原文位址:https://www.cnblogs.com/aspwebchh/p/6652855.html
前段時間,公司一個新上線的網站出現頁面響應速度緩慢的問題, 一位負責這個項目的但并不是搞技術的妹子找到我,讓我想辦法提升網站的通路速度 ,因為已經有很多使用者來投訴了。我第一反應覺的是資料庫上的問題,假裝思索了一下,擺着一副深沉炫酷的模樣說:“是不是資料庫查詢上出問題了, 給表加上索引吧”,然後妹子來了一句:“現在我們網站通路量太大,加索引有可能導緻寫入資料時性能下降,影響使用者使用的”。當時我就楞了一下, 有種強行裝逼被拆穿的感覺,在自己的專業領域居然被非專業的同學教育, 面子上真有點挂不住。
其實, 我說這個例子并不是為展現我們公司的同僚們專業能力的強大、做的産品棒、安全性高、性能牛逼, 連非技術的同僚也懂得技術上的細節。事實上我隻是想說明,「資料庫」和「資料庫索引」這兩個東西是在伺服器端開發領域應用最為廣泛的兩個概念,熟練使用資料庫和資料庫索引是開發人員在行業内生存的必備技能,而整天和技術人員打交道的非技術人員們,由于耳濡目染久了,自然也就能講個頭頭是道了。
使用索引很簡單,隻要能寫建立表的語句,就肯定能寫建立索引的語句,要知道這個世界上是不存在不會建立表的伺服器端程式員的。然而, 會使用索引是一回事, 而深入了解索引原理又能恰到好處使用索引又是另一回事,這完全是兩個天差地别的境界(我自己也還沒有達到這層境界)。很大一部份程式員對索引的了解僅限于到“加索引能使查詢變快”這個概念為止。
- 為什麼要給表加上主鍵?
- 為什麼加索引後會使查詢變快?
- 為什麼加索引後會使寫入、修改、删除變慢?
- 什麼情況下要同時在兩個字段上建索引?
這些問題他們可能不一定能說出答案。知道這些問題的答案有什麼好處呢?如果開發的應用使用的資料庫表中隻有1萬條資料,那麼了解與不了解真的沒有差别, 然而, 如果開發的應用有幾百上千萬甚至億級别的資料,那麼不深入了解索引的原理, 寫出來程式就根本跑不動,就好比如果給貨車裝個轎車的引擎,這貨車還能拉的動貨嗎?
接下來就講解一下上面提出的幾個問題,希望對閱讀者有幫助。
網上很多講解索引的文章對索引的描述是這樣的「索引就像書的目錄, 通過書的目錄就準确的定位到了書籍具體的内容」,這句話描述的非常正确, 但就像脫了褲子放屁,說了跟沒說一樣,通過目錄查找書的内容自然是要比一頁一頁的翻書找來的快,同樣使用的索引的人難到會不知道,通過索引定位到資料比直接一條一條的查詢來的快,不然他們為什麼要建索引。
想要了解索引原理必須清楚一種資料結構「平衡樹」(非二叉),也就是b tree或者 b+ tree,重要的事情說三遍:“平衡樹,平衡樹,平衡樹”。當然, 有的資料庫也使用哈希桶作用索引的資料結構 , 然而, 主流的RDBMS都是把平衡樹當做資料表預設的索引資料結構的。
我們平時建表的時候都會為表加上主鍵, 在某些關系資料庫中, 如果建表時不指定主鍵,資料庫會拒絕建表的語句執行。 事實上, 一個加了主鍵的表,并不能被稱之為「表」。一個沒加主鍵的表,它的資料無序的放置在磁盤存儲器上,一行一行的排列的很整齊, 跟我認知中的「表」很接近。如果給表上了主鍵,那麼表在磁盤上的存儲結構就由整齊排列的結構轉變成了樹狀結構,也就是上面說的「平衡樹」結構,換句話說,就是整個表就變成了一個索引。沒錯, 再說一遍, 整個表變成了一個索引,也就是所謂的「聚集索引」。 這就是為什麼一個表隻能有一個主鍵, 一個表隻能有一個「聚集索引」,因為主鍵的作用就是把「表」的資料格式轉換成「索引(平衡樹)」的格式放置。
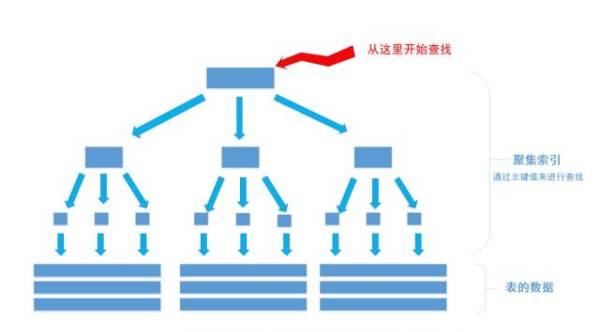
上圖就是帶有主鍵的表(聚集索引)的結構圖。圖畫的不是很好, 将就着看。其中樹的所有結點(底部除外)的資料都是由主鍵字段中的資料構成,也就是通常我們指定主鍵的id字段。最下面部分是真正表中的資料。 假如我們執行一個SQL語句:
select * from table where id = 1256;
首先根據索引定位到1256這個值所在的葉結點,然後再通過葉結點取到id等于1256的資料行。 這裡不講解平衡樹的運作細節, 但是從上圖能看出,樹一共有三層, 從根節點至葉節點隻需要經過三次查找就能得到結果。如下圖

假如一張表有一億條資料 ,需要查找其中某一條資料,按照正常邏輯, 一條一條的去比對的話, 最壞的情況下需要比對一億次才能得到結果,用大O标記法就是O(n)最壞時間複雜度,這是無法接受的,而且這一億條資料顯然不能一次性讀入記憶體供程式使用, 是以, 這一億次比對在不經緩存優化的情況下就是一億次IO開銷,以現在磁盤的IO能力和CPU的運算能力, 有可能需要幾個月才能得出結果 。如果把這張表轉換成平衡樹結構(一棵非常茂盛和節點非常多的樹),假設這棵樹有10層,那麼隻需要10次IO開銷就能查找到所需要的資料, 速度以指數級别提升,用大O标記法就是O(log n),n是記錄總樹,底數是樹的分叉數,結果就是樹的層次數。換言之,查找次數是以樹的分叉數為底,記錄總數的對數,用公式來表示就是
用程式來表示就是Math.Log(100000000,10),100000000是記錄數,10是樹的分叉數(真實環境下分叉數遠不止10), 結果就是查找次數,這裡的結果從億降到了個位數。是以,利用索引會使資料庫查詢有驚人的性能提升。
然而, 事物都是有兩面的, 索引能讓資料庫查詢資料的速度上升, 而使寫入資料的速度下降,原因很簡單的, 因為平衡樹這個結構必須一直維持在一個正确的狀态, 增删改資料都會改變平衡樹各節點中的索引資料内容,破壞樹結構, 是以,在每次資料改變時, DBMS必須去重新梳理樹(索引)的結構以確定它的正确,這會帶來不小的性能開銷,也就是為什麼索引會給查詢以外的操作帶來副作用的原因。
講完聚集索引 , 接下來聊一下非聚集索引, 也就是我們平時經常提起和使用的正常索引。
非聚集索引和聚集索引一樣, 同樣是采用平衡樹作為索引的資料結構。索引樹結構中各節點的值來自于表中的索引字段, 假如給user表的name字段加上索引 , 那麼索引就是由name字段中的值構成,在資料改變時, DBMS需要一直維護索引結構的正确性。如果給表中多個字段加上索引 , 那麼就會出現多個獨立的索引結構,每個索引(非聚集索引)互相之間不存在關聯。 如下圖
每次給字段建一個新索引, 字段中的資料就會被複制一份出來, 用于生成索引。 是以, 給表添加索引,會增加表的體積, 占用磁盤存儲空間。
非聚集索引和聚集索引的差別在于, 通過聚集索引可以查到需要查找的資料, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查找到需要的資料,如下圖
不管以任何方式查詢表, 最終都會利用主鍵通過聚集索引來定位到資料, 聚集索引(主鍵)是通往真實資料所在的唯一路徑。
然而, 有一種例外可以不使用聚集索引就能查詢出所需要的資料, 這種非主流的方法 稱之為「覆寫索引」查詢, 也就是平時所說的複合索引或者多字段索引查詢。 文章上面的内容已經指出, 當為字段建立索引以後, 字段中的内容會被同步到索引之中, 如果為一個索引指定兩個字段, 那麼這個兩個字段的内容都會被同步至索引之中。
先看下面這個SQL語句
//建立索引
create index index_birthday on user_info(birthday);
//查詢生日在1991年11月1日出生使用者的使用者名
select user_name from user_info where birthday = '1991-11-1'
這句SQL語句的執行過程如下
首先,通過非聚集索引index_birthday查找birthday等于1991-11-1的所有記錄的主鍵ID值
然後,通過得到的主鍵ID值執行聚集索引查找,找到主鍵ID值對就的真實資料(資料行)存儲的位置
最後, 從得到的真實資料中取得user_name字段的值傳回, 也就是取得最終的結果
我們把birthday字段上的索引改成雙字段的覆寫索引
create index index_birthday_and_user_name on user_info(birthday, user_name);
這句SQL語句的執行過程就會變為
通過非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的葉節點的内容,然而, 葉節點中除了有user_name表主鍵ID的值以外, user_name字段的值也在裡面, 是以不需要通過主鍵ID值的查找資料行的真實所在, 直接取得葉節點中user_name的值傳回即可。 通過這種覆寫索引直接查找的方式, 可以省略不使用覆寫索引查找的後面兩個步驟, 大大的提高了查詢性能,如下圖
資料庫索引的大緻工作原理就是像文中所述, 然而細節方面可能會略有偏差,這但并不會對概念闡述的結果産生影響 。
最後, 推薦三本關系資料庫方面的書籍, 文中所講解的概念内容都是來自于此。
《SQL Server2005技術内幕之T-SQL查詢》
這本書雖然是針對SQL Server寫的, 但是裡面的大部份内容同樣适用于其它關系資料庫,此書對查詢編寫的技巧和優化講解的非常透徹。
《關系資料庫系統概論》第四版
王珊和薩師煊寫的那本, 是大學計算機教材, 講的通俗易懂, 在國内計算機書圖書出版領域品質是排的上号的。
《資料庫系統概念》
這本書在資料庫領域非常出名, 被稱之為帆船書, 書中内容博大精深,非一朝一夕可參透的。