我們可以在linux系統下對下列代碼是如何進行編譯進行一個了解
main.cpp:
//引用sum.cpp檔案裡面定義的全局變量以及函數
extern int gdata;
int sum (int, int) ;
int data = 20;
int main ()
{
int a = gdata;
int b = data;
int ret =sum (a, b);
return o;
}
sum.cpp:
int gdata = 10;
int sum(int a, int b)
{
return a+b;
}
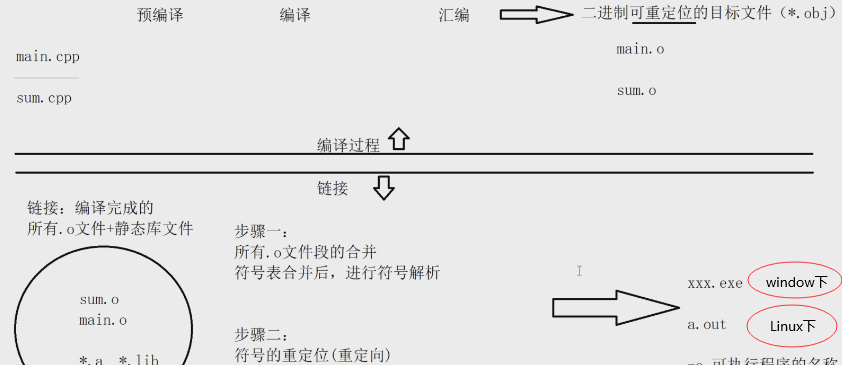
接下來我們将從以下幾個問題展開:
1.*.o檔案的格式組成是什麼樣的?
2.可執行檔案的組成格式是什麼樣子?
3.上圖中步驟一和步驟二是做的什麼事情?
4.符号表的輸出裡面的符号怎麼了解?
5.符号什麼時候配置設定虛拟位址?
預編譯(.c -> .i): 1.#開頭的指令的預處理(除了#pragma lib和#pragma link)2.将所有的“#define”删除,并且展開所有的宏定義。3.注釋的删除和替換4.頭檔案的引入。4.保留所有的#pragma編譯器指令,因為編譯器須要使用它們。
編譯(.i -> .s):詞法分析;文法分析;語義分析;以及優化後生産相應的彙編代碼檔案。
彙編(.s -> .o):彙編分為兩種x86和AT&T;将彙編代碼轉變成機器可以執行的指令
,生成二進制可重定位的目标檔案。
連結(.o -> a.out):編譯完成的所有.o檔案+靜态庫檔案進行連結,第一個步驟就是将所有.o檔案段的合并,符号表合并後進行符号解析;第二個步驟就是符号的重定位(連結的核心)。
.o檔案的格式組成:
elf檔案頭
.text
.data
.bss
.symbal
.section table
下面我們詳解一下.o檔案段的合并:
就是當我們main.o sum.o合并的時候各個段就要進行合并了.text <=> .text .bss <=> .bss .data<=> .data等等之間進行合并
符号解析:所有對符号的引用,都要找到該符号定義的地方。
符号解析成功以後!!!!就要給所有的符号配置設定虛拟位址。(即符号的重定向)
符号什麼時候配置設定虛拟位址:
連結的第一步符号解析完成後進行配置設定虛拟位址的。(編譯過程符号是不配置設定虛拟位址的)
我們二進制可重定位目标檔案和可執行檔案最大的差別是什麼呢?
可執行檔案有program headers段。由兩個load告訴系統運作這個程式的時候把哪些内容加載到記憶體中,加載的是代碼段和資料段,由下圖可以看出:

可執行檔案加載的大概過程如下圖: