從0開始學架構.實戰篇
38 | 架構師應該如何判斷技術演進的方向?
- 潮流派?
- 保守派?
- 跟風派?
技術演進的動力
1)對于産品類業務,答案看起來很明顯:技術創新推動業務發展!
- 蘋果開發智能手機,将諾基亞推下王座,自己成為全球手機行業的新王者。
- 2G 時代,UC 浏覽器獨創的雲端架構,很好地解決了上網慢的問題;智能機時代,UC 浏覽器又自主研發全新的 U3 核心,兼顧高速、安全、智能及可擴充性,這些技術創新是 UC 浏覽器成為了全球最大的第三方手機浏覽器最強有力的推動力。
2)對于“服務”類的業務,答案和産品類業務正好相反:業務發展推動技術的發展!
例如,選擇 UC 浏覽器還是選擇 QQ 浏覽器,更多的人是根據個人喜好和體驗來決定的;而選擇微信還是 Whatsapp,就不是根據它們之間的功能差異來選擇的,而是根據其規模來選擇的,就像我更喜歡 Whatsapp 的簡潔,但我的朋友和周邊的人都用微信,那我也不得不用微信。
技術演進的模式
明确了技術發展主要的驅動力是業務發展後,我們來看看業務發展究竟是如何驅動技術發展的。
是以,對于架構師來說,判斷業務目前和接下來一段時間的主要複雜度是什麼就非常關鍵。判斷不準确就會導緻投入大量的人力和時間做了對業務沒有作用的事情,判斷準确就能夠做到技術推動業務更加快速發展。那架構師具體應該按照什麼标準來判斷呢?
答案就是基于業務發展階段進行判斷。
39 | 網際網路技術演進的模式
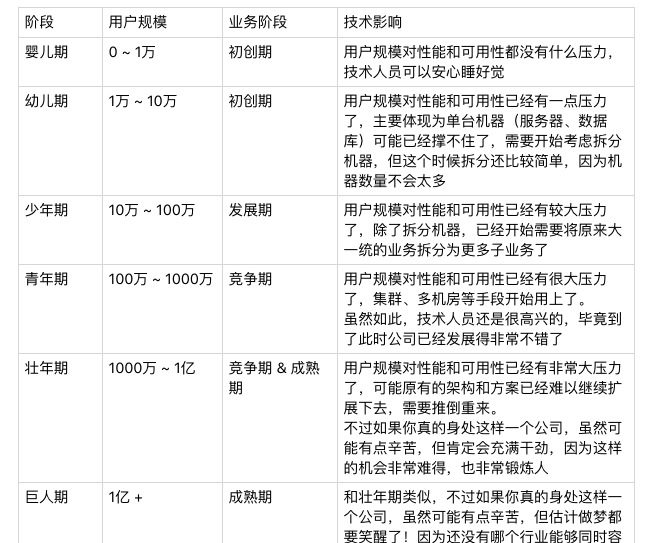
網際網路業務千差萬别,但由于它們具有“規模決定一切”的相同點,其發展路徑也基本上是一緻的。網際網路業務發展一般分為幾個時期:初創期、發展期、競争期、成熟期。
不同時期的差别主要展現在兩個方面:複雜性、使用者規模。
業務複雜性
網際網路業務發展第一個主要方向就是“業務越來越複雜”,我們來看看不同時期業務的複雜性的表現。
- 初創期
- 發展期
- 競争期
- 成熟期
使用者規模
網際網路業務的發展第二個主要方向就是“使用者量越來越大”。網際網路業務的發展會經曆“初創期、發展期、競争期、成熟期”幾個階段,不同階段典型的差别就是使用者量的差别,使用者量随着業務的發展而越來越大。
使用者量增大對技術的影響主要展現在兩個方面:性能要求越來越高、可用性要求越來越高。
量變到質變
40 | 網際網路架構模闆:“存儲層”技術
網際網路的标準技術架構如下圖所示,這張圖基本上涵蓋了網際網路技術公司的大部分技術點,不同的公司隻是在具體的技術實作上稍有差異,但不會跳出這個架構的範疇。

SQL
是以網際網路行業也必須依賴關系資料,考慮到 Oracle 太貴,還需要專人維護,一般情況下網際網路行業都是用 MySQL、PostgreSQL 這類開源資料庫。這類資料庫的特點是開源免費,拿來就用;但缺點是性能相比商業資料庫要差一些。随着網際網路業務的發展,性能要求越來越高,必然要面對一個問題:将資料拆分到多個資料庫執行個體才能滿足業務的性能需求(其實 Oracle 也一樣,隻是時間早晚的問題)。
資料庫拆分滿足了性能的要求,但帶來了複雜度的問題:資料如何拆分、資料如何組合?這個複雜度的問題解決起來并不容易,如果每個業務都去實作一遍,重複造輪子将導緻投入浪費、效率降低,業務開發想快都快不起來。
是以網際網路公司流行的做法是業務發展到一定階段後,就會将這部分功能獨立成中間件,例如百度的 DBProxy、淘寶的 TDDL。不過這部分的技術要求很高,将分庫分表做到自動化和平台化,不是一件容易的事情,是以一般是規模很大的公司才會自己做。中小公司建議使用開源方案,例如 MySQL 官方推薦的 MySQL Router、360 開源的資料庫中間件 Atlas。
假如公司業務繼續發展,規模繼續擴大,SQL 伺服器越來越多,如果每個業務都基于統一的資料庫中間件獨立部署自己的 SQL 叢集,就會導緻新的複雜度問題,具體表現在:
- 資料庫資源使用率不高,比較浪費。
- 各 SQL 叢集分開維護,投入的維護成本越來越高。
是以,實力雄厚的大公司此時一般都會在 SQL 叢集上建構 SQL 存儲平台,以對業務透明的形式提供資源配置設定、資料備份、遷移、容災、讀寫分離、分庫分表等一系列服務,例如淘寶的 UMP(Unified MySQL Platform)系統。
NoSQL
首先 NoSQL 在資料結構上與傳統的 SQL 的不同,例如典型的 Memcache 的 key-value 結構、Redis 的複雜資料結構、MongoDB 的文檔資料結構;其次,NoSQL 無一例外地都會将性能作為自己的一大賣點。NoSQL 的這兩個特點很好地彌補了關系資料庫的不足,是以在網際網路行業 NoSQL 的應用基本上是基礎要求。
由于 NoSQL 方案一般自己本身就提供叢集的功能,例如 Memcache 的一緻性 Hash 叢集、Redis 3.0 的叢集,是以 NoSQL 在剛開始應用時很友善,不像 SQL 分庫分表那麼複雜。一般公司也不會在開始時就考慮将 NoSQL 包裝成存儲平台,但如果公司發展很快,例如 Memcache 的節點有上千甚至幾千時,NoSQL 存儲平台就很有意義了。首先是存儲平台通過集中管理能夠大大提升運維效率;其次是存儲平台可以大大提升資源利用效率,2000 台機器,如果使用率能提升 10%,就可以減少 200 台機器,一年幾十萬元就節省出來了。
是以,NoSQL 發展到一定規模後,通常都會在 NoSQL 叢集的基礎之上再實作統一存儲平台,統一存儲平台主要實作這幾個功能:
- 資源動态按需動态配置設定:例如同一台 Memcache 伺服器,可以根據記憶體使用率,配置設定給多個業務使用。
- 資源自動化管理:例如新業務隻需要申請多少 Memcache 緩存空間就可以了,無需關注具體是哪些 Memcache 伺服器在為自己提供服務。
- 故障自動化處理:例如某台 Memcache 伺服器挂掉後,有另外一台備份 Memcache 伺服器能立刻接管緩存請求,不會導緻丢失很多緩存資料。
當然要發展到這個階段,一般也是大公司才會這麼做,簡單來說就是如果隻有幾十台 NoSQL 伺服器,做存儲平台收益不大;但如果有幾千台 NoSQL 伺服器,NoSQL 存儲平台就能夠産生很大的收益。
小檔案存儲
除了關系型的業務資料,網際網路行業還有很多用于展示的資料。例如,淘寶的商品圖檔、商品描述;Facebook 的使用者圖檔;新浪微網誌的一條微網誌内容等。這些資料具有三個典型特征:一是資料小,一般在 1MB 以下;二是數量巨大,Facebook 在 2013 年每天上傳的照片就達到了 3.5 億張;三是通路量巨大,Facebook 每天的通路量超過 10 億。
和 SQL 和 NoSQL 不同的是,小檔案存儲不一定需要公司或者業務規模很大,基本上認為業務在起步階段就可以考慮做小檔案統一存儲。得益于開源運動的發展和最近幾年大資料的火爆,在開源方案的基礎上封裝一個小檔案存儲平台并不是太難的事情。例如,HBase、Hadoop、Hypertable、FastDFS 等都可以作為小檔案存儲的底層平台,隻需要将這些開源方案再包裝一下基本上就可以用了。
典型的小檔案存儲有:淘寶的 TFS、京東 JFS、Facebook 的 Haystack。
大檔案存儲
網際網路行業的大檔案主要分為兩類:一類是業務上的大資料,例如 Youtube 的視訊、電影網站的電影;另一類是海量的日志資料,例如各種通路日志、記錄檔、使用者軌迹日志等。和小檔案的特點正好相反,大檔案的數量沒有小檔案那麼多,但每個檔案都很大,幾百 MB、幾個 GB 都是常見的,幾十 GB、幾 TB 也是有可能的,是以在存儲上和小檔案有較大差别,不能直接将小檔案存儲系統拿來存儲大檔案。
說到大檔案,特别要提到 Google 和 Yahoo,Google 的 3 篇大資料論文(Bigtable/Map- Reduce/GFS)開啟了一個大資料的時代,而 Yahoo 開源的 Hadoop 系列(HDFS、HBase 等),基本上壟斷了開源界的大資料處理。
對照 Google 的論文建構一套完整的大資料處理方案的難度和成本實在太高,而且開源方案現在也很成熟了,是以大資料存儲和處理這塊反而是最簡單的,因為你沒有太多選擇,隻能用這幾個流行的開源方案,例如,Hadoop、HBase、Storm、Hive 等。實力雄厚一些的大公司會基于這些開源方案,結合自己的業務特點,封裝成大資料平台,例如淘寶的雲梯系統、騰訊的 TDW 系統。
下面是 Hadoop 的生态圈:
41 | 網際網路架構模闆:“開發層”和“服務層”技術
開發層技術
- 開發架構
網際網路公司都會指定一個大的技術方向,然後使用統一的開發架構。例如,Java 相關的開發架構 SSH、SpringMVC、Play,Ruby 的 Ruby on Rails,PHP 的 ThinkPHP,Python 的 Django 等。使用統一的開發架構能夠解決上面提到的各種問題,大大提升組織和團隊的開發效率。
對于架構的選擇,有一個總的原則:優選成熟的架構,避免盲目追逐新技術!
- Web 伺服器
選擇一個伺服器主要和開發語言相關,例如,Java 的有 Tomcat、JBoss、Resin 等,PHP/Python 的用 Nginx,當然最保險的就是用 Apache 了,什麼語言都支援。
- 容器
其中以 Docker 為代表
傳統的虛拟化技術是虛拟機,解決了跨平台的問題,但由于虛拟機太龐大,啟動又慢,運作時太占資源,在網際網路行業并沒有大規模應用;而 Docker 的容器技術,雖然沒有跨平台,但啟動快,幾乎不占資源,推出後立刻就火起來了,預計 Docker 類的容器技術将是技術發展的主流方向。
千萬不要以為 Docker 隻是一個虛拟化或者容器技術,它将在很大程度上改變目前的技術形勢:
- 運維方式會發生革命性的變化:Docker 啟動快,幾乎不占資源,随時啟動和停止,基于 Docker 打造自動化運維、智能化運維将成為主流方式。
- 設計模式會發生本質上的變化:啟動一個新的容器執行個體代價如此低,将鼓勵設計思路朝“微服務”的方向發展。
服務層技術
服務層的主要目标其實就是為了降低系統間互相關聯的複雜度。
- 配置中心
故名思議,配置中心就是集中管理各個系統的配置。
下面是配置中心簡單的設計,其中通過“系統辨別 + host + port”來辨別唯一一個系統運作執行個體是常見的設計方法。
- 服務中心
服務中心就是為了解決上面提到的跨系統依賴的“配置”和“排程”問題。
服務中心的實作一般來說有兩種方式:服務名字系統和服務總線系統。
- 服務名字系統(Service Name System)
類似 DNS
- 服務總線系統(Service Bus System)
類似計算機的總線
“服務名字系統”和“服務總線系統”簡單對比如下表所示。
- 消息隊列
消息隊列就是為了實作這種跨系統異步通知的中間件系統。消息隊列既可以“一對一”通知,也可以“一對多”廣播。以微網誌為例,可以清晰地看到異步通知的實作和作用,如下圖所示。
消息隊列系統基本功能的實作比較簡單,但要做到高性能、高可用、消息時序性、消息事務性則比較難。業界已經有很多成熟的開源實作方案,如果要求不高,基本上拿來用即可,例如,RocketMQ、Kafka、ActiveMQ 等。但如果業務對消息的可靠性、時序、事務性要求較高時,則要深入研究這些開源方案,否則很容易踩坑。
42 | 網際網路架構模闆:“網絡層”技術
負載均衡
顧名思議,負載均衡就是将請求均衡地配置設定到多個系統上。使用負載均衡的原因也很簡單:每個系統的處理能力是有限的,為了應對大容量的通路,必須使用多個系統。例如,一台 32 核 64GB 記憶體的機器,性能測試資料顯示每秒處理 Hello World 的 HTTP 請求不超過 2 萬,實際業務機器處理 HTTP 請求每秒可能才幾百 QPS,而網際網路業務并發超過 1 萬是比較常見的,遇到雙十一、過年發紅包這些極端場景,每秒可以達到幾十萬的請求。
- DNS
DNS 是最簡單也是最常見的負載均衡方式,一般用來實作地理級别的均衡。例如,北方的使用者通路北京的機房,南方的使用者通路廣州的機房。一般不會使用 DNS 來做機器級别的負載均衡,因為太耗費 IP 資源了。例如,百度搜尋可能要 10000 台以上機器,不可能将這麼多機器全部配置公網 IP,然後用 DNS 來做負載均衡。有興趣的讀者可以在 Linux 用“dig baidu.com”指令看看實際上用了幾個 IP 位址。
是以對于時延和故障敏感的業務,有實力的公司可能會嘗試實作HTTP-DNS的功能,即使用 HTTP 協定實作一個私有的 DNS 系統。HTTP-DNS 主要應用在通過 App 提供服務的業務上,因為在 App 端可以實作靈活的伺服器通路政策,如果是 Web 業務,實作起來就比較麻煩一些,因為 URL 的解析是由浏覽器來完成的,隻有 Javascript 的通路可以像 App 那樣實作比較靈活的控制。
- Nginx 、LVS 、F5
DNS 用于實作地理級别的負載均衡,而 Nginx、LVS、F5 用于同一地點内機器級别的負載均衡。其中 Nginx 是軟體的 7 層負載均衡,LVS 是核心的 4 層負載均衡,F5 是硬體的 4 層負載均衡。
軟體和硬體的差別就在于性能,硬體遠遠高于軟體,
Ngxin 的性能是萬級,一般的 Linux 伺服器上裝個 Nginx 大概能到 5 萬 / 秒;
LVS 的性能是十萬級,沒有具體測試過,據說可達到 80 萬 / 秒;
F5 性能是百萬級,從 200 萬 / 秒到 800 萬 / 秒都有。硬體雖然性能高,但是單台硬體的成本也很高,一台最便宜的 F5 都是幾十萬,但是如果按照同等請求量級來計算成本的話,實際上硬體負載均衡裝置可能會更便宜,例如假設每秒處理 100 萬請求,用一台 F5 就夠了,但用 Nginx,可能要 20 台,這樣折算下來用 F5 的成本反而低。
是以通常情況下,如果性能要求不高,可以用軟體負載均衡;如果性能要求很高,推薦用硬體負載均衡。
4 層和 7 層的差別就在于協定和靈活性。Nginx 支援 HTTP、E-mail 協定,而 LVS 和 F5 是 4 層負載均衡,和協定無關,幾乎所有應用都可以做,例如聊天、資料庫等。
目前很多雲服務商都已經提供了負載均衡的産品,例如阿裡雲的 SLB、UCloud 的 ULB 等,中小公司直接購買即可。
CDN
CDN 是為了解決使用者網絡通路時的“最後一公裡”效應,本質上是一種“以空間換時間”的加速政策,即将内容緩存在離使用者最近的地方,使用者通路的是緩存的内容,而不是站點實時的内容。
下面是簡單的 CDN 請求流程示意圖:
CDN 經過多年的發展,已經變成了一個很龐大的體系:分布式存儲、全局負載均衡、網絡重定向、流量控制等都屬于 CDN 的範疇,尤其是在視訊、直播等領域,如果沒有 CDN,使用者是不可能實作流暢觀看内容的。
幸運的是,大部分程式員和架構師都不太需要深入了解 CDN 的細節,因為 CDN 作為網絡的基礎服務,獨立搭建的成本巨大,很少有公司自己設計和搭建 CDN 系統,從 CDN 服務商購買 CDN 服務即可,目前有專門的 CDN 服務商,例如網宿和藍汛;也有雲計算廠家提供 CDN 服務,例如阿裡雲和騰訊雲都提供 CDN 的服務。
多機房
從架構上來說,單機房就是一個全局的網絡單點,在發生比較大的故障或者災害時,單機房難以保證業務的高可用。例如,停電、機房網絡中斷、地震、水災等都有可能導緻一個機房完全癱瘓。
多機房設計最核心的因素就是如何處理時延帶來的影響,常見的政策有:
- 同城多機房
- 跨城多機房
- 跨國多機房
多中心
多中心必須以多機房為前提,但從設計的角度來看,多中心相比多機房是本質上的飛越,難度也高出一個等級。
簡單來說,多機房的主要目标是災備,當機房故障時,可以比較快速地将業務切換到另外一個機房,這種切換操作允許一定時間的中斷(例如,10 分鐘、1 個小時),而且業務也可能有損失(例如,某些未同步的資料不能馬上恢複,或者要等幾天才恢複,甚至永遠都不能恢複了)。是以相比多機房來說,多中心的要求就高多了,要求每個中心都同時對外提供服務,且業務能夠自動在多中心之間切換,故障後不需人工幹預或者很少的人工幹預就能自動恢複。
多中心設計的關鍵就在于“資料一緻性”和“資料事務性”如何保證,這兩個難點都和業務緊密相關,目前沒有很成熟的且通用的解決方案,需要基于業務的特性進行詳細的分析和設計。
43 | 網際網路架構模闆:“使用者層”和“業務層”技術
使用者層技術
- 使用者管理
稍微大一點的網際網路業務,肯定會涉及多個子系統,這些子系統不可能每個都管理這麼龐大的使用者,由此引申出使用者管理的第一個目标:***單點登入(SSO)***,又叫統一登入。單點登入的技術實作手段較多,例如 cookie、JSONP、token 等,目前最成熟的開源單點登入方案當屬 CAS,其架構如下(https://apereo.github.io/cas/4.2.x/planning/Architecture.html )
除此之外,當業務做大成為了平台後,開放成為了促進業務進一步發展的手段,需要允許第三方應用接入,由此引申出使用者管理的第二個目标:授權登入。現在最流行的授權登入就是 OAuth 2.0 協定,基本上已經成為了事實上的标準,如果要做開放平台,則最好用這個協定,私有協定漏洞多,第三方接入也麻煩。
使用者管理的基本架構如下:
- 消息推送
消息推送根據不同的途徑,分為短信、郵件、站内信、App 推送。除了 App,不同的途徑基本上調用不同的 API 即可完成,技術上沒有什麼難度。例如,短信需要依賴營運商的短信接口,郵件需要依賴郵件服務商的郵件接口,站内信是系統提供的消息通知功能。
App 目前主要分為 iOS 和 Android 推送,iOS 系統比較規範和封閉,基本上隻能使用蘋果的 APNS;但 Android 就不一樣了,在國外,用 GCM 和 APNS 差别不大;但是在國内,情況就複雜多了:首先是 GCM 不能用;其次是各個手機廠商都有自己的定制的 Android,消息推送實作也不完全一樣。是以 Android 的消息推送就五花八門了,大部分有實力的大廠,都會自己實作一套消息推送機制,例如阿裡雲移動推送、騰訊信鴿推送、百度雲推送;也有第三方公司提供商業推送服務,例如友盟推送、極光推送等。
- 存儲雲、圖檔雲
存儲雲和圖檔雲通常的實作都是“CDN + 小檔案存儲”
業務層技術
業務層面對的主要技術挑戰是“複雜度”。
複雜度越來越高的一個主要原因就是系統越來越龐大,業務越來越多。幸運的是,面對業務層的技術挑戰,我們有一把“屠龍寶刀”,不管什麼業務難題,用上“屠龍寶刀”問題都能迎刃而解。這把“屠龍寶刀”就是“拆”,化整為零、分而治之,将整體複雜性分散到多個子業務或者子系統裡面去。具體拆的方式你可以檢視專欄前面可擴充架構模式部分的分層架構、微服務、微核心等。
我以一個簡單的電商系統為例,如下圖所示。
随着子系統數量越來越多,如果達到幾百上千,另外一個複雜度問題又會凸顯出來:子系統數量太多,已經沒有人能夠說清楚業務的調用流程了,出了問題排查也會特别複雜。此時應該怎麼處理呢,總不可能又将子系統合成大系統吧?最終答案還是“合”,正所謂“合久必分、分久必合”,但合的方式不一樣,此時采取的“合”的方式是按照“高内聚、低耦合”的原則,将職責關聯比較強的子系統合成一個***虛拟業務域***,然後通過網關對外統一呈現,類似于設計模式中的 Facade 模式。同樣以電商為樣例,采用虛拟業務域後,其架構如下:
虛拟業務域劃分的粒度需要粗一些還是要細一些?你建議虛拟業務域的數量大概是多少,理由是什麼?
粗一些比較好,5±2原則比較合适
44 | 網際網路架構模闆:“平台”技術
運維平台
運維平台核心的職責分為四大塊:配置、部署、監控、應急,每個職責對應系統生命周期的一個階段,如下圖所示。
運維平台的核心設計要素是“四化”:标準化、平台化、自動化、可視化。
測試平台
測試平台核心的職責當然就是測試了,包括單元測試、內建測試、接口測試、性能測試等,都可以在測試平台來完成。
測試平台的核心目的是提升測試效率,進而提升産品品質,其設計關鍵就是自動化。傳統的測試方式是測試人員手工執行測試用例,測試效率低,重複的工作多。通過測試平台提供的自動化能力,測試用例能夠重複執行,無須人工參與,大大提升了測試效率。
為了達到“自動化”的目标,測試平台的基本架構如下圖所示。
資料平台
資料平台的核心職責主要包括三部分:資料管理、資料分析和資料應用。每一部分又包含更多的細分領域,詳細的資料平台架構如下圖所示。
管理平台
管理平台的核心職責就是權限管理,無論是業務系統(例如,淘寶網)、中間件系統(例如,消息隊列 Kafka),還是平台系統(例如,運維平台),都需要進行管理。如果每個系統都自己來實作權限管理,效率太低,重複工作很多,是以需要統一的管理平台來管理所有的系統的權限。
權限管理主要分為兩部分:身份認證、權限控制,其基本架構如下圖所示。
45 | 架構重構内功心法第一式:有的放矢
期望通過架構重構來解決所有問題當然是不現實的,是以架構師的首要任務是從一大堆紛繁複雜的問題中識别出真正要通過架構重構來解決的問題,集中力量快速解決,而不是想着通過架構重構來解決所有的問題。
- 背景系統重構:解決不合理的耦合
M 系統是一個背景管理系統,負責管理所有遊戲相關的資料,重構的主要原因是因為系統耦合了 P 業務獨有的資料和所有業務公用的資料,導緻可擴充性比較差。其大概架構如下圖所示。
針對 M 系統存在的問題,重構目标就是将遊戲資料和業務資料拆分,解開兩者的耦合,使得兩個系統都能夠獨立快速發展。重構的方案如下圖所示。
- 遊戲接入系統重構:解決全局單點的可用性問題
S 系統是遊戲接入的核心系統,一旦 S 系統故障,大量遊戲玩家就不能登入遊戲。而 S 系統并不具備多中心的能力,一旦主機房當機,整個 S 系統業務就不可用了。其大概架構如下圖所示,可以看出資料庫主庫是全局單點,一旦資料庫主庫不可用,兩個叢集的寫業務都不可用了。
針對 S 系統存在的問題,重構目标就是實作雙中心,使得任意一個機房都能夠提供完整的服務,在某個機房故障時,另外一個機房能夠全部接管所有業務。重構方案如下圖所示。
3.X 系統:解決大系統帶來的開發效率問題
X 系統是創新業務的主系統,之前在業務快速嘗試和快速發展期間,怎麼友善怎麼操作,怎麼快速怎麼做,系統設計并未投入太多精力和時間,很多東西都“塞”到同一個系統中,導緻到了現在已經改不動了。做一個新功能或者新業務,需要花費大量的時間來讨論和梳理各種業務邏輯,一不小心就踩個大坑。X 系統的架構如下圖所示。
針對 X 系統存在的問題,重構目标是将各個功能拆分到不同的子系統中,降低單個系統的複雜度。重構後的架構如下圖所示(僅僅是示例,實際架構遠比下圖複雜)。
小結
架構重構内功心法的第一式:有的放矢,需要架構師透過問題表象看到問題本質,找出真正需要通過架構重構解決的核心問題,而不是想着通過一次重構解決所有問題。
46 | 架構重構内功心法第二式:合縱連橫
合縱
架構重構是大動作,持續時間比較長,而且會占用一定的研發資源,包括開發和測試,是以不可避免地會影響業務功能的開發。是以,要想真正推動一個架構重構項目啟動,需要花費大量的精力進行遊說和溝通。
是以在溝通協調時,将技術語言轉換為通俗語言,以事實說話,以資料說話,是溝通的關鍵!
連橫
那如何才能有效地推動呢?有效的政策是“換位思考、合作雙赢、關注長期”。簡單來說就是站在對方的角度思考,重構對他有什麼好處,能夠幫他解決什麼問題,帶來什麼收益。
47 | 架構重構内功心法第三式:運籌帷幄
架構師在識别系統關鍵的複雜度問題後,還需要識别為了解決這個問題,需要做哪些準備事項,或者還要先解決哪些問題。這就需要我今天要和你分享的架構重構内功心法第三式:運籌帷幄。
基于這些分析,我們制定了總體的政策,如下圖所示。
總結一下重構的做法,其實就是“分段實施”,将要解決的問題根據優先級、重要性、實施難度等劃分為不同的階段,每個階段聚焦于一個整體的目标,集中精力和資源解決一類問題。
具體如何制定“分段實施”的政策呢?分享一下我的經驗。
- 優先級排序
- 問題分類
- 先易後難
- 循序漸進。每個階段最少 1 個月,最長不要超過 3 個月,如果評估超過 3 個月的,那就再拆分為更多階段。
48 | 再談開源項目:如何選擇、使用以及二次開發?
軟體開發領域有一個流行的原則:DRY,Don’t repeat yourself。翻譯過來更通俗易懂:不要重複造輪子。開源項目的主要目的是共享,其實就是為了讓大家不要重複造輪子,尤其是在網際網路這樣一個快速發展的領域,速度就是生命,引入開源項目可以節省大量的人力和時間,大大加快業務的發展速度,何樂而不為呢?
選:如何選擇一個開源項目
- 聚焦是否滿足業務
- 聚焦是否成熟
- 聚焦運維能力
用:如何使用開源項目
- 深入研究,仔細測試
- 小心應用,灰階釋出
- 做好應急,以防萬一
改:如何基于開源項目做二次開發
- 保持純潔,加以包裝
- 發明你要的輪子
49 | 談談App架構的演進
首先,先來複習一下我的專欄所講述的架構設計理念,可以提煉為下面幾個關鍵點:
- 架構是系統的頂層結構。
- 架構設計的主要目的是為了解決軟體系統複雜度帶來的問題。
- 架構設計需要遵循三個主要原則:合适原則、簡單原則、演化原則。
- 架構設計首先要掌握業界已經成熟的各種架構模式,然後再進行優化、調整、創新。
Web App
最早的 App 有很多采用這種架構,大多數嘗試性的業務,一開始也是這樣的架構。Web App 架構又叫包殼架構,簡單來說就是在 Web 的業務上包裝一個 App 的殼,業務邏輯完全還是 Web 實作,App 殼完成安裝的功能,讓使用者看起來像是在使用 App,實際上和用浏覽器通路 PC 網站沒有太大差别。
原生 App
是以,随着業務發展和技術演進,移動開發的複雜度從“快速開發”和“低成本”轉向了“使用者體驗”,而要保證使用者體驗,采用原生 App 的架構是最合适的,這裡的架構設計遵循“演化原則”。
Hybrid App
為了解決“快速開發”的複雜度問題,大家自然又想到了 Web 的方式,但 Web 的體驗還是遠遠不如原生,怎麼解決這個問題呢?其實沒有辦法完美解決,但可以根據不同的業務要求選取不同的方案,例如對體驗要求高的業務采用原生 App 實作,對體驗要求不高的可以采用 Web 的方式實作,這就是 Hybrid App 架構的核心設計思想,主要遵循架構設計的“合适原則”。
元件化 & 容器化
在這種業務背景下,元件化和容器化架構應運而生,其基本思想都是将超級 App 拆分為衆多元件,這些元件遵循預先制定好的規範,獨立開發、獨立測試、獨立上線。如果某個元件依賴其他元件,元件之間通過消息系統進行通信,通過這種方式來實作元件隔離,進而避免各個團隊之間的互相依賴和影響,以提升團隊開發效率和整個系統的可擴充性。元件化和容器化的架構出現遵循架構設計的“演化原則”,隻有當業務複雜度發展到一定規模後才适應,是以我們會看到大廠應用這個架構的比較多,而中小公司的 App,業務沒那麼複雜,其實并不一定需要采用元件化和容器化架構。
對于元件化和容器化并沒有非常嚴格的定義,我了解兩者在規範、拆分、團隊協作方面都是一樣的,差別在于釋出方式,元件化采用的是靜态釋出,即所有的元件各自獨自開發測試,然後跟随 App 的某個版本統一上線;容器化采用的是動态釋出,即容器可以動态加載元件,元件準備好了直接釋出,容器會動态更新元件,無需等待某個版本才能上線。
關于手機淘寶 App 更詳細的架構演進可以參考《Atlas:手淘 Native 容器化架構和思考》,微信 App 的架構演進可以參考《微信 Android 用戶端架構演進之路》
跨平台 App
Facebook 的 React Native、阿裡的 Weex、Google 的 Flutter。
前端的情況也是類似的,有興趣的同學可以看看玉伯的文章《Web 研發模式演變》,專欄裡我就不在贅述了。