作者 | Chilia
哥倫比亞大學・搜尋推薦
整理 | NewBeeNLP
目前大多數的CTR模型采用的是Embedding和Feature Interaction(以下簡稱FI)架構,如下圖所示:
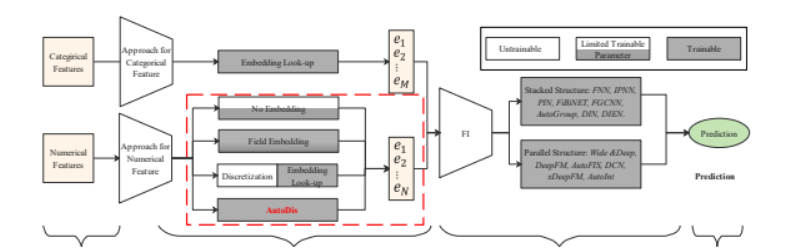
目前大多數的研究主要集中在設計更複雜的網絡架構來更好的捕獲顯式或隐式的「特征互動」,如Wide & Deep的Wide部分、DCN中的CrossNet、DIN中的注意力機制等等。而另一個主要的部分,即「Embedding子產品」同樣十分重要,出于以下兩個原因:
1)Embedding子產品是FI子產品的「上遊子產品」,直接影響FI子產品的效果;
2)CTR模型中的大多數參數集中在Embedding子產品(巨大的embedding table!),對于模型效果有十分重要的影響。
但是,Embedding子產品卻很少有工作進行深入研究,特别是對于連續特征的embedding方面。現有的處理方式由于其硬離散化(hard discretization)的方式,通常suffer from low model capacity。而本文提出的AutoDis架構具有high model capacity, end-to-end training, 以及unique representation.
華為在KDD'21上提出一種AutoDis架構
- An Embedding Learning Framework for Numerical Features in CTR Prediction[1]
已經用于華為的主流廣告平台,線上A/B測試實作2.1%的CTR提升和2.7%的eCPM(effective cost per mille)提升。
1、連續特征處理
CTR預估模型的輸入通常包含連續特征和離散特征兩部分。對于離散特征,通常通過embedding look-up操作轉換為對應的embedding (之後我會介紹谷歌對離散特征embedding的改進);
而對于連續特征的處理,可以概括為三類:No Embedding, Field Embedding和Discretization(離散化)。
1.1 No Embedding
No embedding是指不對連續特征進行embedding操作,而直接使用原始的數值。如Google Play的Wide & Deep直接使用原始值作為輸入;而在Youtube DNN中,則是對原始值進行變換(如平方,開根号)後輸入:

這類對連續特征不進行embedding的方法,由于模型容量有限,通常難以有效捕獲連續特征中資訊。
1.2 Field Embedding
Field Embedding是指同一個field無論取何值,都共享同一個embedding,随後将特征值與其對應的embedding相乘作為模型輸入:
其中, e_1,e_2,...e_n 是field embedding。
由于同一field的特征「共享」同一個embedding,并基于不同的取值對embedding進行「縮放」,這類方法的表達能力也是有限的。
1.3 Discretization
Discretization即将連續特征進行離散化,是工業界最常用的方法。這類方法通常是兩階段的,即首先将連續特征轉換為對應的「離散值」,再通過「look-up」的方式轉換為對應的embedding。
首先探讨一個問題,為什麼需要對連續特征進行離散化呢?或者說離散化為什麼通常能夠帶來更好的效果呢?關于這個問題的探讨,可以參考知乎問題:
- https://www.zhihu.com/question/31989952/answer/54184582
總的來說,将連續特征進行離散化給模型「引入了非線性」,能夠「提升模型表達能力」,而對于離散化的方式,常用的有以下幾種:
1) EDD/EFD (Equal Distance/Frequency Discretization):即等寬/等深分箱。對于等寬分箱,首先基于特征的最大值和最小值、以及要劃分的桶的個數 H_j ,來計算每個樣本取值要放到哪個箱子裡。
對于等深分箱,則是基于資料中特征的頻次進行分桶,每個桶内特征取值的個數是大緻相同的。
2)LD (Logarithm Discretization):對數離散化,其計算公式如下:
3)TD (Tree-based Discretization):基于樹模型的離散化,如使用GBDT+LR來将連續特征分到不同的節點。這就完成了離散化。
「離散化方法的缺點:」
- TPP (Two-Phase Problem):将特征分桶的過程一般使用啟發式的規則(如EDD、EFD)或者其他模型(如GBDT),無法與CTR模型進行一起優化,即「無法做到端到端」訓練;
- SBD (Similar value But Dis-similar embedding):對于邊界值,兩個相近的取值由于被分到了不同的桶中,導緻其embedding可能相差很遠;
- DBS (Dis-similar value But Same embedding):對于同一個桶中的邊界值,兩邊的取值可能相差很遠,但由于在同一桶中,其對應的embedding是完全相同的。
上述的三種局限可以通過下圖進一步了解:
SBD: 40和41歲沒有多大差別,但是卻有完全不同的embedding;DBS: 18和40歲差距甚遠,但是embedding卻一模一樣!
1.4 總結
上述三種對于連續特征的處理方式的總結如下表所示:
可以看到,無論是何種方式,都存在一定的局限性。而本文提出了AutoDis架構,具有「高模型容量」、「端到端訓練」,「每個特征取值具有獨立表示」的特點,接下來對AutoDis進行介紹。
2、AutoDis介紹
AutoDis的全稱為「Auto」matic end-to-end embedding learning framework for numerical features based on soft 「dis」cretization.
AutoDis是一種pluggable embedding framework,可以和現有的深度結構很好的相容:
Autodis用于做連續特征的embedding,如圖中的Age和Height
為了實作高模型容量、端到端訓練,每個特征取值具有獨立表示,AutoDis設計了三個核心的子產品,分别是「Meta-Embeddings、automatic Discretization和 Aggregation」子產品。
2.1 Meta-Embeddings
為了提升model capacity,一種樸素的處理連續特征的方式是給每一個特征取值賦予一個獨立的embedding。顯然,這種方法參數量巨大(因為你可以有無窮個連續特征取值!),無法在實踐中進行使用。另一方面,Field Embedding對同一域内的特征賦予相同的embedding,盡管降低了參數數量,但model capacity也受到了一定的限制。
為了平衡參數數量和模型容量,AutoDis設計了Meta-embedding子產品: 對于第 j 個連續特征,對應 H_j 個Meta-Embedding(可以看作是分 H_j 個桶,每一個桶對應一個embedding)。第j個特征的Meta-Embedding表示為:ME_j \in \mathbb{R}^{H_j \times d} 對于連續特征的一個具體取值,則是通過一定方式将這 Hj 個embedding進行聚合。相較于Field Embedding這種每個field隻對應一個embedding的方法,AutoDis中每一個field對應 H_j 個embedding,提升了模型容量;同時,參數數量也可以通過 H_j 進行很好的控制。
2.2 Automatic Discretization
Automatic Discretization子產品可以對連續特征進行「自動的離散化」,實作了「離散化過程的端到端訓練」。具體來說,對于第 j 個連續特征的具體取值 x_j ,首先通過兩層神經網絡進行轉換,得到 H_j 長度的向量。下圖的例子假設有41個特征,每個特征配置設定 H_j = 10 個桶
最後得到的 \tilde{x_j} 需要經過某種softmax變成機率分布:
傳統的離散化方式是将特征取值分到某一個具體的桶中,即對每個桶的機率進行「argmax」,但這是一種無法進行梯度回傳的方式,是硬離散化。而上式可以看作是一種軟離散化(soft discretization)。對于溫度系數 ,當其接近于0時,得到的分桶機率分布接近于one-hot,當其接近于無窮時,得到的分桶機率分布近似于均勻分布。這種方式也稱為softargmax。
至此,我們得到了 H_j 個桶的embedding以及機率分布。
2.3 Aggregation Function
根據前兩個子產品,已經得到了每個桶的embedding,以及某個特征取值對應分桶的probability distribution,接下來則是如何選擇合适的Aggregation Function對二者進行「聚合」。論文提出了如下幾種方案:
- Max-Pooling:這種方式即「hard」 selection的方式,選擇機率最大的分桶對應的embedding。前面也提到,這種方式會遇到SBD和DBS的問題。
- Top-K-Sum:将機率最大的K個分桶對應的embedding,進行sum-pooling。這種方式不能從根本上解決DBS的問題,同時得到的最終embedding也沒有考慮到具體的機率取值。
- Weighted-Average:根據每個分桶的機率對分桶embedding進行權重求和,這種方式確定了每個不同的特征取值都能有其對應的embedding表示。同時,相近的特征取值往往得到的分桶「機率分布也是相近的」,那麼其得到的embedding也是相近的,可以有效解決SBD和DBS的問題。
是以,其實就是對 H_j 個桶的embedding進行權重求和。
2.4 模型訓練
模型的訓練過程同一般的CTR過程相似,采用二分類的logloss指導模型訓練,損失如下:
3、實驗結果及分析
最後來看一下實驗結果,離線和線上均取得了一點微小的提升:
那麼,AutoDis是否有效解決了SBD和DBS的問題呢?實驗結果也印證了這一點:
右圖:等深分箱,不同的取值都是分開的點,沒有相似度的聯系;左圖:Autodis,相似的取值聚在一起,說明端到端的方法把握了數值的相似性
本文參考資料
[1]An Embedding Learning Framework for Numerical Features in CTR Prediction: https://arxiv.org/pdf/2012.08986.pdf