很久之前就看完vue1,但是太懶就一直沒寫部落格,這次看Vue2打算抽下懶筋先把自己看過了記錄下來,否則等全部看完,估計又沒下文了
看源碼總需要抱着一個目的,否則就很難堅持下去,我并沒做過vue的項目,我幾乎很少會依賴大型的架構,一個是跟平台有關系,另一方面因為我覺得是對自己能力的束縛,而我更渴望的就是通過閱讀别人的源碼,吸收别人的思路,取之精華去之糟粕,進而改造自己的項目。當然,這是在項目條件允許的情況下。目前我有個項目持續開發的項目,基本融入了自己這麼多年看到架構思路,這才是我堅持看源碼的原因。可以參考下吧 xut.js
vue2源碼晦澀的程度比vue1高多了,翻開源碼估計90%都會直接關閉吧,主要還是引入Flow的文法問題,可以用babel-plugin-transform-flow-strip-types去轉化下即可。看源碼還是有一定技巧的,這個因每個人而已。大神嘛,直接掃描下代碼,看看注釋,看看流程,閉目YY一下,就知道大體是怎麼玩的了。我表示做不到,普通人呢,我還是主張有時間的話自己能動手從零開始實作一遍,這樣你才能真正去了解作者的設計的意圖。同樣的,我也正在從零在實作vue,不過完全一樣還是不可能滴,隻能是大體上了解作者的設計,但是足夠了 vue-analysis
vue2的源碼的前戲太多了,很難進入高潮部分,從頭開始入戲需要有很強的邏輯能力、空間跳躍能力,是以這裡不打算從頭開始疏通,而是采用從後往前推導,先看看要實作其功能,最後需要哪些實作步驟與機制
先摘一段源碼,作為簡單的分析
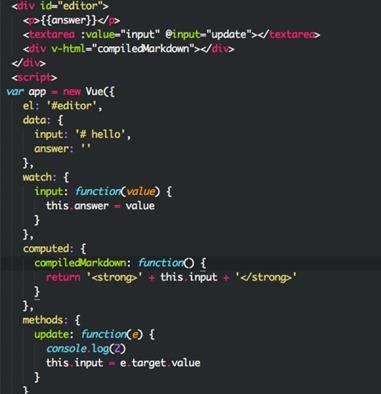
預期的效果:
監聽input的輸入,input在輸入的時候,會觸發 watch與computed函數,并且會更新原始的input的數值。是以直接跟input相關的處理就有3處,但實際上會有連帶性的觸發,觸發watch的input函數的時候,還會觸發this.answer對應的依賴處理
看看内部是如何處理的:
Vue在初始化data的時候,會通過Object.defineProperty重新定義input的set與get通路接口,同時會建立一個記錄并且保持其資料對應的依賴watcher對象的Dep對象,這個Dep對象是通過閉包的方式儲存在每個獨立的data中,而Dep就是用于收集目前data所依賴的Watcher對象
簡單來說
- 在data中定義了input,那麼意味着需要對這個變量進行defineProperty的處理,并建立Dep對象
- watch中的input函數會變成一個Watcher對象,因為它與input有關系,是以需要在data的input的Dep中儲存一份引用
- computed中的compiledMarkdown函數會變成一個Watcher對象,,因為它與input有關系,是以需要在data的input的Dep中儲存一份引用
input資料的監控内部建立的Dep的結構就是如下:

根據目前這個例子的代碼,watch與computed明明隻有2個對應的Watcher對象,為什麼subs會有3個呢?多增加的一個是幹什麼的?這個多出的Watcher就是vue2中的虛拟dom的處理,後面會提到
這裡最終可以簡單的梳理下更新的流程:當input資料發生變化的時候,隻需要調用響應依賴的Watcher對象,Watcher對象就會負責各自的更新處理。這裡面向對象的設計優勢就展現出來了,将行為分布在各個對象中,并讓這些對象負責自己的行為,是以每個不同Watcher對象更新各自的特點,處理各自的邏輯
更新
更新邏輯:
vue1的 dom更新方式采用隊列+直接更新的處理,這種簡單粗暴。vue2在vue1的設計上,繼續保留了隊列的處理方式,同時結合了時下最流行的 virtual dom
記得在Vue1中,每個Watcher對象都會儲存各自的dom節點的處理方式,通過對Watcher的的處理達到直接更新DOM的目的。Vue2因為引入的Virtual Dom的機制,是以Watcher的工作就需要變化了,大多數的Watcher不再直接負責DOM的更新操作,而隻是更新資料。這裡用了大多數,因為還有一個Watcher是跟Virtual Dom相關的。是以這就是在上文提到的Dep中會多一個Watcher的原因了
Virtual DOM
虛拟DOM的文章現在已經很多了,但是如何緊密結合vue中,到實際的運用是我們分析的重點,這裡隻是粗略下,我還要抽時間把算法看完先
原理:
簡單的說,直接通過JS操作浏覽器API去繪制DOM節點是很慢的,大量的頁面進行中,開發者不經意就會調用更多多餘或者重複的操作,這種是有性能開銷的。那麼有什麼辦法減少這種是誤操作呢?就是通過一種方式能算出來最小的更新量,進而提高效率。既然要計算出對小的更新量,那麼就會有對比,需要通過對新舊兩個節點的對比進而計算出。DOM的操作很慢,但是JS确很快的,DOM 樹上的結構、屬性資訊我們都可以很容易地用 JavaScript 對象表示出來,既然我們可以用JS對象表示DOM結構,那麼當資料狀态發生變化而需要改變DOM結構時,我們先通過JS對象表示的虛拟DOM計算出實際DOM需要做的最小變動,反過來,就可以根據這個用 JavaScript 對象表示的樹結構來建構一棵真正的DOM樹,操作實際DOM更新了, 進而避免了粗放式的DOM操作帶來的性能問題。
根據上面的原理,Virtual DOM在實作上首先就必須先建立可以對比的JS對象,這個叫做vnode,也就是虛拟DOM了,這個對象是真實DOM結構的一個映射,通過對比更新前後vnode的變化差異diff,記錄下來的不同就是我們需要對頁面真正的 DOM 操作。
Virtual DOM算法,簡單總結下包括幾個步驟:
- 用JS對象描述出DOM樹的結構,然後在初始化建構中,用這個描述樹去建構真正的DOM,并實際展現到頁面中
- 當有資料狀态變更時,重新建構一個新的JS的DOM樹,通過新舊對比DOM數的變化diff,并記錄兩棵樹差異
- 把步驟2中對應的差異通過步驟1重新建構真正的DOM,并重新渲染到頁面中,這樣整個虛拟DOM的操作就完成了,視圖也就更新了
看到這裡可以簡單總結下,Vue中Watcher與Virtual DOM的關系:
- Watcher 是來決定你要不要更新這個dom
- 虛拟DOM是用來找出怎麼以最小的代價來更新
Vue2中對應的邏輯
這裡不會涉及算法,并非這章的重點,主要看下整個更新過程中,虛拟DOM邏輯是怎麼配合工作的。
繼續input的資料流向,之前講到了input中的Dep是儲存了3個Watcher對象的引用,其中會有一個Watcher是跟整個頁面的渲染有關系的,這個就是用來封裝vnode的處理。
當周遊Dep這個儲存Watcher數組的時候,會把Watcher加入到一個異步的隊列中進行處理
代碼進行了簡化
function queueWatcher(watcher) {
var id = watcher.id;
if (has[id] == null) {
has[id] = true;
queue.push(watcher);
nextTick(flushSchedulerQueue);
}
}
function flushSchedulerQueue() {
queue.sort(function(a, b) { return a.id - b.id; });
for (index = 0; index < queue.length; index++) {
watcher = queue[index];
id = watcher.id;
has[id] = null;
watcher.run();
}
} 這裡很關鍵的一個點就是針對queue進行了排序,原因就是其中有一個Wacher是儲存了vnode了,因為最後一步才是vnode的對比更新。必須讓前面的Watcher更新資料完畢後,最後vnode才能做真正的對比,不過computed的Wacher不會加入到這個隊列中,它會再編譯樹中動态的執行。
啪啦啪啦,目前面的Watcher執行完畢後,調到最後一個Watcher,可以看到對應的代碼
vm._update(vm._render(), hydrating);
- 通過vm._render方法建構vnode
- 通過vm._update 對比vnode,并渲染到頁面中
vm._render
初始化的時,會通過建構出來的JS描述樹,生成初始vnode,去繪制初始頁面。每次DOM變化的時候,我們還是需要重新建構這個描述樹,通過這個描述樹去建構新的vnode
這個描述樹生成相當複雜,vue2内部專門會有一個AST是幹這個事的
對應的結構是這樣的,這個可以其實就是真實DOM樹的一個結構映射了:
但是這個結構是可執行的,可編譯的,通過with的方式改變this的上下文,動态執行每個可執行的代碼部分,并把每個節點部分都編譯成vnode,組成一個有對應層次結構的vnode對象
舉例來說
div是最外層的vnode
div有子節點=> p,生成對應vnode
p有子節點=>文本節點answer,生成對應vnode
每個vnode會儲存每個對應節點一些計算資訊,比如tag、data、 children、text這些都是用于後面的比對計算的
vm._update
通過render拿到了vnode,然後通過update對比vnode繪制到頁面
update這個方法内部有段代碼
vm.$el = vm.__patch__(prevVnode, vnode);
從這個字面意思就明顯知道,更新更新檔,用于對比新舊2個vnode,
vue2有個專門的patch檔案用于vnode的對比政策,patch内部會細分很多政策出來
- 如果vnode不存在但是oldVnode存在,就意味着要銷毀
- 如果oldVnode不存在但是vnode存在,說明意圖是要建立新節點
- 當vnode和oldVnode都存在時,就需要更新了
每一種政策都對應的不同的處理方式,更新才意味着需要對比新舊的vnode,首先是需要判斷下兩個節點是否值得比較,在這個例子裡面隻改變了屬性input與answer的值,是以,這裡是屬于同節點内的屬性變更的,是以檢測vnode的變化也是相對最簡單,遞歸子節點,通過patchVnode檢測每個節點屬性的變化
if(sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue);
oldStartVnode = oldCh[++oldStartIdx];
newStartVnode = newCh[++newStartIdx];
} 當對比到差異時,例如文本answer被改變,那麼對應的vnode在對比的時候,就能找到差異,然後重新設定值,此刻的node就是真實的DOM引用的,如果改變了textContent就意味着頁面上呈現的資料就直接被改變了
if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text);
}
function setTextContent (node, text) {
node.textContent = text;
} 通過這個簡單的例子是不能夠評價這個Virtual DOM的優劣的,因為改動确實很小,而且都是局部的變化,都是直接更新到頁面中了,真正的代碼部分是做了非常多的優化手段的
總結
因為不是具體的算法分析,是以不會一段代碼一段代碼的去句斟字酌了,整段分析都是基于這個簡單的代碼,是以在實作上很多地方是有偏差的,不能以偏概全,但是通過這個文章,想必你對vue2的内部邏輯應該是有一個初步的認識。後續就會有時間就會開始比較細緻的分解咯~~~
本文轉自艾倫 Aaron部落格園部落格,原文連結:http://www.cnblogs.com/aaronjs/p/7274965.html,如需轉載請自行聯系原作者