Redis預設每次執行請求都會建立和斷開一次連接配接池的操作,如果想執行多條指令的時候會在這件事情上消耗過多的時間,是以我們可以使用Redis的管道來一次性發送多條指令并傳回多個結果,節約發送指令和建立連接配接的時間提升效率。
介紹
在前面我們介紹過Redis的事務和lua腳本操作,事實上在各語言版本的Redis中都有管道(Pipeline)的功能,本篇以python版作為示例,當我們使用python給redis發送指令時會經曆下面的步驟:
- 用戶端發送請求,擷取socket,阻塞等待傳回;
- 服務端執行指令并将結果傳回給用戶端;
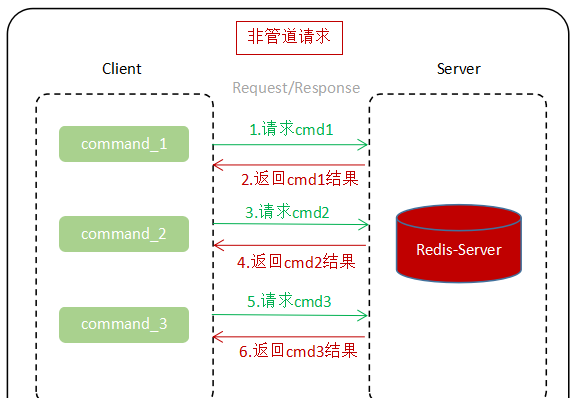
而當執行的指令較多時,這樣的一來一回的網絡傳輸所消耗的時間被稱為RTT(Round Trip Time),顯而易見,如果可以将這些指令作為一個請求一次性發送給服務端,并一次性将結果傳回用戶端,會節約很多網絡傳輸的消耗,可以大大提升響應時間。
官網:https://redis.io/topics/pipelining
逐個指令請求:
管道請求:

使用
管道的使用很簡單,python版代碼如下,在管道中可以選擇是否開啟事務,預設是開啟的,這裡的事務與Redis的事務一樣為弱事務性不是真正的事務:
import redis
#建立連接配接池擷取連接配接
pool = redis.ConnectionPool(host='wykd', port=6379,password='123456', decode_responses=True)
rp1 = redis.Redis(connection_pool=pool)
#建立管道,可以選擇開啟或關閉事務,這裡的事務與Redis事務一樣是弱事務型
pipe = rp1.pipeline(transaction=True)
#在管道中添加指令
pipe.set('new','123')
pipe.set('name', 'wyk2')
pipe.set('company', 'csdn2')
pipe.hincrby('hage','wyk',1)
#這個指令會報錯,因為hage為hash類型不能使用get指令,此時無論開啟關閉事務,管道中的其他指令也依然會正常執行
#pipe.get('hage')
#也可以用下面的文法将多個指令拼接到一起
# pipe.set('name', 'wyk').set('company', 'csdn').hset('hage', 'wyk',28).hincrby('hage','wyk',1)
#執行pipeline裡的腳本
pipe.execute() 複制
當管道中有指令報錯時,無論管道是否開啟事務都不會影響其他腳本的執行:
在管道中可以一次性擷取多個指令的傳回值,以清單形式:
pipe.get('name').get('company').hget('hage', 'wyk')
res = pipe.execute()
print(res) 複制
對比Lua腳本
Redis的Script會當成一個指令,具有原子性,在執行Script的時候不會被其他的指令插入,是以更适合于處理事務;而管道雖然也會将多個指令一次性傳輸到服務端,但在服務端執行的時候仍然是多個指令,如在執行CMD1的時候,外部另一個用戶端送出了CMD9,會先執行完CMD9再執行管道中的CMD2,是以事實上管道是不具有原子性的。
就場景上來說,正因為Lua腳本會被視為一個指令去執行,因為Redis是單線程執行指令的,是以我們不能在lua腳本裡寫過于複雜的邏輯,否則會造成阻塞,是以lua腳本适合于相對簡單的事務場景。
而管道因為不具有原子性,是以管道不适合處理事務,但管道可以減少多個指令執行時的網絡消耗,可以提高程式的響應速度,是以管道更适合于管道中的指令互相沒有關系,不需要有事務的原子性,且需要提高程式響應速度的場景。
尾巴
管道可以提升我們程式中的響應時間,同時我們不能完全依賴于它的"事務"機制,隻需要把管道當做"批處理"工具即可,在某些場合下,更需要結合管道和lua腳本一起使用。