cache監聽一緻性主要是獲得cache的總線通路權,比如core1和core2同時寫入相同的位址,會交由總線進行仲裁,确定哪個核先寫入,在獲得寫入權限後,會通過總線廣播使位址失效。一般的smp架構cpu cache結構如下圖:
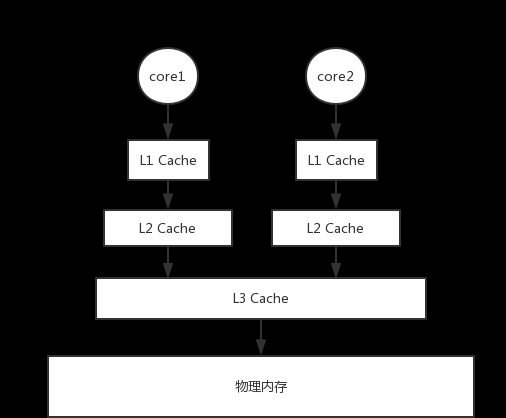
其中分為三級cache,第一級和第二級cache是處理器獨有的,第三級cache是共享的,L1cache分為指令cache,資料cache。intel corei7的L1 指令cache是四路組相聯(cache分組,每組四行,每行64位元組,從記憶體加載到cache時,每次讀取64位元組),資料cache數八路組相聯。所有的資料存儲都是通過cache進行,比如讀一個位址的資料:如果L1cache未命中,則讀取L2cache,如果L2未命中則讀取L3,如果L3未命中,則讀取實體記憶體,讀取時間會越來越慢,L1通路速度大概2-4個時鐘周期,L2大概10個時鐘周期,L3 30-40時鐘周期。讀取成功後會根據L1cache的塊大小,将一塊資料讀取到cache,比如塊大小是64位元組,則一次會從記憶體中讀取64位元組讀到cache。
讀寫cache需要cache一緻性協定保證資料正确,MESI協定規定了一塊記憶體的五種狀态:Modified(M,修改),Exclusive(E,獨占),Share(S,共享),Invalid(I,無效)。
首先看最基本的MSI協定,也可以叫做寫入失效協定。如果同時有多個處理器寫入,總線會進行串行化,同一時刻隻會有一個處理器獲得通路權。比如處理器c1,c2對變量m進行讀寫,采用cache采用回寫方式:
| 處理器操作 | 總線操作 | c1 緩存内容 | c2緩存内容 | 存儲器m所在位址内容 |
|---|---|---|---|---|
| c1讀取m | 緩存沒有m,從存儲器讀取 | |||
| c2讀取m | 緩存沒有m,從存儲器讀取 | |||
| c1寫入1到m | 通知c2緩存的m值,使其失效 | 1 | ||
| c2讀取m的值 | 緩存沒m,從c1的緩存中讀出(采用回寫方式,并且更新到存儲器) | 1 | 1 | 1 |
其中c2第二次讀取m時,c1會将m的最新值傳回給c2,并且更新存儲器m的值,c1,c2 m的值會變成共享狀态。
在詳細介紹MSI協定前,再額外介紹兩個技術:
處理器同時寫入相同的位址串行化技術實作:如果兩個處理器同時寫入共享塊,當它們争用總線時會串行安排它們廣播其失效操作的嘗試。第一個獲得總線通路權限的處理器會使它正寫入塊的所有其它處理器上的副本失效。如果其它處理器嘗試寫入同一塊,則由總線實作寫入操作的串行化。也就是說在獲得總線通路權限之前,無法完成對共享塊的寫入操作。所有的一緻性機制都需要某種方法實作對共享緩存塊的串行通路。
查找最新值在不同的緩存寫回方式下的實作:
緩存直寫方式:在處理器對緩存更新時,會同時寫入到存儲器和低一級的cache,這種方式會大量占用總線。這種方式一緻性協定實作比較簡單,因為所有的資料都會更新到存儲器,是以其他處理器讀取存儲器時都是最新值。
緩存寫回方式:資料的更新并不會立馬反應到存儲器,而是在cache替換時或者變成共享(S)狀态時,發現資料有變動,才會将最新的資料更新到存儲器,這種方式占用總線少,大多數處理器的cache使用這種方式。這種方式實作一緻性協定比較複雜,因為最新值可能存在私有緩存,而不是共享緩存或者存儲器,但是寫回緩存可以為緩存缺失和寫入操作使用相同的監聽機制:每個處理器都監聽放在共享總線上的所有位址。如果發現自己有被請求緩存塊的最新值,它會提供該緩存塊響應請求,并終止存儲器的通路。由于需要從另一個處理器的私有cache(L1或L2)提取資料,是以通路時間會變慢,大概是L3cache的通路速度。
MSI協定 操作分類,狀态分類,請求回應 表
| 請求源 | 請求類型 | 所尋址緩存塊狀态 | 緩存操作類型 | 請求結果 |
|---|---|---|---|---|
| 處理器 | 讀取命中 | 共享(S)或已修改(M) | 正常命中 | 讀取本地緩存資料,并且命中 |
| 處理器 | 讀取缺失 | 無效(I) | 正常缺失 | 将讀取缺失廣播到總線 |
| 處理器 | 讀取缺失 | 共享(S) | 替換 | 位址沖突缺失,需要替換存在的資料塊,将讀取缺失廣播到總線 |
| 處理器 | 讀取缺失 | 已修改(M) | 替換 | 位址沖突缺失;将緩存快寫回存儲器,将讀取缺失廣播到總線 |
| 處理器 | 寫命中 | 已修改(M) | 正常命中 | 将資料寫入本地緩存 |
| 處理器 | 寫命中 | 共享(S) | 一緻性 | 将失效操作廣播到總線,使其它緩存了此塊處理器緩存狀态變為失效 |
| 處理器 | 寫缺失 | 無效 (I) | 正常缺失 | 将寫缺失廣播到總線 |
| 處理器 | 寫缺失 | 共享(S) | 替換 | 位址沖突缺失,将寫缺失廣播到總線 |
| 處理器 | 寫缺失 | 已修改 (M) | 替換 | 位址沖突缺失,将緩存塊寫回到存儲器,并将寫缺失廣播到總線 |
| 總線 | 讀取缺失 | 共享(S) | 無操作 | 其他處理器緩存或者存儲器将缺失的資料提供給廣播讀取缺失的處理器 |
| 總線 | 讀取缺失 | 已修改(M) | 一緻性 | 嘗試共享資料,将緩存塊放到總線,并設定标志位為共享(S) |
| 總線 | 失效 | 共享(S) | 一緻性 | 使共享塊狀态由共享(S)變為失效(I ) |
| 總線 | 寫缺失 | 共享(S) | 一緻性 | 嘗試寫共享塊,使緩存塊失效 |
| 總線 | 寫缺失 | 已修改(M) | 一緻性 | 嘗試将獨占塊寫到其他位置,寫回該緩存塊,并在本地緩存中使其狀态時效 |
MSI狀态轉換圖如下:

MSI協定是最基本最簡單的cache一緻性協定,很多現代處理器都會加入Exclusive(E)獨占狀态,這樣在處理一些操作時可以減少總線通信。比如在先讀取塊然後寫入塊的情況下效率就很高,在MSI協定下,讀取塊會變為S狀态,然後再寫入該塊會導緻cpu發送給總線一個使其它cpu持有該塊失效的信号,如果該塊其它cpu就沒有,那就是一次無效的信号。在MESI協定下,讀取記憶體塊如果其它cpu都是I狀态,則目前cpu該塊會變成E狀态,然後寫入的時候直接寫就可以,不需要發送使該塊失效的信号。
是以MESI協定首先要解決,如何确定沒有其它共享者,而讓本塊變為E狀态,比如可以添加一根共享信号線做或運算,每個cpu在讀取記憶體修改狀态時都要判斷共享信号線,如果共享信号線為1,則将cache塊狀态置為S,否則cache狀态塊置為E。MESI協定和MSI協定最大不同就是其他狀态到S or E狀态,還有E到M狀态,其他和MSI協定沒啥差別。MESI轉換圖如下:
和MSI的主要不同就是E和其它狀态的轉換,其中E到M直接在cpu cache内部轉換不需要通過總線通知其它cpu。
MESI協定在多核cpu下保證了cache資料的一緻性,使每個cpu在讀取資料時都是讀到的最新的資料,也遵守了SWMR(單寫多讀)政策,寫的時候隻能有一個cpu被總線仲裁成功。