引介
CVPR 2017,所屬領域為Semantic Segmentation.
Abstract
場景解析對于無限制的開放詞彙和不同場景來說是具有挑戰性的.本文使用文中的pyramid pooling module實作基于不同區域的上下文內建,提出了PSPNet,實作利用上下文資訊的能力進行場景解析.
Motivation
作者認為,FCN存在的主要問題是沒有采取合适的政策來用全局的資訊,本文的做法就是借鑒SPPNet來設計了PSPNet解決這個問題.
Introduction
很多State-of-the-art的場景解析架構都是基于FCN的.基于CNN的方法能夠增強動态物體的了解,但是在無限制詞彙和不同場景中仍然面臨挑戰.舉個例子,如下圖.
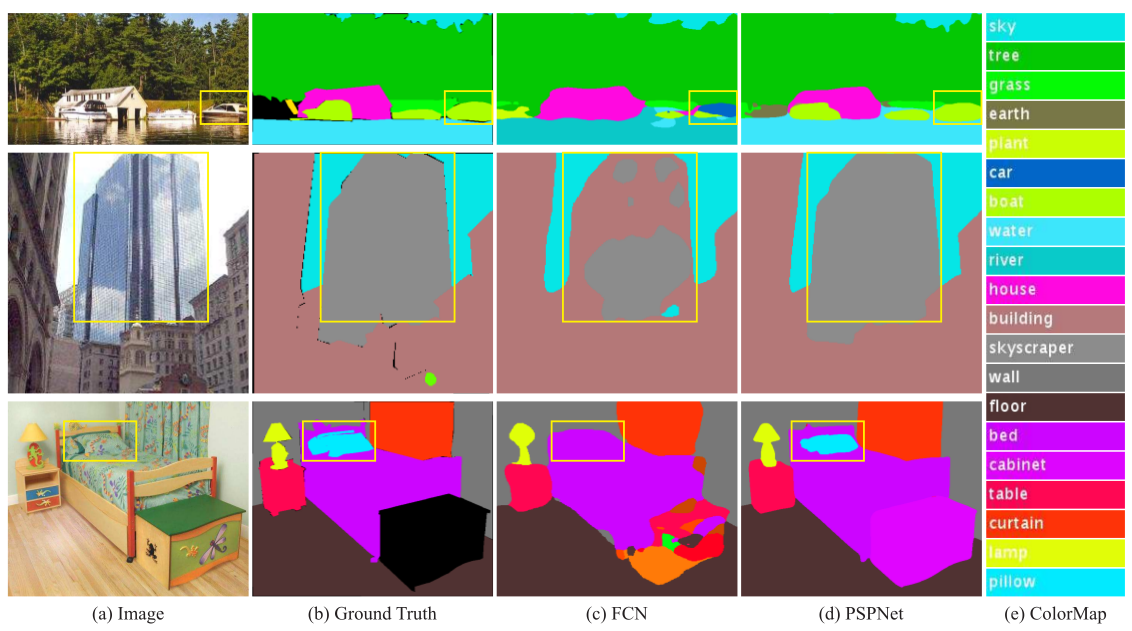
FCN認為右側框中是汽車,但是實際上是船,如果參考上下文的先驗知識,就會發現左邊是一個船屋,進而推斷是框中是船.FCN存在的主要問題就是不能利用好全局的場景線索.
對于尤其複雜的場景了解,之前都是采用空間金字塔池化來做的,和之前方法不同(為什麼不同,需要參考一下經典的金字塔算法),本文提出了pyramid scene parsing network(PSPNet).
最終,本文的方法取得了ImageNet scene parsing2016的第一名,PASCAL VOC 2012 semantic segmentation的第一名,以及Cityscapes的第一名.
本文的主要貢獻如下:
(1)提出了PSPNet在基于FCN的架構中內建困難的上下文特征
(2)通過基于深度監督誤差開發了針對ResNet的高效優化政策
(3)建構了一個用于state-of-the-art的場景解析和語義分割的實踐系統(具體是什麼?)
Related Work
再一次闡述了,基于FCN的方法,隻要有兩個研究方向:一個是multi-scale的特征整合,另一個是結構預測(CRF等).
PSPNet
通過觀察FCN的結果,發現了如下問題:
(1)關系不比對(Mismatched Relationship)
(2)易混淆的類别(Confusion Categories)
(3)不顯眼的類别(Inconspicuous Classes)
總結以上結果發現,以上問題部分或者全部與上下文關系和全局資訊有關系,是以本文提出了PSPNet.架構如下:

Experiments
本文除了使用Pyramid pooling module外,還用了多個tricks:DR(dimension reduction), AL(additionial loss), DA(data augmentation), MS(multi-scale testing).
最後在ADE20k, Pascal VOC 2012, Cityscapes上都是第一.
Conclusion
結果看上去是質的飛躍,感覺trick比較多,沒有太多可服用的東西…
- 一些trick:
- ResNet 103
- poly
- bilinear
- data augmentation: mirror, random resize(0.5 - 2), random rotation(-10 - 10 degress), random gaussian blur
Reference
- [3] deeplabv1
- [4] deeplabv2
- [13] ResNet
- [17] AlexNet
- [24] ParseNet
- [33] VGGNet
- [34] GoogLeNet
- [26] FCN
- [30] DeconvNet
-
[40] F. Yu and V. Koltun. Multi-scale context aggregation by di-
lated convolutions. arXiv:1511.07122, 2015.
- [41] CRFASRNN
相關資料
- 項目首頁: https://hszhao.github.io/projects/pspnet/
- 源代碼(沒有訓練模型檔案): https://github.com/hszhao/PSPNet
- 複現效果似乎不好,參見知乎上的評論:https://www.zhihu.com/question/53356671/answer/144164564