在 上篇關于 TiFlash 的文章 釋出後,我們收到了很多夥伴們的回報,大家有各種各樣的疑問,包括 TiFlash 是不是 T + 1 列存資料庫?為啥實時寫入也很快?讀壓力大怎麼辦?節點挂了怎麼辦?業務怎麼接入?……今天我們就來詳細回複一下大家的問題,希望能對大家了解和實踐 TiFlash 有所幫助。
并非「另一個 T + 1 列存資料庫」
首先,它并不是獨立的列存資料庫:TiFlash 是配合 TiDB 體系的列存引擎,它和 TiDB 無縫結合,線上 DDL、無縫擴容、自動容錯等等友善運維的特點也在 TiFlash 中得到繼承。
其次,TiFlash 可以實時與行存保持同步。
T + 1 問題
「為何要列和 MySQL 的對比呢?這樣是否太無聊?」
由于 TiFlash 具備實時高頻實時更新能力,是以我們在 上一篇 介紹中單機對單機比較了交易型資料庫例如 MySQL,因為這些特點一般是行存引擎具備的優勢。TiFlash 與大多數列存不同的是,它支援實時更新,并且與行存資料保持同步。
「為何說其他列存資料庫無法更新?我看到 XX 支援 Update 呀?」
多數列存引擎并不是絕對不支援更新,而是不支援主鍵或唯一性限制,是以無法像交易型資料庫那樣快速定位單條記錄并進行一緻性更新,這也是你無法向它們實時同步交易庫資料的原因。針對這樣的設計,常用的更新方式是使用 ETL 去重和融合新老資料,然後批量導入列存,這就使得資料無法實時分析而需等待數小時甚至一天。
TiFlash 是為實時場景設計,是以我們必須支援實時更新。在這個前提下,通過良好的設計和工程實作,也借助 ClickHouse 極速的向量化引擎,TiFlash 仍然擁有不亞于甚至超出其他列存引擎的優異性能。大家可以參考 上一篇文章中的 Benchmark 。
為什麼實時寫入也很快
「TiFlash 是列存,大家都說列存的實時寫入很慢,TiFlash 呢?」
經過業界驗證的實時更新列存方案是 Delta Main 設計。簡單說,就是将需要更新資料與整理好的不可變列存塊分開存放,讀時歸并,定期 Compact,而 TiFlash 也采取了類似設計思路。TiFlash 并非是拍腦袋發明了一種可更新列存結構,而是參考了其他成熟系統設計,如 Apache Kudu,CWI 的 Positional Delta Tree 等的設計思路,TiFlash 的設計也兼具了 B+ 樹和 LSM 的優勢,在讀寫兩端都有優異的性能(但犧牲了對 TiFlash 場景無用的點查性能)。由于無需考慮點查,是以 TiFlash 可以以進行惰性資料整理加速寫入;由于引入了讀時排序索引回寫,是以哪怕 Compact 不那麼頻繁仍可以保持掃描高效,進一步減小寫放大加速寫入。
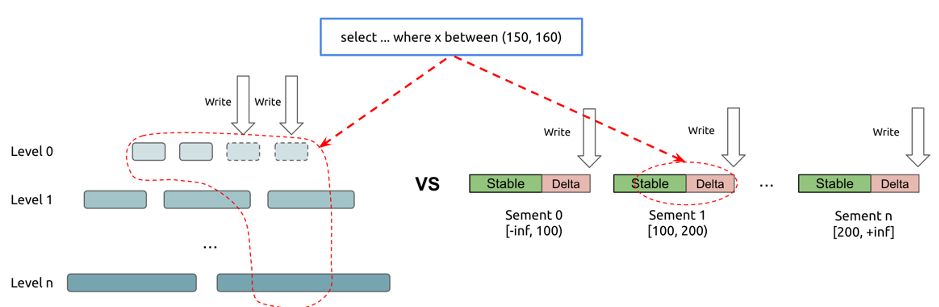
「TiFlash 進行 OLAP 讀取的時候會影響 OLTP 性能嗎?」
上篇文章 中已經展示過 TiFlash 的讀取性能:

注:為了不影響比例,上圖忽略了 MySQL 和 Oracle 資料。
下面帶大家看看更新寫入速度,這裡做了個簡單的寫入測試:
- 測試配置 3 節點 6 TiKV(3 副本)+ 2 節點 TiFlash(2 副本)。
- sysbench write-only 測試。
- 以 60954.39 的 QPS 進行混合寫入更新和删除。
- 同時 TiFlash 不斷進行全表聚合計算。
測試結果是:
- sysbench 運作 QPS 非常平穩,不會因為 AP 查詢而抖動。從上圖可以看到,黃色線段代表 AP 查詢(開啟和關閉),開啟和關閉并不會對查詢産生抖動,哪怕 999 分位。
- TiFlash 可以很好比對 TiKV 的實時寫入(包含增删改而非僅僅插入)同時提供查詢。
- 另外,我們也觀測到,以大壓力寫入同時進行查詢,通過對 5000 個 TiFlash Region 副本采樣:讀取時,進行一緻性校對 + 追趕 + 寫入的時間平均 27.31 毫秒,95分位在 73 毫秒,99分位是 609 毫秒,對于分析類查詢,這個延遲穩定性是可以接受的。
實際上,在都隻寫 1 副本的情況下,TiFlash 的寫入性能大緻可以追上 2-3 個同規格 TiKV 節點,這確定了 TiFlash 在更少的資源配比下,也可以比對 TiKV 的寫入壓力。
為何如此?
由于 TiFlash 引擎針對 AP 場景無需點查的不同設計,它相對 LSM 引擎減小了寫放大比率:TiFlash 的寫放大大約在 3-7 倍之間。且在寫入約繁忙情況下,由于攢批效果反而越接近更小的三倍放大比率。而 LSM 結構下,RocksDB 的寫放大在 10 倍左右。這個對比優勢大大提高了 TiFlash 磁盤實際能承載的業務吞吐量。
友善靈活的運維
靈活擴容
「如果讀壓力也很大,你光寫得夠快有啥用啊?」
雖然我們展示了 TiFlash 的寫入性能,其實哪怕它的寫入速度不如 TiKV,我們仍然可以單獨對 TiFlash 進行擴容。不管 TiFlash 的寫入性能多優秀,仍然有可能因為使用者的查詢讀取壓力過大而造成寫入速度下降,這時候是否就會産生嚴重的複制延遲呢?
會。但是 TiFlash 卻可以依靠 TiDB 的體系單獨擴容,如果業務壓力過大,多上線幾台 TiFlash 節點就可以自然分擔資料和壓力,使用者完全無需操心擴容過程,這些都是透明且自動的。相對于同節點的行列混合設計,這樣的架構無疑更靈活,且仍然保持了一緻性。
自動恢複
「節點挂了怎麼辦?」
當 TiFlash 節點損壞下線,TiDB 體系可以保證 TiFlash 的資料自動從行存恢複副本,而補副本的過程也會考慮不對 TiKV 産生沖擊。在 TiFlash 多副本的情況下,這個過程對使用者也是完全透明無感覺的:你隻需要将補充的伺服器啟動上線就行。
無阻塞 DDL
「TiFlash 支援 DDL 嗎?」
TiFlash 繼承了 TiDB 體系的線上 DDL,尤其是它支援了更改列類型。與傳統列存系統需要完全重寫列格式不同,TiFlash 支援混合表結構,每個列資料塊可以有獨立的表結構,這使得 TiFlash 更改列類型是完全實時且無負擔的:沒有資料需要被立刻重寫。這種設計,使得 TiFlash 可以很容易被用于資料內建場合,任何上遊資料源的表結構變更可以無阻塞地被同步。
快速的業務接入
上述所有這些特性,使得 TiFlash 體系可以非常便捷地承載實時分析業務。考慮一下如果你有一個新業務上線,你需要将線上業務接入分析平台例如 Hadoop,你也許需要做如下事情:
- 修改業務邏輯,在表結構中添加變更時間标記以便增量抽取。
- 編寫定時任務,從源資料庫中抽取增量資料。
- 将資料寫入 Staging 表,通過和 Hive 目标表進行 JOIN 并回寫以處理增量更新。
- 很可能你還需要編寫資料校驗代碼定期檢查一緻性。
- 那麼也意味着你需要編寫不一緻時的修複代碼。
這個過程可能需要耗費數天,甚至更久,而你還需要維護整個傳輸鍊路。
在 TiDB + TiFlash 體系下,你隻需要一條指令:
ALTER TABLE your_table SET TIFLASH REPLICA 1; 複制
你就可以自動獲得一份實時保持一緻的列存資料鏡像,進行實時分析。
5秒(取決于你的手速) vs 數天
即便你已經有完整的 Hadoop 數倉建設,TiFlash 配合 TiSpark,也可以輕松銜接兩個平台的同時,為離線數倉提供實時分析能力。