引言
DSL,叫“特定領域語言”,是針對某一領域,具有受限表達性的一種計算機程式設計語言。elasticsearch的 query DSL即是針對elasticsearch檢索的一種特定語言。
es的DSL在使用java API通路es時候也特别好用,本文我們詳細了解下es的DSL java API的使用。
在使用java api檢索es時候,我們使用的方式是:
QueryBuilder builders = null;// 重點講這個的構造
SearchResponse response = client.prepareSearch(index)
.setFrom().setSize()
.setTimeout(TimeValue.timeValueMillis())
.setFetchSource(retFields, null)
.setQuery(builders)
.setTypes(type)
.execute().actionGet();
上面查詢API中的setQuery就是指定查詢的DSL,也是本文主要講的。
es版本:5.1.x
query和filter
我們知道,es的查詢分為兩種query和filter,兩種不同的上下文環境用于不同的目的。
query
使用上下文
query字句解決的問題是“文檔和查詢字句比對程度”,并通過一個score分數來具體表示比對程度。
query子句查詢生效條件
直接在search API中指定query參數(通過setQuery),比如設定如下:
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(QueryBuilders.termQuery("val", "field")); // 指定query,使用的是query上下文
System.out.println(requestBuilder.toString()); // 列印查詢語句
SearchResponse response = requestBuilder.execute().actionGet(); // 執行query
在上例中,我們通過設定query參數,使用的就是query上下文查詢。如果通過toString方法列印出來,如下:
"query" : {
"term" : {
"field" : {
"value" : "val",
"boost" :
}
}
}
filter
使用上下文
filter字句解決的問題是“文檔和查詢字句是否比對”,隻有兩種情況YES和NO,不會計算分數。filter字句常用來過濾結構型資料,比如:
- 是否時間字段timestamp處于2015和2016之間
- 是否status字段被設定為true
另外,filter查詢會被es緩存到記憶體以提高性能。
filter字句查詢生效條件
觸發filter上下文有三種情況:
- 在bool查詢中指定filter參數或者must_not參數;
- 在 constant_score查詢中指定filter參數;
- filter aggregation,即filter聚合查詢;
示例
如下一段查詢語句:
GET /_search
{
"query": { ()
"bool": { ()
"must": [
{ "match": { "title": "Search" }}, ()
{ "match": { "content": "Elasticsearch" }} ()
],
"filter": [ ()
{ "term": { "status": "published" }}, ()
{ "range": { "publish_date": { "gte": "2015-01-01" }}} ()
]
}
}
}
說明如下:
(1) query參數表明是query上下文;
(2)(3)(4)bool和兩個match查詢字句處于query上下文,用score表示比對度;
(5) filter參數表明是filter上下文;
(6) (7) term和range子句用于filter上下文,将會過濾掉不比對的文檔,這些查詢語句不會影響match查詢的比對分數;
term級别query
全文檔比對
用于比對所有的文檔,java API使用如下:
MatchAllQueryBuilder allQueryBuilder = QueryBuilders.matchAllQuery(); // match_all比對
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(allQueryBuilder);
SearchResponse response = requestBuilder.execute().actionGet(); // 執行query
上面用于比對index下面所有文檔。
term query
說明:term級别檢索是在es的反向索引中排序的term準确的比對。
場景:
- 結構化資料的查詢,比如數字,日期,enum,而不是全文本字段;
-
低級别查詢,忽略分詞處理;
API使用:
TermQueryBuilder builder = QueryBuilders.termQuery("field", "val"); // 在field字段中查詢val
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
terms query
說明:在指定字段中查詢包含任意一個term的文檔。
API使用:
TermsQueryBuilder builder = QueryBuilders.termsQuery("field", "val1", "val2"); // field中包含val1或者val2
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
rank query
說明:在指定的field中是否包含固定的值(一個範圍值),比如數字,日期,字元串。
API使用:
RangeQueryBuilder builder = QueryBuilders.rangeQuery("age").from().to() // 從到
.includeLower(true) // 是否包含下界,即>=
.includeUpper(true); // 是否包含上界,即<=40
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
exist query
說明:查詢指定的field是否包含任意非null的值。
API使用:
ExistsQueryBuilder builder = QueryBuilders.existsQuery("field"); // 字段field是否非null
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
prefix query
說明:查詢指定的filed是否包含指定的字首開頭的term。
API使用:
PrefixQueryBuilder builder = QueryBuilders.prefixQuery("field", "prefix"); // 字段field是否包含prefix開頭的term
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
wildcard query
說明:查詢指定的field是否包含符合通配符比對的term,通配符支援?和*。
API使用:
WildcardQueryBuilder builder = QueryBuilders.wildcardQuery("field", "a?pre*"); // 字段field是否比對a?pre*
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
其他query
其他還包括ids query,type query,regexp query,類似上面一樣。
全文query
即full text query,一般使用者類似郵件内容、文章内容這樣的全文檢索,每個field對應一個analyzer,即将field内容分詞并建構反向索引。通常也會在執行檢索前對query字元串進行分詞(每個field對應一個analyzer或search_analyzer。
全文query相關API使用參考官網。
DSL的組合
bool query
我們經常遇到如果我的查詢條件是(A || B ) && (C || D)這樣情況時,該如何組織我們的API,這其實就是一個bool組合查詢。
bool查詢是将多種查詢組合在一起,并且每個都對應一個“事件”(即must,should,must_not和filter),四種事件說明如下:
| 事件 | 描述 |
|---|---|
| must | 查詢子句must出現在文檔中,并且會影響文檔得分score |
| filter | 查詢子句must出現在文檔中,但是不會影響文檔得分,并且會緩存 |
| should | 查詢子句should出現在文檔中,即并列的should子句必須有一個或者多個出現在文檔中,可以通過設定參數 minimum_should_match來指定最少比對的查詢子句 |
| must_not | 查詢子句一定不能出現在文檔中,處于filter上下文,不影響文檔得分,會被緩存 |
是以,bool組合查詢條件就像建構一棵樹一樣,按照我們的邏輯構造bool查詢即可,比如上述的(A || B ) && (C || D)組合構造結構如下圖:
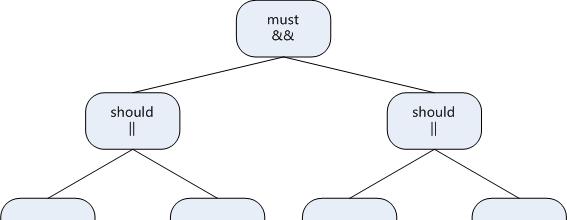
使用java api編寫代碼如下:
BoolQueryBuilder builder = QueryBuilders.boolQuery();
BoolQueryBuilder shoud1 = QueryBuilders.boolQuery();
TermQueryBuilder tqbA = QueryBuilders.termQuery("fieldA", "A");
TermQueryBuilder tqbB = QueryBuilders.termQuery("fieldB", "B");
shoud1.should(tqbA);
shoud1.should(tqbB);
BoolQueryBuilder shoud2 = QueryBuilders.boolQuery();
TermQueryBuilder tqbC = QueryBuilders.termQuery("fieldC", "C");
TermQueryBuilder tqbD = QueryBuilders.termQuery("fieldD", "D");
shoud2.should(tqbC);
shoud2.should(tqbD);
builder.must(shoud1);
builder.must(shoud2);
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
boosting query
在實際使用過程中,我們經常用到的是,對于不同關鍵詞的查詢,我們希望不同term詞對查詢結果得分score的影響不同,即不同查詢詞的權重不同;還有一種情況就是,我們希望包含某些查詢詞的文檔降級(而不是直接過濾掉),這時候就可以用到我們的booting查詢了。
指定boost值得java示例如下:
BoolQueryBuilder builder = QueryBuilders.boolQuery();
TermQueryBuilder tqbA = QueryBuilders.termQuery("fieldA", "A").boost(f);
TermQueryBuilder tqbB = QueryBuilders.termQuery("fieldB", "B").boost(f);
TermQueryBuilder tqbC = QueryBuilders.termQuery("fieldC", "C").boost(f);
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
同樣,也可以直接使用boost query,示例如下:
TermQueryBuilder tqbA = QueryBuilders.termQuery("fieldA", "A");
TermQueryBuilder tqbB = QueryBuilders.termQuery("fieldB", "B");
BoostingQueryBuilder builder = QueryBuilders.boostingQuery(tqbA, tqbB).negativeBoost(f); // tqbA提權,tqbB降級
SearchRequestBuilder requestBuilder = client.prepareSearch(index);
requestBuilder.setQuery(builder);
SearchResponse response = requestBuilder.execute().actionGet();
其他組合
除了常用的bool query和boost query,還有其他幾種compound query方式。比如function score query,可以指定計算文檔分數的函數;constant score query,指定每個文檔的分數相同;dis max query,用于指定不同的子查詢分數不同,進而文檔取子查詢中分數最高的一個。 這些可以從官網來去學習了解。
![k8s部署es叢集和kibana[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)