失敗是最佳的營養,腐爛的樹葉是樹成長最佳的肥料一樣,我們不僅要反思自己的過錯,更要分享自己的過錯,敢于分享自己過錯的人才是了不起的人。
Flume是一個分布式、可靠、和高可用的海量日志采集、聚合和傳輸的系統。支援在日志系統中定制各類資料發送方,用于收集資料;同時,Flume提供對資料進行簡單處理,并寫到各種資料接受方(比如文本、HDFS、Hbase等)的能力。Flume的資料流由事件(Event)貫穿始終。事件是Flume的基本資料機關,它攜帶日志資料(位元組數組形式)并且攜帶有頭資訊,這些Event由Agent外部的Source生成,當Source捕獲事件後會進行特定的格式化,然後Source會把事件推入(單個或多個)Channel中。你可以把Channel看作是一個緩沖區,它将儲存事件直到Sink處理完該事件。Sink負責持久化日志或者把事件推向另一個Source。
Flume的一些核心概念:
1. Agent:使用JVM 運作Flume。每台機器運作一個agent,但是可以在一個agent中包含多個sources和sinks。
2. Client:生産資料,運作在一個獨立的線程。
3. Source:從Client收集資料,傳遞給Channel。
4. Sink :從Channel收集資料,運作在一個獨立線程。
5. Channel :連接配接 sources 和 sinks ,這個有點像一個隊列。
6. Events:可以是日志記錄、 avro 對象等。
Flume以agent為最小的獨立運作機關。一個agent就是一個JVM。單agent由Source、Sink和Channel三大元件構成,如下圖:
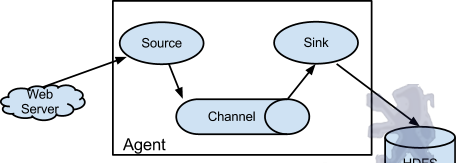
值得注意的是,Flume提供了大量内置的Source、Channel和Sink類型。不同類型的Source,Channel和Sink可以自由組合。組合方式基于使用者設定的配置檔案,非常靈活。比如:Channel可以把事件暫存在記憶體裡,也可以持久化到本地硬碟上。Sink可以把日志寫入HDFS, HBase,甚至是另外一個Source等等。Flume支援使用者建立多級流,也就是說,多個agent可以協同工作,并且支援Fan-in、Fan-out、Contextual Routing、Backup Routes,這也正是NB之處。如下圖所示:

日志收集實際應用案例:
Flume:日志收集
HDFS/HBase:日志存儲
Hive:日志分析