本文目錄
-
-
- 一、前言
- 二、資料可靠性
-
-
- 2.1、副本資料同步政策
- 2.2、ISR
- 2.3、ack應答機制
-
- 三、Exactly Once
-
-
- 3.1、幂等性機制
- 3.2、實作exactly once
-
- 四、故障處理
-
-
- 4.1、follower故障
- 4.2、leader故障
- 4.3、引入Lead Epoch
-
- 五、總結
-
一、前言
在上一篇文章裡我們探讨了kafka的工作流程、存儲機制、分區政策,理清楚了生産者生産的資料是怎麼存儲的以及怎麼根據offset去查詢資料這類問題:深入分析Kafka架構(一):工作流程、存儲機制、分區政策
那麼kafka是怎麼保證資料可靠性的呢?怎麼保證exactly once的呢?在分布式的環境下又是如何進行故障處理的呢?本篇文章我們就來分析這個問題。
二、資料可靠性
首先我們要知道kafka發送資料的機制:Kafka為了保證producer發送的資料,能可靠的發送到指定的topic,是以topic的每個partition收到producer發送的資料後,都需要向producer發送ack資訊(acknowledgement确認收到),如果producer收到ack,就會進行下一輪的發送,否則重新發送資料。
2.1、副本資料同步政策
我們知道kafka的partition是主從結構的,是以當一個topic對應多個partiton時,為了保證leader挂掉之後,能在follower中選舉出新的leader且不丢失資料,就需要確定follower與leader同步完成之後,leader再發送ack。
大緻圖示如下:
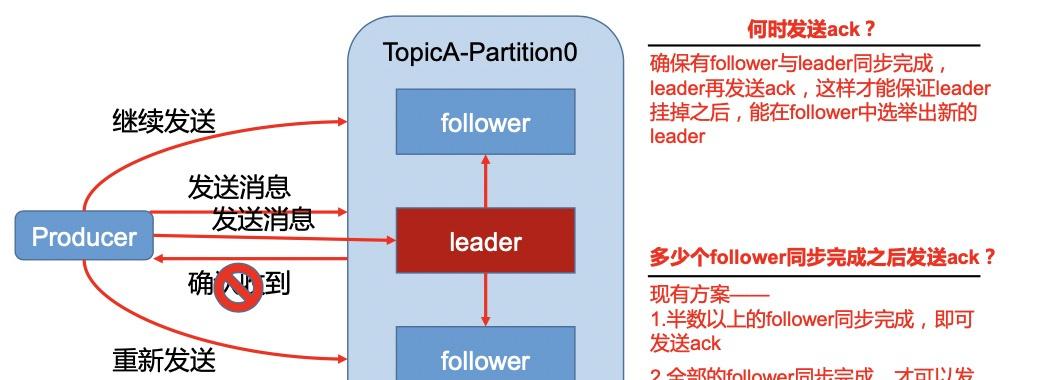
這時會産生一個問題也就是副本資料同步政策:多少個follower同步完成之後才發送ack呢?
有兩個方案對比如下:
- 半數以上完成同步,就發送ack(優點:延遲低;缺點:選舉新的leader時,容忍n台節點的故障,需要2n+1個副本)
- 全部完成同步,才發送ack(優點:選舉新的leader時,容忍n台節點的故障,需要n+1個副本;缺點:延遲高)
我們知道kafka采用零拷貝技術優化資料傳輸,是以網絡延遲對kafka的影響較小。但是由于kafka一般都是處理海量資料,在同樣為了容忍n台節點故障的前提下,第一種方案需要2n+1個副本,而第二種方案隻需要n+1個副本,而Kafka的每個分區都有大量的資料,第一種方案會造成大量資料的備援,是以kafka采用了第二種方案:全部完成同步,才發送ack。
2.2、ISR
kafka選用第二種發案來同步副本資料後,可能會出現一個問題:比如leader收到資料,然後開始向所有的follower同步資料,但是有那麼一個或多個follower因為挂掉了之類的原因出現了故障,不能和leader進行同步,那leader要一直等下去嗎?當然不可以,為了解決這個問題,引入了ISR的概念。
ISR是一個動态的in-sync replica set資料集,代表了和leader保持同步的follower集合。
當ISR中的follower完成資料的同步之後,leader就會給follower發送ack。如果follower長時間未向leader同步資料,則該follower将被踢出ISR,該時間門檻值由replica.lag.time.max.ms參數設定。Leader發生故障之後,就會從ISR中選舉新的leader。
相當于leader隻要和ISR裡的follower進行資料同步就可以了,出現故障的會被ISR移出去,恢複之後并經過處理還會加入進來。那移出去的follower要經過怎樣的處理才能重新加入ISR呢?可以先思考一下,後面故障處理部分會進行分析。
2.3、ack應答機制
由于資料的重要程度是不一樣的,有些可以少量允許丢失,希望快一點處理;有些不允許,希望穩妥一點處理,是以沒必要所有的資料處理的時候都等ISR中的follower全部接收成功。是以kafka處理資料時為了更加靈活,給使用者提供了三種可靠性級别,使用者可以通過調節acks參數來選擇合适的可靠性和延遲。
acks的參數分别可以配置為:0,1,-1。
它們的作用分别是:
- 配置為0:producer不等待broker的ack,這一操作提供了一個最低的延遲,broker一接收到還沒有寫入磁盤就已經傳回,當broker故障時有可能丢失資料;
- 配置為1:producer等待broker的ack,partition的leader寫入磁盤成功後傳回ack,但是如果在follower同步成功之前leader故障,那麼将會丢失資料;
- 配置為-1:producer等待broker的ack,partition的leader和follower全部寫入磁盤成功後才傳回ack。但是如果在follower同步完成後,broker發送ack之前,leader發生故障,此時會選舉新的leader,但是新的leader已經有了資料,但是由于沒有之前的ack,producer會再次發送資料,那麼就會造成資料重複。
三、Exactly Once
3.1、幂等性機制
Kafka在0.11版本之後,引入了幂等性機制(idempotent),指的是當發送同一條消息時,資料在 Server 端隻會被持久化一次,資料不丟不重,但是這裡的幂等性是有條件的:
- 隻能保證 Producer 在單個會話内不丟不重,如果 Producer 出現意外挂掉再重新開機是 無法保證的。因為幂等性情況下,是無法擷取之前的狀态資訊,是以是無法做到跨會話級别的不丢不重。
- 幂等性不能跨多個 Topic-Partition,隻能保證單個 Partition 内的幂等性,當涉及多個Topic-Partition 時,這中間的狀态并沒有同步。
3.2、實作exactly once
一般對于重要的資料,我們需要實作資料的精确一緻性,對于kafka也就是保證每條消息被發送且僅被發送一次,不能重複,這就是exactly once。我們通過上篇文章已經知道當acks = -1時,kafka可以實作at least once語義,這時候的資料會被至少發送一次。再配合前面介紹的幂等性機制保證資料不重複,那合在一起就可以實作producer到broker的exactly once語義。
它們的關系可以寫成一個公式:idempotent + at least once = exactly once
那怎麼配置kafka以實作exactly once呢?
很簡單,隻需将enable.idempotence屬性設定為true,kafka會自動将acks屬性設為-1。
四、故障處理
在分析故障處理之前,我們需要先知道幾個概念:
- LEO:全稱Log End Offset,代表每個副本的最後一條消息的offset
- HW:全稱High Watermark,代表一個分區中所有副本最小的offset,用來判定副本的備份進度,HW以外的消息不被消費者可見。leader持有的HW即為分區的HW,同時leader所在broker還儲存了所有follower副本的LEO。
如下圖,是一個topic下的某一個partition裡的副本的LEO和HW關系:

注意:隻有HW之前的資料才對Consumer可見,也就是隻有同一個分區下所有的副本都備份完成,才會讓Consumer消費。
它們之間的關系:leader的LEO >= follower的LEO >= leader儲存的follower的Leo >= leader的HW >= follower的HW
由于partition是實際的存儲資料的結構,是以kafka的故障主要分為兩類:follower故障和leader故障。
4.1、follower故障
這部分可以回答前面2.2節最後提到的問題:移出去的follower要經過怎樣的處理才能重新加入ISR呢?
通過前面我們已經知道follower發生故障後會被臨時踢出ISR,其實待該follower恢複後,follower會讀取本地磁盤記錄的上次的HW,并将log檔案高于HW的部分截取掉,從HW開始向leader進行同步。等該follower的LEO大于等于該分區的HW(leader的HW),即follower追上leader之後(追上不代表相等),就可以重新加入ISR了。
4.2、leader故障
leader發生故障之後,會從ISR中選出一個新的leader,之後,為保證多個副本之間的資料一緻性,其餘的follower會先将各自的log檔案高于HW的部分截掉,然後從新的leader同步資料。
注意:這隻能保證副本之間的資料一緻性,并不能保證資料不丢失或者不重複。
那怎麼解決故障恢複後,資料丢失和重複的問題呢?
kafka在0.11版本引入了Lead Epoch來解決HW進行資料恢複時可能存在的資料丢失和重複的問題。
4.3、引入Lead Epoch
leader epoch實際是一對值(epoch, offset),epoch表示leader版本号,offset為對應版本leader的LEO,它在Leader Broker上單獨開辟了一組緩存,來記錄(epoch, offset)這組鍵值對資料,這個鍵值對會被定期寫入一個檢查點檔案。Leader每發生一次變更epoch的值就會加1,offset就代表該epoch版本的Leader寫入的第一條日志的位移。當Leader首次寫底層日志時,會在緩存中增加一個條目,否則不做更新。這樣就解決了之前版本使用HW進行資料恢複時可能存在的資料丢失和重複的問題
這就有點像HashMap源碼裡面的modCount,用來記錄整體的更新變化。
五、總結
本篇文章我們分析了kafka是如何保證資料可靠性的以及它出現故障後是怎麼進行恢複的。結合上一篇文章,我們目前可以弄清楚kafka的工作流程、存儲機制、分區政策、如何保證資料可靠性、故障處理等核心原理,那資料又是如何消費的呢?下一篇文章将會分析kafka的消費方式,分區配置設定政策以及offset的維護等内容。