大家好,又見面了,我是你們的朋友全棧君。
本文章來源于:https://github.com/Zeb-D/my-review ,請star 強力支援,你的支援,就是我的動力。
[TOC]
前言
線上應用業務中,資料庫是一個非常重要的組成部分,特别是現在的微服務架構為了獲得水準擴充能力,我們傾向于将狀态都存儲在資料庫中,這要求資料庫能夠正确、高性能處理請求,但這是一個幾乎不可能達到的要求,是以資料庫的設計者們定義了隔離級别這一個概念,在高性能與正确性之間提供了一個緩沖地帶,明确地告訴使用者,我們提供正确性差一點但是性能好一點的模式和正确性好一點但是性能差一點的模式,使用者可以按照你們的業務場景來選擇使用。
本質
從本質上講,隔離級别是定義資料庫并發控制的。在應用程式的開發中,我們通常利用鎖進行并發控制,確定臨界區的資源不會出現多個線程同時進行讀寫的情況,這對應資料庫的隔離級别為可串行化(最高的隔離級别)。現在發現離級别其實是和我們日常開發經常碰到的一個概念了吧,那麼現在肯定會有一個問題,為什麼在應用程式中可提供可串行化的隔離級别,而資料庫卻不能提供呢?其根本的原因是應用程式的對臨界區都是記憶體操作,資料庫要保證持久性(ACID中的Durability)需要把臨界區的資料持久化到磁盤,磁盤操作比記憶體操作要慢好幾個數量級(一次随機通路記憶體、SSD磁盤和SATA磁盤對應的操作時間分别為幾十納秒、幾十微秒和幾十毫秒),這會導緻臨界區持有鎖時間變長,對臨界區資源競争将變的異常激烈,資料庫的性能會大大降低。
隔離級别
資料庫的隔離級别,SQL-92 标準定義了 4 種隔離級别:讀未送出 (READ UNCOMMITTED)、讀已送出 (READ COMMITTED)、可重複讀 (REPEATABLE READ)、串行化 (SERIALIZABLE)。詳見下表:
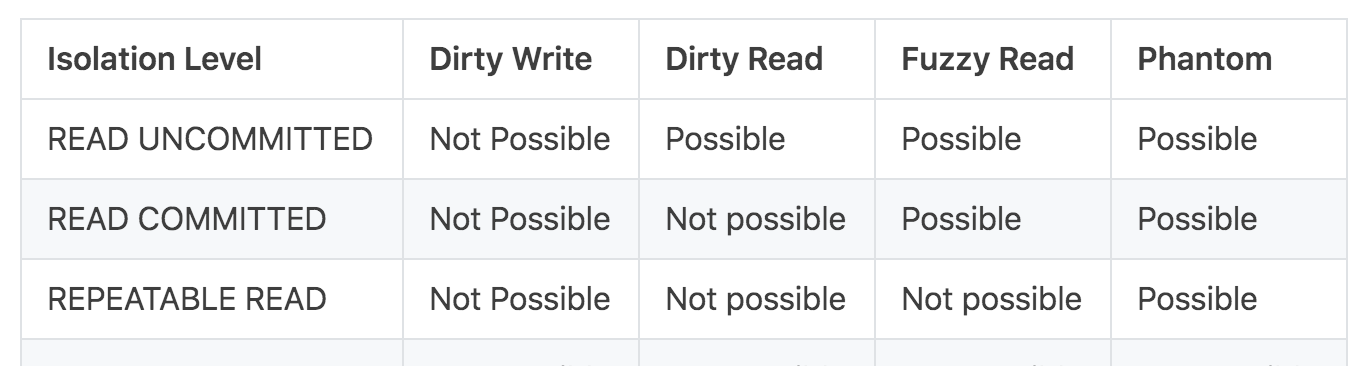
但是由于各資料庫的具體實作各不相同,導緻同一隔離級别可能出現的異常情況也不相同,是以本文直接從各個隔離級别會帶來的異常情況來分析隔離級别的定義。
異常情況
從讀未送出到可串行化,資料庫可能出現的異常為:
髒寫
事務a覆寫了其他事務尚未送出的寫入。
髒讀
事務a讀到了其他事務尚未送出的寫入。
讀傾斜
事務a在執行過程中,對某一個值在不同的時間點讀到了不同的值,也叫不可重複讀。
更新丢失
兩個事務同時執行讀-修改-寫入操作序列,出現了其中一個覆寫了另一個的寫入,但是沒有包含對方最新值的情況,導緻了被覆寫的資料發生了更新丢失。
幻讀
事務先查詢了某些符合條件的資料,同時另一個事務執行寫入,改變了先前的查詢結果。
寫傾斜
事務先查詢資料庫,根據傳回的結果而作出某些決定,然後修改資料庫。在事務送出的時候,支援決定的條件不再成立。寫傾斜是幻讀的一種情況,是由于讀-寫事務沖突導緻的幻讀。寫傾斜也可以看做一種更廣義的更新丢失問題。即如果兩個事務讀取同一組對象,然後更新其中的一部分:不同的事務更新不同的對象,可能發生寫傾斜;不同的事務更新同一個對象,則可能發生髒寫或者更新丢失。
異常避免
對應四個隔離級别,我們分别來看看他們有什麼異常情況,以及怎麼通過應用層的優化來避免該異常的發生:
- 對于髒寫,幾乎所有的資料庫都可以防止,我們用的mysql和TiDB更是沒有問題,是以不讨論髒寫的情況;
- 對于髒讀,提供讀已送出隔離級别及以上的資料庫都可以防止異常的出現,如果業務中不能接受髒讀,那麼隔離級别最少在讀已送出隔離級别或者以上;
- 對于讀傾斜,可重複讀隔離級别及以上的資料庫都可以防止問題的出現,如果業務中不能接受髒讀,那麼隔離級别最少可重複讀隔離級别或者以上;
- 對于更新丢失,幻讀,寫傾斜,如果隻通過資料庫隔離級别來處理的話,那麼隻有可串行化的隔離級别才能防止問題的出現,然而在生産環境中,我們幾乎是不可能開啟可串行化隔離級别的,要麼是資料庫直接不支援,要麼是資料庫支援,但是性能太差。因而在實際開發中,我們隻能在可重複讀的隔離級别的基礎上,通過一些其他的手段來防止問題的發生。
怎麼避免更新丢失
- 如果資料庫提供原子寫操作,那麼一定要避免在應用層代碼中完成“讀-修改-寫”操作,應該直接通過資料庫的原子操作來執行,這樣就可以避免更新丢失的問題。資料庫的原子操作例如關系資料庫中的 udpate table set value=value+1 where key=*,mongodb也提供類似的操作。資料庫的原子操作一般通過獨占鎖來實作,相當于可串行化的隔離級别,是以不會有問題。不過在使用ORM架構的時候,就很容易在應用層代碼中完成“讀-修改-寫”的操作,導緻無法使用資料庫的原子操作。
- 另外一個情況,如果資料庫不支援原子操作,或者在某一些場景,原子操作不能處理的時候,可以通過對查詢結果顯示加鎖來解決。對于mysql來說,就是 select for update,通過for update告訴資料庫,查詢出來的資料行一會是需要更新的,需要加鎖防止其他的事務也來讀取更新導緻更新丢失。
- 一種更好的避免更新丢失的方式是資料庫提供自動檢測更新丢失的機制。資料庫先讓事務都并發執行,如果檢測到有更新丢失的風險,直接中止目前事務,然後業務層在重試即可。目前PostgreSQL和TiDB的可重複讀,Oracle的可串行化等都提供自動檢測更新丢失的機制,但是mysql的InnoDB的可重複讀并不支援。
- 在某一些情況下,還可以通過原子比較和設定來實作,例如:update table set value=newvalue where id=* and value=oldvalue。但是該方式有一個問題,如果where條件的判斷是基于某一個舊快照來執行的,那麼where的判斷是沒有意義的。是以如果要采用原子比較和設定來避免更新丢失,那麼一定要确認資料庫比較-設定操作的安全運作條件。
怎麼避免幻讀中的寫傾斜
在前面的讨論中,我們提供了很多種方式來避免更新丢失,那麼在寫傾斜的時候可以使用嗎?
- 原子操作上不行的,因為涉及到多個對象的更新;
- 所有的資料庫幾乎都沒有自動檢測寫傾斜的機制;
- 資料庫自定義的限制功能對于多個對象也基本不支援;
- 顯式加鎖方式上可以的,通過select for update,可以確定事務以可串行化的隔離級别,是以這個方案上可行的。但這不是對于所有的情況下都适用,例如select for update 如果在select的時候不能查詢到資料,那麼這個時候資料庫無法對資料進行加鎖。例如:在訂閱會議室的時候,select的時候會議室還沒有被訂閱,是以查詢不到,資料庫也沒有辦法進行加鎖,update的時候,多個事務都可以update成功。是以,顯式加鎖對于寫傾斜不能适用的情況是因為在select階段沒有查詢到臨界區的資料,導緻無法加鎖。在這種情況下,我們可以人為的引入用于加鎖的資料,然後通過顯式加鎖來避免寫傾斜的問題。比如在訂閱會議室的問題中,我們為所有的會議室的所有時間都建立好資料,每一個“時間-會議室”一條資料,這個資料沒有其他的意義,隻是用來select for update的時候由于select 查詢到資料,用于資料庫來加鎖。
- 另外一種方式是在資料庫提供可串行化隔離級别,并且性能滿足業務要求時,直接使用可串行化的隔離級别。
TiDB的隔離級别[1]
TiDB 實作了快照隔離 (Snapshot Isolation, SI) 級别的一緻性。為了與 MySQL 保持一緻,又稱其為“可重複讀”。該隔離級别不同于 ANSI 可重複讀隔離級别和 MySQL 可重複讀隔離級别。
當事務隔離級别為可重複讀時,隻能讀到該事務啟動時已經送出的其他事務修改的資料,未送出的資料或在事務啟動後其他事務送出的資料是不可見的。對于本事務而言,事務語句可以看到之前的語句做出的修改。對于運作于不同節點的事務而言,不同僚務啟動和送出的順序取決于從 PD 擷取時間戳的順序。處于可重複讀隔離級别的事務不能并發的更新同一行,當時事務送出時發現該行在該事務啟動後,已經被另一個已送出的事務更新過,那麼該事務會復原并啟動自動重試。示例如下:
create table t1(id int);
insert into t1 values(0);
start transaction; | start transaction;
select * from t1; | select * from t1;
update t1 set id=id+1; | update t1 set id=id+1;
commit; |
| commit; -- 事務送出失敗,復原 複制
與 ANSI 可重複讀隔離級别的差別
盡管名稱是可重複讀隔離級别,但是 TiDB 中可重複讀隔離級别和 ANSI 可重複隔離級别是不同的。按照 A Critique of ANSI SQL Isolation Levels 論文中的标準,TiDB 實作的是論文中的快照隔離級别。該隔離級别不會出現狹義上的幻讀 (A3),但不會阻止廣義上的幻讀 (P3),同時,SI 還會出現寫偏斜,而 ANSI 可重複讀隔離級别不會出現寫偏斜,會出現幻讀。
與 MySQL 可重複讀隔離級别的差別
MySQL 可重複讀隔離級别在更新時并不檢驗目前版本是否可見,也就是說,即使該行在事務啟動後被更新過,同樣可以繼續更新。這種情況在 TiDB 會導緻事務復原,導緻事務最終失敗,而 MySQL 是可以更新成功的。MySQL 的可重複讀隔離級别并非快照隔離級别,MySQL 可重複讀隔離級别的一緻性要弱于快照隔離級别,也弱于 TiDB 的可重複讀隔離級别。
總結
本文我們讨論了資料庫出現隔離級别這個概念的根本原因是資料庫設計者因為要保證持久性,因而有大量的磁盤操作,導緻臨界區變長,性能急劇下降,提出的一個trade-off的方案,讓使用者根據自己的業務場景來選擇不同的隔離級别,然後我們讨論了不同的隔離級别導緻的異常情況的處理方法,確定可以寫出高性能并且正确的程式,最後我們介紹了tidb隔離級别的情況。
參考
- [1] TiDB 事務隔離級别
- [2] Martin Kleppmann.Designing Data-Intensive Applications
- [3] [SQL-92
- 資料庫隔離級别剖析
釋出者:全棧程式員棧長,轉載請注明出處:https://javaforall.cn/141508.html原文連結:https://javaforall.cn