原文連結:批流一體資料內建工具ChunJun同步Hive事務表原理詳解及實戰分享
課件擷取:關注公衆号__ “數棧研習社”,背景私信 “ChengYing”__ 獲得直播課件
視訊回放:點選這裡
ChengYing 開源項目位址:github 丨 gitee 喜歡我們的項目給我們點個__ STAR!STAR!!STAR!!!(重要的事情說三遍)__
技術交流釘釘 qun:30537511
本期我們帶大家回顧一下無倦同學的直播分享《Chunjun同步Hive事務表詳解》
一、Hive事務表的結構及原理
Hive是基于Hadoop的一個資料倉庫工具,用來進行資料提取、轉化、加載,這是一種可以存儲、查詢和分析存儲在Hadoop中的大規模資料的機制。Hive資料倉庫工具能将結構化的資料檔案映射為一張資料庫表,并提供SQL查詢功能,能将SQL語句轉變成MapReduce任務來執行。
在分享Hive事務表的具體内容前,我們先來了解下HIve 事務表在 HDFS 存儲上的一些限制。
Hive雖然支援了具有ACID語義的事務,但是沒有像在MySQL中使用那樣友善,有很多局限性,具體限制如下:
- 尚不支援BEGIN,COMMIT和ROLLBACK,所有語言操作都是自動送出的
- 僅支援ORC檔案格式(STORED AS ORC)
- 預設情況下事務配置為關閉,需要配置參數開啟使用
- 表必須是分桶表(Bucketed)才可以使用事務功能
- 表必須内部表,外部表無法建立事務表
- 表參數transactional必須為true
- 外部表不能成為ACID表,不允許從非ACID會話讀取/寫入ACID表
以下矩陣包括可以使用Hive建立的表的類型、是否支援ACID屬性、所需的存儲格式以及關鍵的SQL操作。
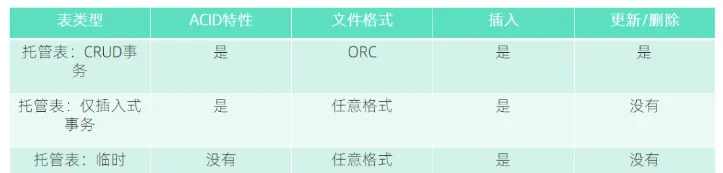
了解完Hive事務表的限制,現在我們具體了解下Hive事務表的内容。
1、事務表檔案名字詳解
- 基礎目錄:
$partition/base_$wid/$bucket
- 增量目錄:
$partition/delta_$wid_$wid_$stid/$bucket
- 參數目錄:
$partition/delete_delta_$wid_$wid_$stid/$bucket

2、事務表檔案内容詳解
$ orc-tools data bucket_00000
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":0,"currentTransaction":1,"row":{"id":1,"name":"Jerry","age":18}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":1,"row":{"id":2,"name":"Tom","age":19}}
{"operation":0,"originalTransaction":1,"bucket":536870912,"rowId":2,"currentTransaction":1,"row":{"id":3,"name":"Kate","age":20}}
- operation 0 表示插入、1 表示更新,2 表示删除。由于使用了 split-update,UPDATE 是不會出現的。
- originalTransaction是該條記錄的原始寫事務 ID:
a、對于 INSERT 操作,該值和 currentTransaction 是一緻的;
b、對于 DELETE,則是該條記錄第一次插入時的寫事務 ID。
- bucket 是一個 32 位整型,由 BucketCodec 編碼,各個二進制位的含義為:
a、1-3 位:編碼版本,目前是 001;
b、4 位:保留;
c、5-16 位:分桶 ID,由 0 開始。分桶 ID 是由 CLUSTERED BY 子句所指定的字段、以及分桶的數量決定的。該值和 bucket_N 中的 N 一緻;
d、17-20 位:保留;
e、21-32 位:語句 ID;
舉例來說,整型 536936448 的二進制格式為 00100000000000010000000000000000,即它是按版本 1 的格式編碼的,分桶 ID 為 1。
- rowId 是一個自增的唯一 ID,在寫事務和分桶的組合中唯一;
- currentTransaction 目前的寫事務 ID;
- row 具體資料。對于 DELETE 語句,則為 null。
3、更新 Hive 事務表資料
UPDATE employee SET age = 21 WHERE id = 2;
這條語句會先查詢出所有符合條件的記錄,擷取它們的 row_id 資訊,然後分别建立 delete 和 delta 目錄:
/user/hive/warehouse/employee/delta_0000001_0000001_0000/bucket_00000
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0000/bucket_00000 (update)
/user/hive/warehouse/employee/delta_0000002_0000002_0000/bucket_00000 (update)
delete_delta_0000002_0000002_0000/bucket_00000
包含了删除的記錄:
{"operation":2,"originalTransaction":1,"bucket":536870912,"rowId":1,"currentTransaction":2,"row":null}
delta_0000002_0000002_0000/bucket_00000
包含更新後的資料:
{"operation":0,"originalTransaction":2,"bucket":536870912,"rowId":0,"currentTransaction":2,"row":{"id":2,"name":"Tom","salary":21}}
4、Row_ID 資訊怎麼查?
5、事務表壓縮(Compact)
随着寫操作的積累,表中的 delta 和 delete 檔案會越來越多,事務表的讀取過程中需要合并所有檔案,數量一多勢必會影響效率,此外小檔案對 HDFS 這樣的檔案系統也不夠友好,是以Hive 引入了壓縮(Compaction)的概念,分為 Minor 和 Major 兩類。
● Minor
Minor Compaction 會将所有的 delta 檔案壓縮為一個檔案,delete 也壓縮為一個。壓縮後的結果檔案名中會包含寫事務 ID 範圍,同時省略掉語句 ID。
壓縮過程是在 Hive Metastore 中運作的,會根據一定門檻值自動觸發。我們也可以使用如下語句人工觸發:
ALTER TABLE dtstack COMPACT 'MINOR'。
● Major
Major Compaction 會将所有的 delta 檔案,delete 檔案壓縮到一個 base 檔案。壓縮後的結果檔案名中會包含所有寫事務 ID 的最大事務 ID。
壓縮過程是在 Hive Metastore 中運作的,會根據一定門檻值自動觸發。我們也可以使用如下語句人工觸發:
ALTER TABLE dtstack COMPACT 'MAJOR'。
6、檔案内容詳解
ALTER TABLE employee COMPACT 'minor';
語句執行前:
/user/hive/warehouse/employee/delta_0000001_0000001_0000
/user/hive/warehouse/employee/delta_0000002_0000002_0000 (insert 建立, mary的資料)
/user/hive/warehouse/employee/delete_delta_0000002_0000002_0001 (update)
/user/hive/warehouse/employee/delta_0000002_0000002_0001 (update)
語句執行後:
/user/hive/warehouse/employee/delete_delta_0000001_0000002
/user/hive/warehouse/employee/delta_0000001_0000002
7、讀 Hive 事務表
我們可以看到 ACID 事務表中會包含三類檔案,分别是 base、delta、以及 delete。檔案中的每一行資料都會以 row_id 作為辨別并排序。從 ACID 事務表中讀取資料就是對這些檔案進行合并,進而得到最新事務的結果。這一過程是在 OrcInputFormat 和 OrcRawRecordMerger 類中實作的,本質上是一個合并排序的算法。
以下列檔案為例,産生這些檔案的操作為:
- 插入三條記錄
- 進行一次 Major Compaction
- 然後更新兩條記錄。
1-0-0-1 是對 originalTransaction - bucketId - rowId - currentTra
8、合并算法
對所有資料行按照 (originalTransaction, bucketId, rowId) 正序排列,(currentTransaction) 倒序排列,即:
originalTransaction-bucketId-rowId-currentTransaction
(base_1)1-0-0-1
(delete_2)1-0-1-2# 被跳過(DELETE)
(base_1)1-0-1-1 # 被跳過(目前記錄的 row_id(1) 和上條資料一樣)
(delete_2)1-0-2-2 # 被跳過(DELETE)
(base_1)1-0-2-1 # 被跳過(目前記錄的 row_id(2) 和上條資料一樣)
(delta_2)2-0-0-2
(delta_2)2-0-1-2
擷取第一條記錄;
- 如果目前記錄的 row_id 和上條資料一樣,則跳過;
- 如果目前記錄的操作類型為 DELETE,也跳過;
通過以上兩條規則,對于 1-0-1-2 和 1-0-1-1,這條記錄會被跳過;
如果沒有跳過,記錄将被輸出給下遊;
重複以上過程。
合并過程是流式的,即 Hive 會将所有檔案打開,預讀第一條記錄,并将 row_id 資訊存入到 ReaderKey 類型中。
三、ChunJun讀寫Hive事務表實戰
了解完Hive事務表的基本原理後,我們來為大家分享如何在ChunJun中讀寫Hive事務表。
1、事務表資料準備
-- 建立事務表
create table dtstack(
id int,
name string,
age int )
stored as orc
TBLPROPERTIES('transactional'='true');
-- 插入 10 條測試資料
insert into dtstack (id, name, age)
values (1, "aa", 11), (2, "bb", 12), (3, "cc", 13), (4, "dd", 14), (5, "ee", 15),
(6, "ff", 16), (7, "gg", 17), (8, "hh", 18), (9, "ii", 19), (10, "jj", 20); 2、配置 ChunJun json 腳本
3、送出任務(讀寫事務表)
#啟動 Session
/root/wujuan/flink-1.12.7/bin/yarn-session.sh -t $ChunJun_HOME -d
#送出 Yarn Session 任務
#讀取事務表
/root/wujuan/ChunJun/bin/ChunJun-yarn-session.sh -job /root/wujuan/ChunJun/ChunJun-examples/json/hive3/hive3_transaction_stream.json -confProp {"yarn.application.id":"application_1650792512832_0134"}
#寫入事務表
/root/wujuan/ChunJun/bin/ChunJun-yarn-session.sh -job /root/wujuan/ChunJun/ChunJun-examples/json/hive3/stream_hive3_transaction.json -confProp {"yarn.application.id":"application_1650792512832_0134"}
根據上一行結果替換 yarn.application.id
三、ChunJun 讀寫Hive事務表源碼分析
壓縮器是在 Metastore 境内運作的一組背景程式,用于支援 ACID 系統。它由 Initiator、 Worker、 Cleaner、 AcidHouseKeeperService 和其他一些組成。
1、Compactor
● Delta File Compaction
在不斷的對表修改中,會建立越來越多的delta檔案,需要這些檔案需要被壓縮以保證性能。有兩種類型的壓縮,即(minor)小壓縮和(major)大壓縮:
minor 需要一組現有的delta檔案,并将它們重寫為每個桶的一個delta檔案
major 需要一個或多個delta檔案和桶的基礎檔案,并将它們改寫成每個桶的新基礎檔案。major 需要更久,但是效果更好
所有的壓縮工作都是在背景進行的,并不妨礙對資料的并發讀寫。在壓縮之後系統會等待,直到所有舊檔案的讀都結束,然後删除舊檔案。
●Initiator
這個子產品負責發現哪些表或分區要進行壓縮。這應該在元存儲中使用hive.compactor.initiator.on來啟用。 每個 Compact 任務處理一個分區(如果表是未分區的,則處理整個表)。如果某個分區的連續壓實失敗次數超過 hive.compactor.initiator.failed.compacts.threshold,這個分區的自動壓縮排程将停止。
● Worker
每個Worker處理一個壓縮任務。 一個壓縮是一個MapReduce作業,其名稱為以下形式。<hostname>-compactor-<db>.<table>.<partition>。 每個Worker将作業送出給叢集(如果定義了hive.compactor.job.queue),并等待作業完成。hive.compactor.worker.threads決定了每個Metastore中Worker的數量。 Hive倉庫中的Worker總數決定了并發壓縮的最大數量。
● Cleaner
這個程序是在壓縮後,在确定不再需要delta檔案後,将其删除。
● AcidHouseKeeperService
這個程序尋找那些在hive.txn.timeout時間内沒有心跳的事務并中止它們。系統假定發起交易的用戶端停止心跳後崩潰了,它鎖定的資源應該被釋放。
● SHOW COMPACTIONS
該指令顯示目前運作的壓實和最近的壓實曆史(可配置保留期)的資訊。這個曆史顯示從HIVE-12353開始可用。
● Compact 重點配置
2、如何 debug Hive
- debug hive client
hive --debug
- debug hive metastore
hive --service metastore --debug:port=8881,mainSuspend=y,childSuspend=n --hiveconf hive.root.logger=DEBUG,console
- debug hive mr 任務
3、讀寫過濾和CompactorMR排序的關鍵代碼
4、Minor&Major 合并源碼(CompactorMR Map 類)
四、ChunJun 檔案系統未來規劃
最後為大家介紹ChunJun 檔案系統未來規劃:
● 基于 FLIP-27 優化檔案系統
批流統一實作,簡單的線程模型,分片和讀資料分離。
● Hive 的分片優化
分片更精細化,粒度更細,充分發揮并發能力
● 完善 Exactly Once 語義
加強異常情況健壯性。
● HDFS 檔案系統的斷點續傳
根據分區,檔案個數,檔案行數等确定端點位置,狀态存儲在 checkpoint 裡面。
● 實時采集檔案
實時監控目錄下的多個追加檔案。