“ 看書犯困,那是夢開始的地方。”
首先來看一個二進制檔案一般是怎麼建構出來的(拿C++舉例)
- 預處理器進行文本替換、宏展開、删除注釋這類簡單工作,由.cpp檔案得到.i檔案
- 編譯器将文本檔案.i翻譯成文本檔案.s,得到目标平台的彙編語言程式
- 目标平台的彙編器将.s檔案彙編成機器語言.o檔案(Object檔案,也叫目标檔案,也叫子產品)
- 連結器負責連接配接用到的各種庫檔案等資源,最終形成目标平台上可執行的二進制檔案
下面具體看看相關原理
編譯器
前端
- 詞法分析:把程式分割成一個個 Token 的過程,可以通過構造有限自動機來實作(類似于分詞,“我喜歡你”分成“我”、“喜歡”、“你”)
- 文法分析:把程式的結構識别出來,并形成一棵便于由計算機處理的抽象文法樹。可以用遞歸下降的算法來實作(類似于主謂賓)
- 語義分析:消除語義模糊,生成一些屬性資訊,讓計算機能夠依據這些資訊生成目标代碼(類似于記錄語境上下文)
前端得到抽象文法樹,作為中間端的輸入,經過多層翻譯得到各種中間表示IR,最後翻譯出中間代碼
抽象文法樹 -> 中間表示1 -> 中間表示2 -> ... -> 中間代碼
後端
中間代碼交給後端進行代碼優化(包括機器有關的以及機器無關的優化)得到各種cpu架構的目标彙編代碼(彙編語言是機器語言的助記符,各種cpu架構擁有自己的彙編語言,後端要求對各種cpu指令集非常了解)
連結器
連結的過程有點像拼圖,多個目标根據各自的全局符号進行比對拼接
目标檔案
目标檔案的格式跟可執行檔案(PE格式、ELF格式、Math-O格式)的格式基本一緻,隻是還沒有經過連結的過程,其中有些符号或位址還沒有被調整,不能被直接執行起來
靜态連結庫
就是包含了很多目标檔案的檔案包,這些目标檔案之間的引用都已經調整好了
可執行檔案存儲結構的的分段機制
編譯連結後生成的目标檔案被拆分成了頭部和若幹個段
頭部描述了整個檔案的檔案屬性,如下圖所示ELF格式檔案頭:
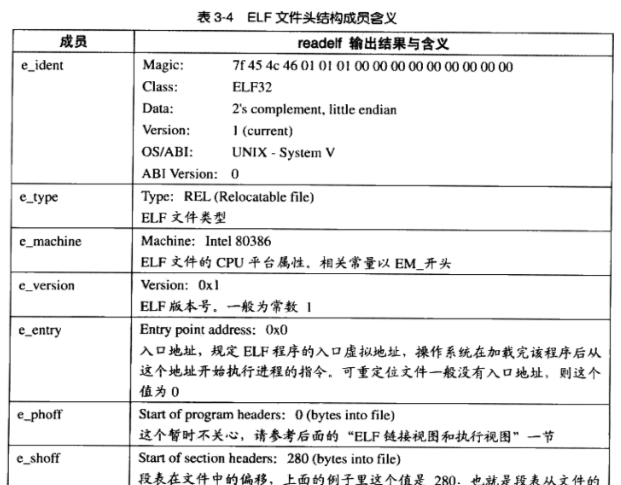

例如下面的例子:
分成了3個段,text(代碼段)、data(資料段,存放已經初始化的全局變量以及局部變量)、bss(存放未初始化的全局變量以及局部變量)
段表中段描述符的成員如下:
其實一般的程式不止這3個段,還有rodata、comment等等,下圖是常見的段
當然我們也可以自己弄一個段放上去,比如一張圖檔,不會影響程式執行
總的來講,目标檔案會被拆分成兩個類型的段:程式指令、程式資料
分段帶來的好處:
- 程式指令段和程式資料段被作業系統加載後放入記憶體,會放到不同的頁中,程式指令段所處的頁設定成隻讀,程式資料段所處的記憶體頁設定為可讀可寫,避免代碼被有意無意改寫
- 把程式指令和資料歸類,對于CPU的緩存命中率會有很大提高
- 很重要的好處:當同一個程式被打開多次,記憶體中的程式指令段以及部分隻讀的資料所在的記憶體頁可以被共享,而無需在記憶體中複制多份,比如系統靜态連結庫、DDL等
符号、符号表
函數以及變量都是符号,函數名和變量名就是符号名,函數、變量的位址就是符号值
符号表存在于每個目标檔案中,記錄着目前程式中所有的符号
符号有以下分類:
- 本程式定義的全局函數以及變量
- 本程式中引用的外部的全局符号
- 段名
- 局部函數以及變量
- 行号資訊,即指令與行号對應關系
最值得關注的是1、2兩種,因為連結過程隻關心全局符号之間的粘合,其他幾種對其他目标檔案都是不可見的
符号表作為一個段存在目标檔案中,段名一般是
.symtab
符号表中每一個符号具有以下内容:
- 符号值
- 符号大小
- 符号類型(未知類型NOTYPE、資料對象OBJECT、函數FUNC、段SECTION、檔案名FILE)
- 符号綁定資訊(局部符号、全局符号、弱引用3種)
- 符号所處的段所在的段表數組下标(也可以是ABS(值為0xfff1,表示這個符号包含了一個絕對的值)、COMMON(值為0xfff2,未初始化的全局符号都是這個類型)、UNDEF(值為0,表示本程式未定義,但引用到,符号處于其他目标檔案中))
- 符号名
符号修飾
在沒有符号修飾之前,任何地方的函數名都不能一樣,甚至目前程式的函數名都不能跟引用到的三方庫中的函數名一樣,因為符号名會沖突
這樣的問題是緻命的,因為很難做到。是以就有了符号修飾
符号修飾就是将函數簽名(函數名以及參數名的集合)轉化成符号名的時候按照某個規則進行适當的修飾
C編譯器僅僅是在函數名前面加一個
_
變成符号名,
int func(int)
->
_func
,無疑會有上面說的問題
C++中引入了命名空間,函數隻要在不同命名空間下,名稱一樣也沒關系。即使在同一命名空間下,參數不一樣,函數也可以一樣。是以隻要本程式的命名空間和三方庫的命名空間不一樣,就無需擔心函數名的沖突
這都是因為符号修飾之後,他們能夠得到不一樣的符号名,不會沖突。下面看看GCC編譯器的符号修飾規則
- 所有符号都以
_Z
- 如果函數位于命名空間或者類中,則接着
N
- 然後是命名空間、類的名稱、函數的名稱(名稱前面都有一個字元長度)
- 接着就是參數清單,如果函數位于命名空間或者類中,則緊跟
E
E
i
比如
int func(int)
->
_Z4funci
,
int C::C2::func(int)
->
_ZN1C2C24funcEi
extern "C"的由來
C++編譯器會将
extern "C"
内部的代碼當成C代碼對待,會按照C編譯器的符号修飾規則來生成符号名
有時候C++程式中需要使用某C系統庫,比如libc,因為C庫中的符号都是按照C編譯器的符号修飾規則生成的,如果不在系統頭檔案中使用
extern "C"
,當有C++程式引用這個頭檔案,然後使用C++編譯後,系統頭檔案中内容被C++編譯器處理,函數名被轉換成了跟系統庫符号名不一樣的符号名,這個程式将找不到系統頭檔案中聲明的函數
是以C系統庫如果要實作被C++調用,頭檔案中必須使用
extern "C"
那麼問題來了,C系統庫如果加了
extern "C"
,不就不能被C調用了嗎,這不是水火不容嗎?難道隻能同時實作兩個頭檔案,一個給C用,一個給C++用嗎?這麼未免太過麻煩
下面看
__cplusplus
宏的由來
__cplusplus宏的由來
C++編譯器會在編譯的時候預設定義
__cplusplus
宏,是以可以在代碼中檢查這個宏是否被定義來區分目前編譯器是C編譯器還是C++編譯器
是以頭檔案中隻需加上這樣一段
這樣,一份頭檔案就可以相容C以及C++。幾乎所有的系統頭檔案都使用了這種方式
強引用、弱引用
目标檔案A引用目标檔案B中的函數,如果A中引用是強引用,則B中必須有此函數的符号,否則編譯失敗
但如果是弱引用,則編譯不會報錯,但運作時會報錯。但可以通過判斷避免報錯
重定位表
重定位表中記錄者目标檔案中所有需要進行重定位的符号資訊。
重定位表也位于段中,而且可以有多個重定位表。text段中如果有需要重定位的符号(函數),則對應有一個rel.text段。data段如果有需要重定位的符号(變量),則對應有一個rel.data段
重定位表數組中成員的結構如下:
- 重定位符号所處的虛拟位址相對于段首位址的偏移。比如call test,test是待重定位符号,這裡就是call指令所處的text段的虛拟位址相對于段首位址的偏移
- 重定位的類型(決定如何進行位址修正)
- 重定位符号在符号表數組中的下标
靜态連結
靜态連結就是将多個目标檔案拼接成一個可執行檔案,分為兩步
- 段合并以及虛拟位址(就是線性位址,每個程序都有自以為的線性位址範圍)配置設定。掃描所有目标檔案,将他們的相同段(所有符号表所有符号取并集後放入新段)合并(text、data段就是簡單的附加,符号段是取并集)且為新段配置設定虛拟位址(原目标檔案中都沒有進行虛拟位址配置設定,所有段首位址都是0)
- 根據重定位表進行符号重定位,就是給所有符号重新填充符号值(各個目标檔案的所有符号已經有了值,不過因為各個段的首位址都是0,是以符号值都是可以當作相對段首位址的偏移位址)。比如a.o中test函數的符号,符号值就是函數所處的虛拟位址,其實第一步中為text段配置設定了虛拟位址後,test函數所處的虛拟位址就已經确定了(就是新段中a.o的text段所處位址加上原來的偏移),這一步就将這個位址填入符号表中完成重定位。比如已初始化的全局變量abc的符号,符号值是abc所處的虛拟位址,abc的值放在了data段,第一步中data段被配置設定了虛拟位址,abc所處位址也就确定了。
.a靜态庫
a結尾的靜态庫檔案其實就是多個.o目标檔案打包放在了一起
動态連結
靜态連結是将多個目标檔案連結成一個大的檔案,這樣有一個問題
比如目标A依賴libc.a,目标B也依賴libc.a,那麼A和B都要将libc.a中依賴的目标檔案連結起來得到可執行檔案A1和B1
那麼A1和B1中都含有libc.a中依賴的目标檔案,看着就很備援。假設有一千個這樣的目标A或B,那麼libc.a中的目标檔案會被複制一千次
不僅浪費磁盤空間,更重要的浪費記憶體空間(一千個程式全部裝載入記憶體,libc.a中的目标檔案同樣占有一千份空間)
是以就有了動态連結,目的是對常見庫的複用,達到節省記憶體的目的
動态連結相對靜态連結 有點像 微服務相對單體應用
萬變不離其宗,作業系統類比成Kubernetes,程序類比成微服務
靜态連結則是将兩個微服務的代碼寫到一個項目中構成一個微服務,而動态連結則是保留兩個微服務,A依賴B隻需要在A中配置B的域名,K8s自會根據域名找到B
靜态連結把重定位表中符号的重定位工作放在了裝載前,而動态連結則是放在裝載後,是以動态連結相對更加損耗性能,是一種時間換空間的做法,但是性能損耗并不大,相對于空間的節省,是可以接受的
動态連結其實就是在程式裝載後,動态連結器掃描重定位表,将引用到的動态連結庫的位址進行填充(填充分頁表以及GOT表,完成程式虛拟位址與實體位址的映射關系,且将符号正确指向動态連結庫)
GOT表:就是所有需要動态連結的符号以及符号對應的虛拟位址。靜态連結時可以直接修改代碼段中的符号,但是動态連結不可以,因為裝載後代碼段是隻讀的,是以出現了一個處于資料段的可讀可寫的GOT表,程式裝載後,核心會完善GOT表,程式運作時碰到一個動态連結符号時就從GOT表中查找對應虛拟位址,然後去通路
而且如果代碼段是可寫的,動态連結器可以裝載後修改代碼段中的符号,那麼就做不到多個程序共享,因為符号在每個程序中的虛拟位址都不一樣。是以需要GOT段使代碼段變得與位址無關
不同的程序動态連結到同一個庫時,動态連結庫的資料段會被每個程序複制出一個副本。是以當動态連結庫中有一個全局變量,兩個程序對其的修改各自都不可見,但是一個程序中的兩個線程對其的修改就是可見的
可執行檔案的裝載
可執行檔案要得到執行,必須先載入記憶體,因為CPU是從記憶體取資料的,不是從磁盤
那麼如果一個可執行檔案有100M,但是記憶體隻有50M,怎麼辦,這個程式是不是無法運作?
不是的,現代作業系統都使用了分頁實作動态裝載的技術,是指需要什麼東西就臨時将其載入記憶體
舉例,一開始text段中的入口所處位置往後n頁大小内容被載入記憶體,程式就開始執行,執行期間發現調用的某函數沒有載入記憶體(通過虛拟記憶體查找頁表,發現找到的頁記錄沒有值),處理器觸發頁缺失的硬中斷,控制權交給作業系統
作業系統就會将函數所處位置往後n頁載入記憶體,然後接着執行,又發現一個函數沒有載入記憶體,假設此時記憶體已經滿了
作業系統就會根據一個政策(可能是先進先出或其他政策)把這個函數載入到已經被配置設定的實體位址上,覆寫掉了原來的資料
下面是Linux對ELF檔案的裝載執行過程
- bash下輸入一個指令,比如
ls
- bash程序會調用系統調用fork()建立一個新程序
- 新程序調用execve()系統調用進入核心,接着使用ELF裝載器(如果想裝載EXE檔案,可以實作一個EXE裝載器,但是沒有意義)開始裝載
- 檢查
ls
- 尋找動态連結的.interp段,設定動态連結器路徑
- 根據ELF的header頭資訊,對其進行映射實體記憶體
- 初始化程序環境
- 将系統調用的傳回位址修改成ELF可執行檔案的入口點(虛拟位址)
- 系統調用傳回,開始執行ELF檔案
大小端位元組序
大小端位元組序是指CPU對位元組集的識别順序,大端識别就是順序識别,小端識别則是倒序識别
注意:網絡傳輸的位元組流全部都是大端位元組序
比如記憶體中 0x12 0x34 0x56 0x78 這個位元組集,在大端CPU看來是uint32數字 0x12345678,而在小端CPU看來是uint32數字 0x78563412
又比如uint16數字 0x1234,大端CPU存入記憶體後是 0x12 0x34,小端CPU存入記憶體後确實 0x34 0x12
看下面示範:
那麼該如何判斷本機CPU是大端還是小端呢
戳↙【閱讀原文】