聽首歌開心一下
唉,今天本來是在學習爬取梨視訊的,但是網頁又發生了變化,和老師講的操作又不一樣...而且還變難了...我找了很多資料也實在是不會,隻好學習一下爬取電影試試。話說每天的學習之路都好坎坷啊,各種卡住。但是這個爬取電影我還沒學習,現在去學習一下。
好家夥,經過我的一番努力後,我發現豆瓣電影的頁面是Ajax請求的頁面,Ajax請求就是可以在不重新整理界面的情況下加載頁面的技術,比如說我們平時在網頁浏覽東西,一直往下滑他能夠一直加載,用的就是Ajax請求。是以我爬取不到頁面的資訊(對不起是我不會)。。。
是以臨時降低難度哈哈哈哈,改成爬取豆瓣書單前100,但是後面還有怎麼将他寫入CSV格式的問題,我需要一邊做一邊學,加油嗯!
做了差不多了,就差把資料放進csv裡了,在做的過程中真的很崩潰,發現了超級多問題,一開始就請求錯了網頁,然後換了個網頁,後來得到了書單的名稱,資料的類型有問題,正則也比對不上,縮進又出問題,xpath定位也錯,反反複複一直運作🙁真的好不容易看來我要多加練習,然鵝現在還要學習csv的操作,唉,好難,一度崩潰想哭。現在是自習,複習一下正則好了
回來以後繼續做,感覺我就是個廢物。。。
現在是11點了,我終于!!!太難了TAT!!!看看成果吧...我隻爬取了書名和評分,列标題我還不會添加,真是費盡了千辛萬苦啊。
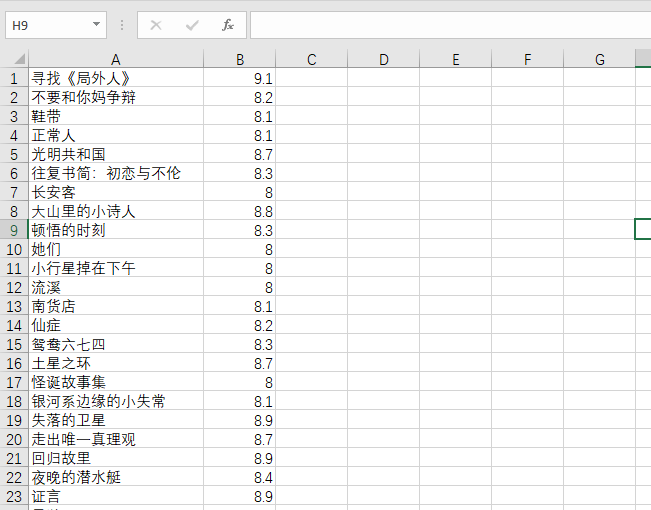
現在貼出代碼并逐漸分析。
首先看一下我們要爬取的頁面:

是可以翻頁的,點選後頁面會重新整理,是以不是Ajax請求的頁面。
這是沒翻頁時的url:
這是翻了一頁後的url:
是以我們可以分析出,我們在翻頁時,隻有start的參數在發生變化,表示的是從第幾本開始的書,第一頁從0開始,第二頁從第25本書開始(也就是說一面有25本書)...後面也以此類推,是以我們可以用param将參數封裝在字典裡傳入get方法中,他會自動幫我們把這些參數放入url中,拼接成圖檔中的那種url。
就是這些參數:
下面開始來寫代碼:
第一步還是導包,都是接下來要用到的。
import requests
from lxml import etree
import csv 複制
接下來就是熟悉的對網頁發請求,擷取頁面的資訊
url = "https://www.douban.com/doulist/114258184/"
# UA僞裝
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
datas = {} # 先建立一個空的字典,友善後面的使用
for page in range(0, 76, 25):
# 擷取的page分别是0,25,50,75 剛好4個頁面,100本書
# 這裡的參數會被傳入到url中
params = {
"start": page,
"sort": "time",
"playable": "0",
"sub_type": "",
}
page_text = requests.get(url=url, headers=headers, params=params).text 複制
接下來就是重頭。
我們進入開發者模式,檢視一下每個頁面每本書的标簽定位,然後用xpath定個位。
可以發現所有的書都在div class="clearfix" 的标簽下的div标簽裡的。
接着是要找出書的書名和評分
這是書的标題所在位置
這是書的評分所在位置:
# 25本書清單
books_list = tree.xpath('//div[@class="doulist-item"]')
# 周遊每本書,這裡用的是枚舉,會有索引相對應
for index, book in enumerate(books_list):
data = {}
# 擷取評分,這裡傳回的是一個清單是以用了索引按順序取出,否則會出錯!所有書的評分相同
book_score = book.xpath("//div[@class='rating']/span[2]/text()")[index]
# 擷取書本的名稱,由于傳回的是清單,是以要用索引取出
book_names = book.xpath(".//div[@class='title']/a/text()")[0]
# 取出書名兩旁的空格
book_name = book_names.strip()
# 将資料寫入字典中
data[book_name] = book_score
# 再字典和總字典datas合并起來
datas.update(data) 複制
最後列印一下結果看看:
得到了一個字典的結果,現在要将他寫入一個CSV檔案中。這一步是我在網上學的直接照着敲的,是以還不明白具體的含義,不過今天的目的總算達成了,以後要多給自己安排一些任務,在寫的過程中發現自己很多地方多此一舉,順便修改了一下代碼,變得更加簡潔了。明天再豐富一下這個檔案,多放幾列資料好了,果然還是要多動手操作,實踐出真知嗯。就到這了,不知不覺12點了,晚安。
with open(r"D:/book.csv", "w", encoding="utf-8-sig", newline='') as fp:
writer = csv.writer(fp)
for key in datas:
writer.writerow([key, datas[key]]) 複制