前言
今天為大家介紹一篇CVPR 2018的一篇目标檢測論文《Single-Shot Refinement Neural Network for Object Detection》,簡稱為RefineDet。RefineDet從網絡結構入手,結合了one-stage目标檢測算法和two-stage目标檢測算法的優點重新設計了一個在精度和速度均為SOTA的目标檢測網絡。論文的思想值得仔細推敲,我們下面來一起看看。論文源碼和一作開源的代碼連結見附錄。
背景
對目标檢測而言,two-stage的算法如Faster-RCNN獲得了最高的精度,而one-stage算法雖然精度低一些,但運作速度非常快。基于此背景,論文提出了一個新的目标檢測器名為RefineDet。RefineDet有兩個核心組成部分,分别是ARM子產品(Anchor Refinement module)和ODM子產品(Object Detection Module)。ARM子產品旨在(1)過濾掉negative anchors,以減少分類器的搜尋空間,(2)粗略調整anchors的位置和大小,為後續的回歸提供更好的初始化。而ODM子產品将修正後的Anchors作為輸入,進一步改善回歸和預測多級标簽。同時論文還設計了TCB子產品(Transfer Connection Block)來傳輸ARM的特征,用于ODM中預測目标的位置,大小和類别标簽。并且整個網絡是端到端的,使用多任務損失來優化。最後RefineDet在PASCAL VOC 2007/2012和MSCOCO資料集上達到SOTA精度和速度。
核心貢獻
- 引入了two-stage目标檢測器中的對box由粗到細的回歸思想(典型的就是Faster-RCNN中先通過RPN得到粗粒度的box資訊,然後再通過正常的回歸支路進行建議不回歸進而得到更準确的資訊,進而獲得了很高的精度)。
- 引入了類似于FPN網絡的特征融合操作用于檢測器,可以提高對小目标檢測的能力,RefineDet檢測的架構仍是為SSD。
網絡結構
RefineDet的網絡結構如Figure1所示:
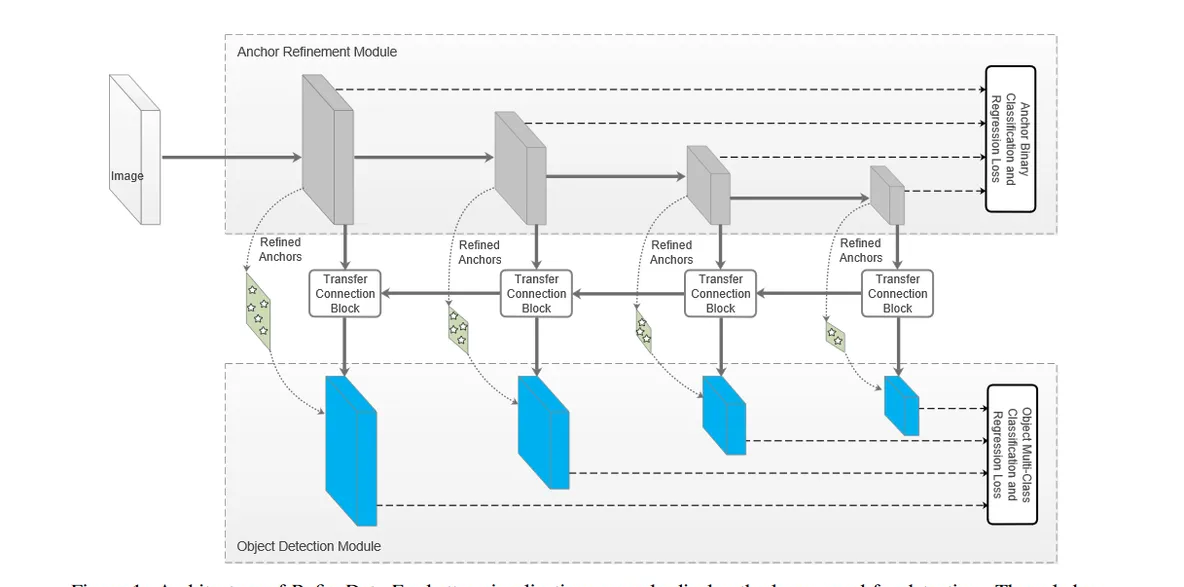
可以看到RefineDet的網絡結構主要包含3個部分,即上面提到的ARM子產品,ODM子產品和Transfer Connection Block子產品。接下來我們就先分析每個子產品最後再宏觀的分析網絡結構。
ARM子產品
Anchor Refinement Module (ARM子產品),這個子產品類似于Faster-RCNN中的RPN網絡,主要用來得到候選框和去除一些負樣本。其實說類似的原因主要是因為這裡的輸入利用了多層特征,而RPN網絡的輸入利用的是單層特征。ARM子產品生成的候選框(ROI)會為後續的檢測網絡提供好的初始資訊,這也是one-stage檢測器和two-stage檢測器的主要差別。
TCB子產品
Transfer Connection Block(TCB)子產品是做特征的轉換操作,即是将ARM部分輸出的特征圖轉換為ODM部分的輸入,從上面的Figure1可以看到這部分和FPN的做法一緻,也是上采樣+特征融合的思想。TCB子產品的詳細結構如Figure2所示,這裡的上采樣使用了步長為2的反卷積,并沒有直接使用Upsampling。

ODM子產品
Object Detection Module(ODM)子產品就和SSD的檢測頭完全一樣了,把經過TCB得到的各個不同尺度的特征接分類和回歸頭就可以了。唯一不同之處在于這部分的輸入Anchors不再是人為設定的,而是由ARM子產品得到的Refined Anchors boxes,類似RPN網絡輸出的Proposal(ROI)。更加值得注意的是,這裡的淺層特征圖(尺寸比較大的藍色塊)融合了高層特征圖的資訊,然後預測目标框是基于每層特征圖進行,最後将各層結果再整合到一起。我們知道在原始的SSD中特征圖是直接拿來做預測的,并沒有特征圖資訊融合的過程,這是一個非常重要的差别,這種差别就導緻了RefineDet對小目标檢測的性能更好。
整體概述
拆解了RefineDet的幾個子子產品後,我們可以全局性的來看一下RefineDet的網絡結構了。這個結構和two-stage目标檢測器很像,即一個ARM子產品做RPN要做的事,ODM子產品做SSD要做的事。我們知道SSD是直接在人為設定的預設框上做回歸,而RefineDet先通過ARM子產品生成Refined Anchors boxes類似于RPN的Propsoal,然後在Refined Anchors boxes的基礎上再進行回歸,加上FPN結構的特征融合使得網絡對小目标的檢測也更加有效。
網絡建構
以
ResNet101
,輸入圖像大小為
320
為例,在ARM子產品的4個灰色的特征圖的尺寸分别為
40x40
,
20x20
,
10x10
,
5x5
,其中前三個是
ResNet101
網絡本身的輸出層,最後
5x5
輸出是另外添加的一個殘差子產品。有了主幹網絡後要做特征融合操作了,首先
5x5
的特征圖經過一個上面介紹過的TCB子產品
P6
得到對應大小的藍色矩形塊,P6代表的是最右邊那個藍色特征圖,對于生成
P6
這條支路來說,沒有反卷積操作。接着基于
10x10
的灰色特征圖經過TCB子產品後得到
P5
,即是左邊數第
3
個藍色特征圖,這個時候TCB子產品有反卷積上采樣操作了,後面的依此類推就可以了。因為我講解的時候打亂了論文的順序,是以接下來再補充一下RefineDet的另外兩個核心點,即雙階段級聯回歸和Anchor的負樣本過濾。
-
雙階段級聯回歸
目前one-stage的目标檢測器依靠具有不同尺度的特征圖一步回歸來預測目标,這在某些場景下是十分不準确的,例如小目标檢測。是以,這篇論文提出了一個兩步級聯回歸政策回歸目标的位置和大小。首先,使用ARM子產品調整Anchors的位置和大小,為ODM子產品提供更好的初始化資訊。然後将
N
Anchor boxes
Anchor boxes
Refined Anchors boxes
Anchors boxes
n
Refined Anchors
Refined Anchors
Refined Anchors
c
c + 4
Refined Anchors boxes
-
負樣本Anchor過濾
one-stage目标檢測器的精度比不過two-stage的一個重要原因是類别不平衡問題,之前介紹了Focal Loss, GIoU Loss,DIoU Loss都是為了改善這個問題,而在這篇論文中,使用的是
Negative Anchor
Anchor
Negative Confidence
大于一個門檻值
θ
\theta
θ(
θ
=
0.99
\theta=0.99
θ=0.99,經驗值),那麼在訓練ODM時将它舍棄。也就是通過
Hard Negative Anchor
Refined anchor
Refined Anchor Box
負置信度大于
θ
\theta
θ,則在ODM進行檢測時丢棄。
訓練和測試細節
資料增強
這部分和SSD一緻,不再贅述,感興趣可以看看我寫的那篇文章:目标檢測算法之SSD的資料增強政策
Backbone網絡
使用在
ILSVRC CLS-LOC
資料集上預訓練的
VGG-16
和
ResNet-101
作為RefineDet中的骨幹網絡。RefineDet也可以在其他預訓練網絡上工作,如
Inception v2
,
Inception ResNe
t和
ResNeXt101
。 與
DeepLab-LargeFOV
類似,通過子采樣參數,将
VGG-16
的
fc6
和
fc7
轉換成卷積層
conv_fc6
和
conv_fc7
。與其他層相比,
conv4_3
和
conv5_3
具有較大的方差,是以使用
L2标準化
,同時如果直接使用标準化會減慢訓練速度,是以設定兩個縮放系數初始值為
10
和
8
,可以在反向傳播的過程中訓練。 同時,為了捕捉高層次多種尺度的資訊指導目标檢測,還分别在剪裁的
VGG-16
和
ResNet101
的末尾添加了額外的卷積層(即
conv6_1
和
conv6_2
)和額外的殘差子產品(即
res6
)。
L2norm的一個解釋
l2norm:Conv4_3層将作為用于檢測的第一個特征圖,該層比較靠前,其norm較大,是以在其後面增加了一個L2 Normalization層,以保證和後面的檢測層差異不是很大.這個和Batch Normalization層不太一樣:其僅僅是對每個像素點在channle次元做歸一化,歸一化後一般設定一個可訓練的放縮變量gamma.而Batch Normalization層是在[batch_size, width, height]三個次元上做歸一化。
代碼實作:
def l2norm(x,scale,trainable=True,scope='L2Normalization'):
n_channels = x.get_shape().as_list()[-1] # 通道數
l2_norm = tf.nn.l2_normalize(x,dim=[3],epsilon=1e-12) # 隻對每個像素點在channels上做歸一化
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma Anchor設計和比對政策
在
VGG-16
和
ResNet101
上選擇尺寸分别為
8,16,32
和
64
像素步幅大小的特征層,與幾種不同尺度的
Anchor
相關聯進行預測。 每個特征圖都與一個特定特征層
Anchor
的尺度(尺度是相應層步幅的4倍)和三個比率(
0.5,1.0
和
2.0
)相關聯。比對政策使用
IOU
門檻值來确立,具體來說就是将每個
ground truth boxes
與具有最佳重疊分數的
anchor boxes
相比對,然後比對
anchor
重疊高于
0.5
的任何
ground truth boxes
。
Hard Negtive Mining
我在SSD中已經詳細講解過了,不再贅述了。總結一句話就是把正負樣本比例設定為
1:3
,當然負樣本不是随機選的,而是根據
box
的分類
loss
排序來選的,按照指定比例選擇
loss
最高的那些負樣本即可。可以看我的這篇推文詳細了解:目标檢測算法之SSD代碼解析(萬字長文超詳細)
損失函數
RefineDet的損失函數主要包含ARM和ODM兩部分。在ARM部分包含二分類損失損失
Lb
和回歸損失
Lr
;同理在ODM部分包含多分類損失
Lm
和回歸損失
Lr
。需要注意的是雖然RefineDet大緻上是RPN網絡和SSD的結合,但是在Faster R-CNN算法中RPN網絡和檢測網絡的訓練可以分開也可以end to end,而這裡的訓練方式就完全是end to end了,ARM和ODM兩個部分的損失函數都是一起向前傳遞的。損失函數公式如下:
其中
i
i
i表示一個
batch
中的第幾個
Anchor
,
l
i
∗
l_i^*
li∗表示
A
n
c
h
o
r
i
Anchor_i
Anchori對應的的ground truth bbox(GT)類别,
g
i
∗
g_i^*
gi∗表示
A
n
c
h
o
r
i
Anchor_i
Anchori的GT框位置,
p
i
p_i
pi表示置信度,
x
i
x_i
xi表示ARM中
Anchor
的坐标。
c
i
c_i
ci表示預測的類别,
t
i
t_i
ti表示ODM中預測的坐标資訊。
N
a
r
m
N_{arm}
Narm和
N
o
d
m
N_{odm}
Nodm分别表示ARM和ODM中的
positive anchor
數量。
L
b
L_b
Lb表示二分類損失,
L
m
L_m
Lm表示多分類損失,
L
r
L_r
Lr表示回歸損失。
[
l
i
∗
>
=
1
]
[l_i^*>=1]
[li∗>=1]表示如果negative confidence大于一個門檻值
θ
\theta
θ,那麼傳回1,否則傳回0。如果
N
a
r
m
=
N_{arm}=0
Narm=0設定
L
b
(
p
i
,
[
l
i
∗
>
=
1
]
)
=
L_b(p_i,[l_i^*>=1])=0
Lb(pi,[li∗>=1])=0和
L
r
(
x
i
,
g
i
∗
)
=
L_r(x_i,g_i^*)=0
Lr(xi,gi∗)=0;如果
N
o
d
m
=
N_{odm}=0
Nodm=0,那麼設定
L
m
(
x
i
,
l
i
∗
)
=
L_m(x_i,l_i^*)=0
Lm(xi,li∗)=0和
L
r
(
t
i
,
g
i
∗
)
=
L_r(t_i,g_i^*)=0
Lr(ti,gi∗)=0。
訓練超參數設定
用
xavier
方法随機初始化基于
VGG-16
的RefineDet的兩個添加的卷積層中(
conv6_1
和
conv6_2
)的參數。對于基于
ResNet-101
的RefineDet,初始化參數來自具有标準的零均值高斯分布,殘差子產品(res6)的初始化方差為0.01。其他的一些參數設定為:
- batch_size: 32
- momentum:0.9
- weight decay:0.0005
-
initial learing rate: 0.0001
其他詳細可以看代碼實作。
推理階段
首先,ARM過濾掉負置信度分數大于門檻值
θ
\theta
θ的
anchors
,
refine
剩餘
anchors
的位置和大小。然後, ODM輸出每個檢測圖像前400個高置信度的
anchors
。 最後,應用
NMS
,
jaccard
重疊率限定為
0.45
,并保留前
200
個高置信度anchors,産生最終的檢測結果。
實驗
Table1
是非常詳細的實驗結果對比,測試資料包括VOC2007和VOC2012資料集。以VGG-16為特征提取網絡的
RefineDet320
在達到實時的前提下能在VOC 2007測試集上達到80以上的mAP,這個效果基本上是目前看到過的單模型在相同輸入圖像情況下的最好成績了。表格中最後兩行在算法名稱後面多了
+
,表示采用
multi scale test
,是以效果會更好一點。
結論
論文提出了一種新的one-stage目标檢測器,由兩個互相連接配接子產品組成,即ARM子產品和ODM子產品。使用
multi-task loss
對整個網絡進行
end-to-end
訓練。在PASCAL VOC 2007,PASCAL VOC 2012和MS COCO資料集上進行了幾次實驗,結果表明RefineDet實作了目标最先進的檢測精度和高效率。
目标檢測未來
論文提出了兩個點,即計劃使用RefineDet來檢測一些其他特定類型的物體,例如行人,車輛和人臉,并在RefineDet中引入注意機制以進一步改善性能。
個人額外思考
TridenetNet+SSD?因為CVPR 2019的三叉戟網絡提到FPN結構的精度是不如圖像金字塔的,是以我們是否可以考慮将三叉戟網絡的三個檢測頭放到SSD做一個更高精度的網絡?
附錄
論文位址:https://arxiv.org/abs/1711.06897
源碼:https://github.com/sfzhang15/RefineDet