主要是因為在現代CPU中基本上都會使用Out of Order來對指令執行進行并行優化。
但是我們這個加鎖的過程是一個嚴格的時序依賴過程,我們必須保證,前面一個CPU加上了鎖,後面CPU來查詢的時候都顯示已經上鎖了。即read-modify-write順序執行。
在XV6 和 後面分析的Linux實際上都是用
__sync_synchronize
來實作這個過程的。
至此,XV6 SpinLock最關鍵的部分就解讀完了。
當已經拿到SpinLock的時候,就回去更新cpu,call stack來給DeBug使用。
實際上這段代碼是依次向前周遊,來獲得棧底EBP,棧頂ESP,下一個指令位址EIP位址。
釋放也是相同的套路。
先去康康你這個SpinLock是不是已經被釋放了,然後取清空call stack, cpu,最後再來修改locked位。
這個地方就不用旋等,因為一個SpinLock隻會被一個CPU占用。
最後是關中斷
還是一樣去檢查ELFAGS堆棧和中斷可用常量相不相等。
檢查目前CPU的嵌套中斷數是否大于0.
然後再來檢查cpu中斷标志是否不為0,最後再來開中斷
SleepLock in XV6
前面說到,實際上SpinLock不适用于臨界區是I/O等待的情況,是以在XV6中,關于檔案系統的鎖機制是用SleepLock來實作的。
SleepLock定義在<proc.c>檔案中
在這裡在正常檢查之後,并沒有之前去請求SpinLock, 而是先去擷取ptable.lock(這也是一個SpinLock)。因為邏輯不相幹,是以這個ptable.lock更容易獲得。
然後釋放SpinLock,以便造成堵塞。然後記錄下睡眠前狀态,把CPU交給排程程式來排程。直到被排程回CPU,先去釋放之前占用的ptable.lock, 然後再來擷取真正需要的SpinLock。
進而實作睡眠鎖,可以看到這個這個睡眠鎖實際上相關于用另外一個SpinLock來做通知的作用,相當于去搶占另外一個不是特别稀缺的資源。
而排程函數
sched()
則是依次去檢查是否已經釋放了ptable.lock,檢查目前cpu的嵌套中斷數,檢查proc的狀态,檢查EFLAGS堆棧。最後才是switch上下文。
SpinLock in Linux
看完XV6的SpinLock實作,再來看Linux的SpinLock實作,就會發現驚人的相似。
本文用Linux kernal 版本号是
4.19.30
.
其實Linux下SpinLock的實作有好多種,上次分析了tryLock,這次來分析最基本的SpinLock.
Linux的SpinLock的Locked是一個叫做slock的變量,具體class定義就不放了,上鎖的函數在linux/spinlock.h>中
spin_lock會去調用raw_spin_lock。而raw_spin_lock這個函數式指向_raw_spin_lock.
而_raw_spin_lock則是一個随着運作環境不同的函數。
當處于非SMP環境時,實際上就變成了一個簡單的禁用核心搶占。
而SMP環境中,則會去調用__raw_spin_lock函數,而這個函數才是真正的實作上鎖功能的函數。
大概思路和XV6基本一緻,先去關中斷,然後鎖的有效性,最後再去真正的上鎖。
而上鎖這個函數LOCK_CONNECT()則是不同環境有不同的實作。
Linux kerenal 中 總共有15個實作,(不知道有沒有數錯)然後以其中幾個為例來具體分析。
以<arch/arc/include/asm/spinlock.h>為例
這個版本的arch_spin_trylock先去聲明一個__sync_synchronize(),這個操作和XV6中read-modify-write中一緻。
然後相同是上鎖,檢查目前上鎖狀态,比較Locked slock, 如果不滿足條件則繼續循環。
當成功上鎖,則更改got_it,并傳回。
實際上這個操作流程和XV6幾乎一樣,同樣的__sync_synchronize() 同樣的判斷加鎖情況,附帶循環比較。
其他版本的arch_spin_trylock大概思路也是相同的, 貼一下部分版本解析。