MapReduce是一種程式設計模型,用于大規模資料集(大于1TB)的并行運算。概念"Map(映射)"和"Reduce(歸約)",是它們的主要思想,都是從函數式程式設計語言裡借來的,還有從矢量程式設計語言裡借來的特性。它極大地友善了程式設計人員在不會分布式并行程式設計的情況下,将自己的程式運作在分布式系統上。 目前的軟體實作是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。
一、MapReduce是個what?
首先說下Hadoop 的四大元件: HDFS:分布式存儲系統。 MapReduce:分布式計算系統。 YARN: hadoop 的資源排程系統。 Common: 以上三大元件的底層支撐元件,主要提供基礎工具包和 RPC 架構等。 Mapreduce 是一個分布式運算程式的程式設計架構,是使用者開發“基于 hadoop的資料分析 應用”的核心架構。 Mapreduce 核心功能是将使用者編寫的業務邏輯代碼和自帶預設元件整合成一個完整的分布式運算程式,并發運作在一個 hadoop 叢集上。
二、 MapReduce作業運作流程
你可以在 Job 對象上面調用 submit() 方法或者 waitForCompletion() 方法來運作一個 MapReduce 作業。這些方法影藏了背後大量的處理過程。下面我們來揭開 Hadoop 背後運作一個作業的步驟。整個過程如下圖所示(後面會對每一個步驟講解):

從整體層面上看,有五個獨立的實體: - 用戶端,送出 MapReduce 作業。 - YARN 資料總管(YARN resource manager),負責協調叢集上計算機資源的配置設定。 - YARN 節點管理器(YARN node manager),負責啟動和監視叢集中機器上的計算容器(container)。 - MapReduce的 application master,負責協調MapReduce 作業的任務。MRAppMaster 和 MapReduce 任務運作在容器中,該容器由資料總管進行排程(schedule)[此處了解為劃分、配置設定更為合适] 且由節點管理器進行管理。 - 分布式檔案系統(通常是 HDFS),用來在其他實體間共享作業檔案。
作業送出(Job Submission)
在 Job 對象上面調用 submit() 方法,在内部建立一個 JobSubmitter 執行個體,然後調用該執行個體的 submitJobInternal() 方法(圖1步驟1)。如果使用waitForCompletion() 方法來進行送出作業,該方法每隔 1 秒輪詢作業的進度,如果進度有所變化,将該進度報告給控制台(console)。當作業成功完成,作業計數器被顯示出來。否則,導緻作業失敗的錯誤被記錄到控制台。
JobSubmitter所實作的作業送出過程如下: - 向資料總管請求一個 application ID,該 ID 被用作 MapReduce 作業的 ID(步驟2)。 - 檢查作業指定的輸出(output)目錄。例如,如果該輸出目錄沒有被指定或者已經存在,作業不會被送出且一個錯誤被抛出給 MapReduce 程式 為作業計算輸入分片(input splits)。如果分片不能被計算(可能因為輸入路徑(input paths)不存在),該作業不會被送出且一個錯誤被抛出給 MapReduce 程式。 - 拷貝作業運作必備的資源,包括作業 JAR 檔案,配置檔案以及計算的輸入分片,到一個以作業 ID 命名的共享檔案系統目錄中(步驟3)。作業 JAR 檔案以一個高副本因子(a high replication factor)進行拷貝(由 mapreduce.client.submit.file.replication 屬性控制,預設值為 10),是以在作業任務運作時,在叢集中有很多的作業 JAR 副本供節點管理器來通路。 - 通過在資料總管上調用 submitApplication 來送出作業(步驟4)。
作業初始化(Job Initialization)
當資料總管接受到 submitApplication() 方法的調用,它把請求遞交給 YARN 排程器(scheduler)。排程器配置設定了一個容器(container),資料總管在該容器中啟動 application master 程序,該程序被節點管理器管理(步驟5a 和 5b)。
MapReduce 作業的 application master 是一個 Java 應用,它的主類是 MRAppMaster。它通過建立一定數量的簿記對象(bookkeeping object)跟蹤作業進度來初始化作業(步驟6),該簿記對象接受任務報告的進度和完成情況。接下來,application master 從共享檔案系統中擷取用戶端計算的輸入分片(步驟7)。然後它為每個分片建立一個 map 任務,同樣建立由 mapreduce.job.reduces 屬性控制的多個reduce 任務對象(或者在 Job 對象上通過 setNumReduceTasks() 方法設定)。任務ID在此時配置設定。
Applcation master 必須決定如何運作組成 MapReduce 作業的任務。如果作業比較小,application master 可能選擇在和它自身運作的 JVM 上運作這些任務。這種情況發生的前提是,application master 判斷配置設定和運作任務在一個新的容器上的開銷超過并行運作這些任務所帶來的回報,據此和順序地在同一個節點上運作這些任務進行比較。這樣的作業被稱為 uberized,或者作為一個 uber 任務運作。
一個小的作業具有哪些資格?預設的情況下,它擁有少于 10 個 mapper,隻有一個 reducer,且單個輸入的 size 小于 HDFS block 的。(注意,這些值可以通過 mapreduce.job.ubertask.maxmaps, mapreduce.job.ubertask.maxreduces, mapreduce.job.ubertask.maxbytes 進行設定)。Uber 任務必須顯示地将 mapreduce.job.ubertask.enable 設定為 true
最後,在任何任務運作之前, application master 調用 OutputCommiter 的 setupJob() 方法。系統預設是使用 FileOutputCommiter,它為作業建立最終的輸出目錄和任務輸出建立臨時工作空間(temporary working space)。
任務配置設定(Task Assignment)
如果作業沒有資格作為 uber 任務來運作,那麼 application master 為作業中的 map 任務和 reduce 任務向資料總管請求容器(步驟8)。首先要為 map 任務發送請求,該請求優先級高于 reduce 任務的請求,因為所有的 map 任務必須在 reduce 的排序階段(sort phase)能夠啟動之前完成。reduce 任務的請求至少有 5% 的 map 任務已經完成才會發出(可配置)。
reduce 任務可以運作在叢集中的任何地方,但是 map 任務的請求有資料本地限制(data locality constraint),排程器盡力遵守該限制(try to honor)。在最佳的情況下,任務的輸入是資料本地的(data local)-- 也就是任務運作在分片駐留的節點上。或者,任務可能是機架本地的(rack local),也就是和分片在同一個機架上,而不是同一個節點上。有一些任務既不是資料本地的也不是機架本地的,該任務從不同機架上面擷取資料而不是任務本身運作的節點上。對于特定的作業,你可以通過檢視作業計數器(job's counters)來确定任務的位置級别(locality level)。
請求也為任務指定記憶體需求和 CPU 數量。預設,每個 map 和 recude 任務被配置設定 1024 MB的記憶體和一個虛拟的核(virtual core)。這些值可以通過如下屬性(mapreduce.map.memory.mb, mapreduce.reduce.memory.mb, mapreduce.map.cpu.vcores, mapreduce.reduce.cpu.vcores)在每個作業基礎上進行配置(遵守 Memory settings in YARN and MapReduce 中描述的最小最大值)。
任務執行
一旦資源排程器在一個特定的節點上為一個任務配置設定一個容器所需的資源,application master 通過連接配接節點管理器來啟動這個容器(步驟9a 和9b)。任務通過一個主類為 YarnChild 的 Java 應用程式來執行。在它運作任務之前,它會将任務所需的資源本地化,包括作業配置,JAR 檔案以及一些在分布式緩存中的檔案(步驟10)。最後,它運作 map 或者 reduce 任務(步驟11)。
YarnChild 在一個指定的 JVM 中運作,是以任何使用者自定義的 map 和 reduce 函數的 bugs(或者甚至在 YarnChild)都不會影響到節點管理器 -- 比如造成節點管理的崩潰或者挂起。
每個任務能夠執行計劃(setup)和送出(commit)動作,它們運作在和任務本身相同的 JVM 當中,由作業的 OutputCommiter 來确定。對于基于檔案的作業,送出動作把任務的輸出從臨時位置移動到最終位置。送出協定確定當推測執行可用時,在複制的任務中隻有一個被送出,其他的都被取消掉。
進度和狀态的更新
MapReduce 作業是長時間運作的批處理作業(long-running batch jobs),運作時間從幾十秒到幾小時。由于可能運作時間很長,是以使用者得到該作業的處理進度回報是很重要的。
作業和任務都含有一個狀态,包括運作狀态、maps 和 reduces 的處理進度,作業計數器的值,以及一個狀态消息或描述(可能在使用者代碼中設定)。這些狀态會在作業的過程中改變。那麼它是如何與用戶端進行通信的?
當一個任務運作,它會保持進度的跟蹤(就是任務完成的比例)。對于 map 任務,就是被處理的輸入的比例。對于 reduce 任務,稍微複雜一點,但是系統任然能夠估算已處理的 reduce 輸入的比例。通過把整個過程分為三個部分,對應于 shuffle 的三個階段。例如,如果一個任務運作 reducer 完成了一半的輸入,該任務的進度就是 5/6,因為它已經完成了 copy 和 sort 階段(1/3 each)以及 reduce 階段完成了一半(1/6)。
MapReduce 的進度組成 進度不總是可測的,但是它告訴 Hadoop 一個任務在做的一些事情。例如,任務的寫輸出記錄是有進度的,即使不能用總進度的百分比(因為它自己也可能不知道到底有多少輸出要寫,也可能不知道需要寫的總量)來表示進度報告非常重要,Hadoop 不會使一個報告進度的任務失敗(not fail a task that's making progress)。如下的操作構成了進度: - 讀取輸入記錄(在 mapper 或者 reducer 中)。 - 寫輸出記錄(在 mapper 或者 reducer 中)。 - 設定狀态描述(由 Reporter 的或 TaskAttempContext 的 setStatus() 方法設定)。 - 計數器的增長(使用 Reporter 的 incrCounter() 方法 或者 Counter 的 increment() 方法)。 - 調用 Reporter 的或者 TaskAttemptContext 的 progress() 方法。
任務有一些計數器,它們在任務運作時記錄各種事件,這些計數器要麼是架構内置的,例如:已寫入的map輸出記錄數,要麼是使用者自定義的。
當 map 或 reduce 任務運作時,子程序使用 umbilical 接口和父 application master 進行通信。任務每隔三秒鐘通過 umbilical 接口報告其進度和狀态(包括計數器)給 application master,application master會形成一個作業的聚合視圖。
在作業執行的過程中,用戶端每秒通過輪詢 application master 擷取最新的狀态(間隔通過 mapreduce.client.progressmonitor.polinterval 設定)。用戶端也可使用 Job 的 getStatus() 方法擷取一個包含作業所有狀态資訊的 JobStatus 執行個體,過程如下:
作業完成(Job Completion)
當 application master 接受到最後一個任務完成的通知,它改變該作業的狀态為 “successful”。當 Job 對象輪詢狀态,它知道作業已經成功完成,是以它列印一條消息告訴使用者以及從 waitForCompletion() 方法傳回。此時,作業的統計資訊和計數器被列印到控制台。
Application master 也可以發送一條 HTTP 作業通知,如果配置了的話。當用戶端想要接受回調時,可以通過 mapreduce.job.end-notification.url 屬性進行配置。
最後,當作業完成,application master 和作業容器清理他們的工作狀态(是以中間輸入會被删除),然後 OutputCommiter 的 commitJob() 方法被調用。作業的資訊被作業曆史伺服器存檔,以便日後使用者查詢。
三、MapReduce計算流程
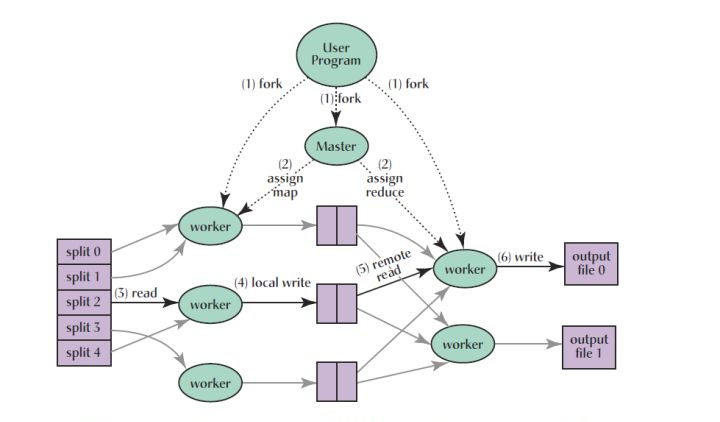
先把圖放出來,後面的講解都能在這個圖上有展現。
在進行map計算之前,mapreduce會根據輸入檔案計算輸入分片(input split),每個輸入分片(input split)針對一個map任務,輸入分片(input split)存儲的并非資料本身,而是一個分片長度和一個記錄資料的位置的數組,輸入分片(input split)往往和hdfs的block(塊)關系很密切,假如我們設定hdfs的塊的大小是64mb,如果我們輸入有三個檔案,大小分别是3mb、65mb和127mb,那麼mapreduce會把3mb檔案分為一個輸入分片(input split),65mb則是兩個輸入分片(input split)而127mb也是兩個輸入分片(input split),換句話說我們如果在map計算前做輸入分片調整,例如合并小檔案,那麼就會有5個map任務将執行,而且每個map執行的資料大小不均,這個也是mapreduce優化計算的一個關鍵點。[分塊分片的參考:Hadoop分塊與分片介紹及分片和分塊大小相同的原因] Hadoop分塊和分片
預設分片大小與分塊大小是相同的原因 hadoop在存儲有輸入資料(HDFS中的資料)的節點上運作map任務,可以獲得高性能,這就是所謂的資料本地化。是以最佳分片的大小應該與HDFS上的塊大小一樣,因為如果分片跨越2個資料塊,對于任何一個HDFS節點(Hadoop系統保證一個塊存儲在一個datanode上,基本不可能同時存儲這2個資料塊),分片中的另外一塊資料就需要通過網絡傳輸到map任務節點,與使用本地資料運作map任務相比,效率則更低!小結:分塊優化,減少網絡傳輸資料,使用本地資料運作map任務。 2. map階段:
就是程式員編寫好的map函數了,是以map函數效率相對好控制,而且一般map操作都是本地化操作也就是在資料存儲節點上進行;
3. combiner階段:combiner階段是程式員可以選擇的,combiner其實也是一種reduce操作,是以我們看見WordCount類裡是用reduce進行加載的。
Combiner是一個本地化的reduce操作,它是map運算的後續操作,主要是在map計算出中間檔案前做一個簡單的合并重複key值的操作,例如我們對檔案裡的單詞頻率做統計,map計算時候如果碰到一個hadoop的單詞就會記錄為1,但是這篇文章裡hadoop可能會出現n多次,那麼map輸出檔案備援就會很多,是以在reduce計算前對相同的key做一個合并操作,那麼檔案會變小,這樣就提高了寬帶的傳輸效率,
畢竟hadoop計算力寬帶資源往往是計算的瓶頸也是最為寶貴的資源,但是combiner操作是有風險的,使用它的原則是combiner的輸入不會影響到reduce計算的最終輸入,例如:如果計算隻是求總數,最大值,最小值可以使用combiner,但是做平均值計算使用combiner的話,最終的reduce計算結果就會出錯。
小結:combine時一個本地化的reduce操作,對相同的key做一個合并操作,提高帶寬的使用率 4. shuffle階段: 将map的輸出作為reduce的輸入的過程就是shuffle了,這個是mapreduce優化的重點地方。這裡我不講怎麼優化shuffle階段,講講shuffle階段的原理,因為大部分的書籍裡都沒講清楚shuffle階段。Shuffle一開始就是map階段做輸出操作,一般mapreduce計算的都是海量資料,map輸出時候不可能把所有檔案都放到記憶體操作,是以map寫入磁盤的過程十分的複雜,更何況map輸出時候要對結果進行排序,記憶體開銷是很大的,map在做輸出時候會在記憶體裡開啟一個
環形記憶體緩沖區,這個緩沖區專門用來輸出的,預設大小是100mb,并且在配置檔案裡為這個緩沖區設定了一個閥值,預設是0.80(這個大小和閥值都是可以在配置檔案裡進行配置的),同時map還會為輸出操作啟動一個守護線程,如果緩沖區的記憶體達到了閥值的80%時候,這個守護線程就會把内容寫到磁盤上,這個過程叫spill,另外的20%記憶體可以繼續寫入要寫進磁盤的資料,寫入磁盤和寫入記憶體操作是互不幹擾的,如果緩存區被撐滿了,那麼map就會阻塞寫入記憶體的操作,讓寫入磁盤操作完成後再繼續執行寫入記憶體操作,前面我講到寫入磁盤前會有個排序操作,這個是在寫入磁盤操作時候進行,不是在寫入記憶體時候進行的,如果我們定義了combiner函數,那麼排序前還會執行combiner操作。每次spill操作也就是寫入磁盤操作時候就會寫一個溢出檔案,也就是說在做map輸出有幾次spill就會産生多少個溢出檔案,等map輸出全部做完後,map會合并這些輸出檔案。這個過程裡還會有一個Partitioner操作,對于這個操作很多人都很迷糊,其實Partitioner操作和map階段的輸入分片(Input split)很像,一個Partitioner對應一個reduce作業,如果我們mapreduce操作隻有一個reduce操作,那麼Partitioner就隻有一個,如果我們有多個reduce操作,那麼Partitioner對應的就會有多個,Partitioner是以就是reduce的輸入分片,這個程式員可以程式設計控制,主要是根據實際key和value的值,根據實際業務類型或者為了更好的reduce負載均衡要求進行,這是提高reduce效率的一個關鍵所在。到了reduce階段就是合并map輸出檔案了,Partitioner會找到對應的map輸出檔案,然後進行複制操作,複制操作時reduce會開啟幾個複制線程,這些線程預設個數是5個,程式員也可以在配置檔案更改複制線程的個數,這個複制過程和map寫入磁盤過程類似,也有閥值和記憶體大小,閥值一樣可以在配置檔案裡配置,而記憶體大小是直接使用reduce的tasktracker的記憶體大小,複制時候reduce還會進行排序操作和合并檔案操作,這些操作完了就會進行reduce計算了。
小結:- shuffle是mapreduce優化的重點地方;
- 環形記憶體緩沖區 :是以map寫入磁盤的過程十分的複雜,更何況map輸出時候要對結果進行排序,記憶體開銷是很大的,是以開啟環形記憶體緩沖區專門用于輸出;預設是100MB,門檻值是0.8;
- spill(溢寫):緩沖區>80%,寫入磁盤;溢寫前先排序,後合并,寫入磁盤;
- Partition:Partitioner操作和map階段的輸入分片(Input split)很像,Partitioner會找到對應的map輸出檔案,然後進行複制操作,作為reduce的輸入;
- reduce階段:和map函數一樣也是程式員編寫的,最終結果是存儲在hdfs上的。
Split是怎麼劃分的? 參考FileInputFormat類中split切分算法和host選擇算法介紹
五、 關于MapReduce運作過程的一些疑問?
1. map階段的溢寫疑問?
MapReduce 的Shuffle階段的溢寫階段,分兩類:1、環形緩沖區的資料到達80%時,就會溢寫到本地磁盤,當再次達到80%時,就會再次溢寫到磁盤, 直到最後一次,不管環形緩沖區還有多少資料,都會溢寫到磁盤。然後會對這多次溢寫到磁盤的多個小檔案進行合并,減少Reduce階段的網絡傳輸。 2.就是沒有達到80%map階段就結束了,這時直接把環形緩沖區的資料寫到磁盤上,供下一步合并使用。
2.MapReduce中如何處理跨行的Block和InputSplit?
FileInputFormat對檔案的切分是嚴格按照偏移量來的,是以一行記錄比較長的話,可能被切分到不同的InputSplit。但這并不會對Map造成影響,盡管一行記錄可能被拆分到不同的InputSplit,但是與FileInputFormat關聯的RecordReader被設計的足夠健壯,當一行記錄跨InputSplit時,其能夠到讀取不同的InputSplit,直到把這一行記錄讀取完成。我們拿最常見的TextInputFormat舉例分析如何處理跨行InputSplit的,TextInputFormat關聯的是LineRecordReader。
其讀取檔案是通過LineReader(in就是一個LineReader執行個體)的readLine方法完成的。關鍵的邏輯就在這個readLine方法裡,這個方法主要的邏輯歸納起來是3點: A 總是從buffer裡讀取資料,如果buffer裡的資料讀完了,先加載下一批資料到buffer。 B 在buffer中查找"行尾",将開始位置至行尾處的資料拷貝給str(也就是最後的Value)。若為遇到"行尾",繼續加載新的資料到buffer進行查找。 C 關鍵點在于:給到buffer的資料是直接從檔案中讀取的,完全不會考慮是否超過了split的界限,而是一直讀取到目前行結束為止。 更通俗的解釋是:如果map按照split讀取資料時發現最後一行資料沒有遇到n換行符,則會去下一個split中讀取資料直到遇到n為止,第二個map讀取資料時會檢視上個map的split資料的最後一行是不是n,若果不是說明本split的第一行資料已經被讀取,自己從第二行開始讀取