身處大資料時代,對模型和風控工作者來說無異于福音。但與此同時,資料呈現長尾分布,不均衡分布導緻訓練困難,效果不佳。具體到風控場景中,負樣本的占比要遠遠小于正樣本的占比。考慮一個簡單的例子,假設有10萬個樣本,其中逾期客戶500個,壞樣本占比0.5%。如果我們直接将資料輸入模型進行訓練,将導緻即便全部判斷為正,準确率也能達到99.5%,在梯度下降過程中,正樣本壓倒性的影響,模型難以收斂到最優點。
本文将對這一問題進行探讨,并試圖跳出智能風控領域,從更宏觀的角度,引入、借鑒和探讨非均衡樣本的處理政策。
常見的非均衡樣本處理政策有:
1.重新采樣:
(1)過采樣:将樣本較少的一類sample補齊
(2)欠采樣:将樣本較多的一類sample壓縮
(3)組合采樣:或者上下兩個方向同時采樣。
使用重新采樣的方法,也許會引入大量的重複樣本,這将降低訓練速度,并導緻模型有過拟合的風險或者丢棄有價值的資料。
2.使用代價敏感權重:
我們對更小的樣本配置設定更高的權重。在分類函數,比如邏輯回歸中,我們可以通過class-weight來調整正負樣本的權重。我們讓小類的權重更大,以此來抵消不均衡的影響。考慮将樣本配置設定不同的權重,這是符合直覺感受的。一方面我們可以在做訓練的時候,将小類型樣本給與更高權重,強制幹預梯度下降步長,另一方面工作中,不同的樣本帶來的代價也是不一樣的,比如智能風控中,壞樣本帶來的損失是比好樣本更高。
以上兩種方法是傳統的機器學習中常用的辦法,但是在實際工作不難中發現,重新采樣和重新賦予權重這兩種方法是啟發式的,調參帶來的結果影響較大,難以達到最佳。
面對這樣的困難,該将如何解決呢?
為解決這樣的問題,微衆信科認為在工作中我們可以從兩個方面進行有效的嘗試:第一,擴充資料。第二,利用新的模型。
第一,擴充資料:
直覺上,資料越多越好,但是我們不能簡單的複制資料,而是生成一些新資料加入到模型中。具體方法如下:
3.生成對抗網絡(GAN):
在機器學習的理論中,我們有生成模型和判别模型之分。生成模型是指我們對聯合機率模組化,除了分類之外我們還需要刻畫資料是如何産生的。而判别模型是對條件機率進行模組化,我們不關心如何刻畫樣本,我們隻需要滿足正确的分類比錯誤的分類機率大即可。生成對抗網絡将兩者聯合了起來。模型分為生成部分和判别部分。
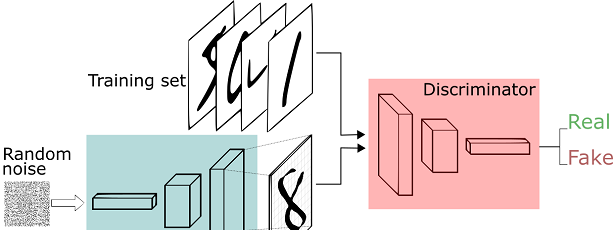
Image credit: Thalles Silva
簡單來說,我們準備好兩部分資料:真實資料和随機噪音資料。随機噪音資料通過生成器,變成假資料。其後訓練一個判别模型,它能很好的判斷輸入的資料是真實的還是假的(生成的)。生成器從随機噪音開始不停的生成資料,判别器告訴生成器不對,并告訴生成器哪裡不對,生成器獲得新的指導後再不停的生成資料,這樣不斷循環,導緻生成的資料越來越靠近真實。
4.SMOTE采樣算法:
該算法來源于論文《SMOTE: Synthetic Minority Over-sampling Technique》,該論文提出了一種過采樣算法SMOTE。概括來說,本算法基于“插值”來為少數類合成新的樣本。 并将新樣本添加到資料集中進行訓練。
5.Label propagation标簽傳播算法:
标簽傳播算法是一種基于圖的半監督學習方式。LP的核心思想是:相似的樣本具有相同的标簽。是以LP算法首先構造相似矩陣,并利用新入樣本和已經标簽樣本的相似度來給沒有标簽的樣本打标簽。
第二:新的模型
現在如果将視角放在更宏觀的角度,我們會發現導緻收斂困難的方法是我們用到(y_true-y_pred)相關的損失函數去做梯度下降。那麼我們能不能改變這個損失函數,讓收斂更容易?2018年Facebook Kaiming He在《Focal Loss for Dense Object Detection》中提出了focal_loss成為這一方面的代表性模型。
FL(pt) = −αt(1 − pt)γ log(pt).
Focal loss的核心思想是:比如正樣本遠比負樣本多的話,模型肯定會傾向于數目多的正類(可以想象全部樣本都判為正類),這時候,正類的 y,γ 或 σ(Kx) 都很小,而負類的 (1−ŷ )γ 或 σ(−Kx) 就很大,這時候模型就會開始集中精力關注負樣本。
從focal loss開始後繼者們也開始了更多的改進,衍生除了各種進化的focal_loss,其中有代表性的是康納爾大學和谷歌聯合提出的CB Focal。 此外值得一提的是,在CVPR 2020上,曠視提出了BBN模型,比focal loss top1準确率提升了30%左右。并獲得了長尾資料集 iNaturalist Challenge 賽道的世界冠軍。

Image credit: 《BBN:Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition》
BBN 模型包含 3 個主要元件:1)正常學習分支,2)再平衡分支,3)累積學習政策。正常學習分支和再平衡分支分别用于表征學習和分類器學習。這兩個分支使用了同樣的殘差網絡結構,除最後一個殘差子產品,兩個分支的網絡參數是共享的。
無論是focal loss 或者後續的BBN,深度學習的優秀做法也同樣可以應用到智能風控中。
結語:可以看出無論是風控,抑或自然語言處理,計算機視覺等等各領域,資料的不均衡分布始終都是我們要面對的問題,智能風控也可以從其他領域借鑒好的做法來提升我們的模型。随着”新基建”的積極推進和5G的蓄勢待發,資料将伴随着時代的浪潮不可避免地激增,如何科學地處理資料,快速地計算,精準地處理,穩健地部署将是值得從業者們一直關注的問題,我們也将作為先行者和踐行者,去實踐,去創造,去分享。
作者 | 何志堅(微衆信科資深算法工程師)