locust中有兩個非常重要的類:Locust類和TaskSet類,深入了解這兩個類如何使用是非常有必要的。
一、Locust類詳細說明
Locust類中的屬性有:
client屬性:
task_set: 指向一個TaskSet類,TaskSet類定義了使用者的任務資訊,該屬性為必填;
max_wait/min_wait: 每個使用者執行兩個任務間隔時間的上下限(毫秒),具體數值在上下限中随機取值,若不指定則預設間隔時間固定為1秒;
host:被測系統的host,當在終端中啟動locust時沒有指定--host參數時才會用到;
weight:同時運作多個Locust類時會用到,用于控制不同類型任務的執行權重。
使用代碼說明:
在運作結果中發現job2是job1事件執行頻率的2倍;
如果希望讓某個 locust 類經常被執行,可以在這些類上設定一個 weight 屬性。
二、TaskSet類詳細說明
TaskSet類:實作了虛拟使用者所執行任務的排程算法,包括規劃任務執行順序(schedule_task)、挑選下一個任務(execute_next_task)、執行任務(execute_task)、休眠等待(wait)、中斷控制(interrupt)等等。
在此基礎上,我們就可以在TaskSet子類中采用非常簡潔的方式來描述虛拟使用者的業務測試場景,對虛拟使用者的所有行為(任務)進行組織和描述,并可以對不同任務的權重進行配置。
在TaskSet子類中定義任務資訊時,可以采取兩種方式,@task裝飾器和tasks屬性。
采用@task裝飾器定義任務:
代碼示範:
from locust import TaskSet, task
class UserBehavior(TaskSet):
@task(1)
def test_job1(self):
self.client.get('/job1')
@task(2)
def test_job2(self):
self.client.get('/job2')
@task(1)中的數字表示任務的執行頻率,數值越大表示執行的頻率越高
采用tasks屬性定義任務:
代碼示範:
from locust import TaskSet
def test_job1(obj):
obj.client.get('/job1')
def test_job2(obj):
obj.client.get('/job2')
class UserBehavior(TaskSet):
tasks = {test_job1:1, test_job2:2}
說明:
tasks = {test_job1:1, test_job2:2}中,test_job1:1,test_job2:2表示事件執行的頻率,即test_job2的執行頻率是test_job1的兩倍
2.1 TaskSet類詳細說明--on_start函數
on_start函數是在Taskset子類中使用比較頻繁的函數。在正式執行測試前執行一次,主要用于完成一些初始化的工作。
例如,當測試某個搜尋功能,而該搜尋功能又要求必須為登入态的時候,就可以先在on_start中進行登入操作,HttpLocust使用到了requests.Session,是以後續所有任務執行過程中就都具有登入态了
2.2 TaskSet類詳細說明--控制任務的執行順序
在TaskSequence類中,使用裝飾器@seq_task()可以用來控制任務的執行順序;裡面的數值越小執行越靠前;
代碼舉例:
2.3 TaskSet類詳細說明--休眠等待(wait)
在Taskset類中,内置WAIT_TIME功能,它用于确定模拟使用者在執行任務之間将等待多長時間。Locust提供了一些内置的函數,傳回一些常用的wait_time方法。
1、between(min,max)函數:用得比較多的函數
wait_time = between(3.0, 10.5):任務之間等待的時間是3到10.5秒之間的任意時間
2、constant(number)函數:
wait_time=constant(3):任務之間等待的時候是3秒鐘,且等待的時候不能超過任務運作的總時間,也就是在執行py檔案時設定的時間
3、constant_pacing(number)函數:
wait_time=constant_pacing(3):是以任務每隔3秒執行,但是當到達運作的總時間時,任務運作結束;
2.4 TaskSet類詳細說明--TaskSets 嵌套
現實中有很多任務其實也是有嵌套結構的,比如使用者打開一個網頁首頁後,使用者可能會不喜歡這個網頁直接離開,或者喜歡就留下來,留下來的話,可以選擇看書、聽音樂、或者離開;
代碼舉例:
2.5 TaskSet類詳細說明--中斷控制(interrupt)
在有Taskset嵌套的情況下,執行子任務時, 通過 self.interrupt() 來終止子任務的執行, 來回到父任務類中執行, 否則子任務會一直執行;
在上一頁的案例中,在stay這個類中,對interrupt()方法的調用是非常重要的,這可以讓一個使用者跳出stay這個類有機會執行leave這個任務,否則他一旦進入stay任務就會一直在看書或者聽音樂而難以自拔。
三、locust實作參數化
在進行接口多使用者并發測試時,資料的重複使用可能會造成腳本的失敗,那麼需要對使用者資料進行參數化來使腳本運作成功。
情景一:
在此我們舉出百度搜尋的例子,假設每個人搜尋的内容是不相同的;那麼我們可以假設把資料放到隊列中,然後從隊列中依次把資料取出來;
可以利用python中Queue隊列來進行處理;
Queue的種類:
Queue.Queue(maxsize=0):先進先出隊列
Queue.LifoQueue(maxsize=0):後進先出隊列
Queue.PriorityQueue(maxsize=0):構造一個優先隊列
參數maxsize是個整數,指明了隊列中能存放的資料個數的上限。一旦達到上限,插入會導緻阻塞,直到隊列中的資料被消費掉。如果maxsize小于或者等于0,隊列大小沒有限制
Queue的基本方法:
Queue.Queue(maxsize=0) 如果maxsize小于1就表示隊列長度無限
Queue.LifoQueue(maxsize=0) 如果maxsize小于1就表示隊列長度無限
Queue.qsize() 傳回隊列的大小
Queue.empty() 如果隊列為空,傳回True,反之False
Queue.full() 如果隊列滿了,傳回True,反之False
Queue.get([block[, timeout]]) 讀隊列,timeout等待時間
Queue.put(item, [block[, timeout]]) 寫隊列,timeout等待時間
Queue.queue.clear() 清空隊列
舉例說明:
情景2:
個别情況下測試資料可重複使用,是以我們可以把參數化資料定義為一個清單,在清單中取出資料;
舉例說明:
四、loust實作關聯
在某些請求中,需要攜帶之前response中提取的參數,常見場景就是session_id。Python中可用通過re正則比對,對于傳回的html頁面,可用采用lxml庫來定位擷取需要的參數;
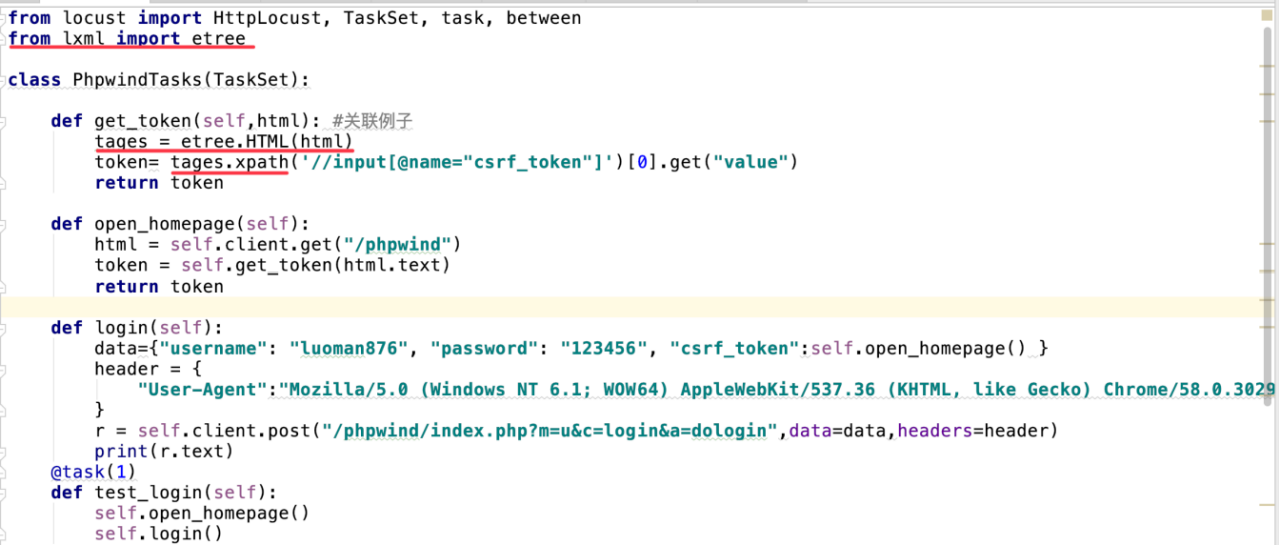
我們以Phpwind登陸的來進行舉例,在登陸的接口中需要把token參數傳給伺服器,token的值由頁的接口傳回;
方法一:使用正規表達式:
方法二:采用lxml庫來定位擷取需要的參數
技術點:
1、導子產品:lxml子產品
2、etree.HTML() 從傳回html頁面擷取html檔案的dom結構
3、xpath() 擷取token的xpath路徑
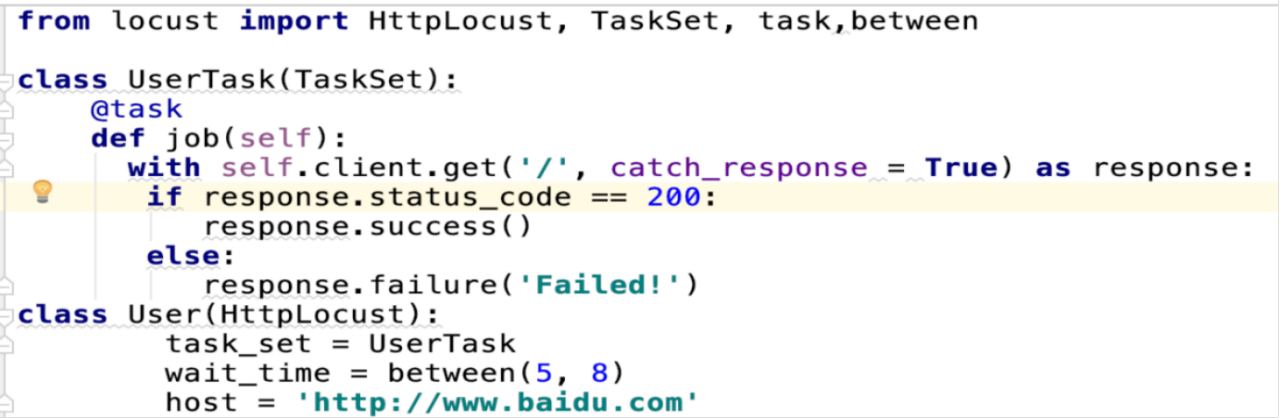
五、loust實作斷言
在進行性能測試時,斷言是必須的。比如你在請求一個頁面時,就可以通過狀态來判斷傳回的 HTTP 狀态碼是不是 200。
在locust中通過with self.client.get("url位址",catch_response=True) as response的形式;
通過 client.get() 方法發送請求,将整個請求的給 response, 通過 response.status_code 得請求響應的 HTTP 狀态碼。如果不為 200 則通過
response.failure('Failed!') 列印失敗!如果斷言失敗後會加到統計錯誤表中