資料加載器,結合了資料集和取樣器,并且可以提供多個線程處理資料集。在訓練模型時使用到此函數,用來把訓練資料分成多個小組,此函數每次抛出一組資料。直至把所有的資料都抛出。就是做一個資料的初始化。
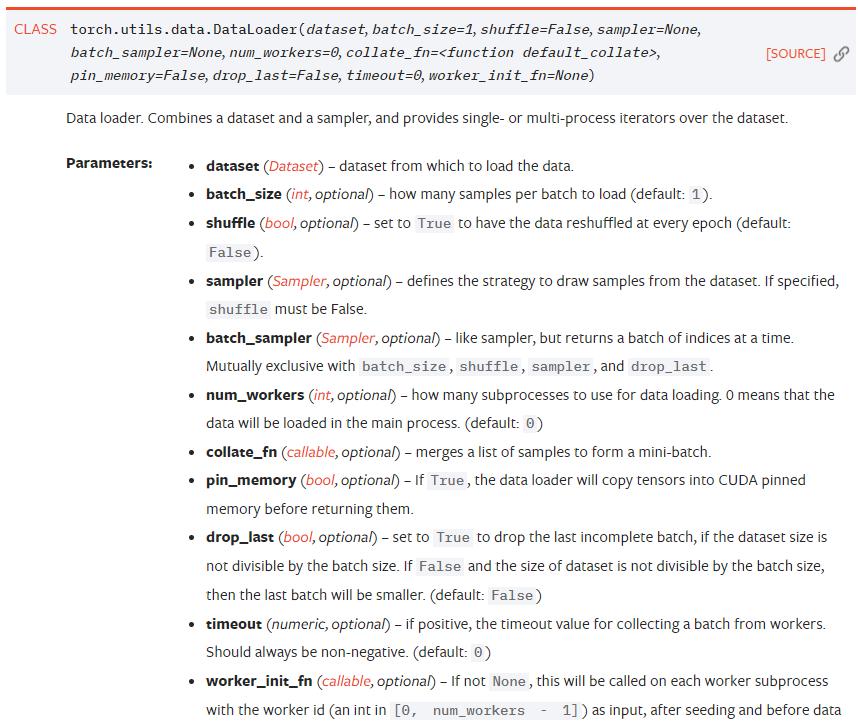
生成疊代資料非常友善,請看如下示例:
"""
批訓練,把資料變成一小批一小批資料進行訓練。
DataLoader就是用來包裝所使用的資料,每次抛出一批資料
"""
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
# 把資料放在資料庫中
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
# 從資料庫中每次抽出batch size個樣本
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
)
def show_batch():
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
# training
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
if __name__ == '__main__':
show_batch() 複制
結果:

我們來看一下變量類型: