閱讀本文需要2分鐘
最近本狗想放松放松, 想了想還是看看幾部電影最為可貴, 于是找了大家最為熟悉的網站《電影天堂》去看個究竟。為了更好的去"挑選"電影,本狗就爬取了大幾十頁的資料。廢話不多說:開工啦
1
原理:
建構目标URL:
def page_urls():
baseurl = 'http://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html'
for i in range(1, 30):
url = baseurl.format(i)
parse_url(url) 複制
隻需要改變{}裡面的内容就可以實作翻頁
爬取電影詳情URL:
def parse_url(url):
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
tables = html.xpath('//table[@class="tbspan"]//a/@href')
for table_url in tables:
page_urls = baseurl + table_url 複制
2
需要的子產品:
import time
import random
import requests
from lxml import etree
import csv 複制
主程式:(有點長,截取部分)
def spider(page_urls):
data = {}
response = requests.get(page_urls, headers=headers)
html = etree.HTML(response.content.decode('gbk'))
title = html.xpath('//div[@class="title_all"]//font[@color="#07519a"]/text()')[0]
data['名字'] = title
try:
images = html.xpath('//div[@id="Zoom"]//img/@src')[1]
except:
print("套路深!")
try:
posters = html.xpath('//div[@id="Zoom"]//img/@src')[0]
except:
print("套路深!!")
data['海報'] = posters
# time.sleep(random.randint(1, 2))
zoom_ = html.xpath('//div[@id="Zoom"]')[0]
infos = zoom_.xpath('.//text()')
for info in infos:
if info.startswith('◎年 代'):
info1 = info.replace('◎年 代', '').strip()
data['年代'] = info1
elif info.startswith('◎産 地'):
info2 = info.replace('◎産 地', '').strip()
data['産地'] = info2
elif info.startswith('◎類 别'):
info3 = info.replace('◎類 别', '').strip()
data['類别'] = info3
elif info.startswith('◎語 言'):
info4 = info.replace('◎語 言', '').strip()
data['語言'] = info4
elif info.startswith('◎上映日期'):
info5 = info.replace('◎上映日期', '').strip()
data['上映日期'] = info5
elif info.startswith('◎豆瓣評分'):
info6 = info.replace('◎豆瓣評分', '').strip()
info6 = ''.join(info6.split('/')[:1])
data['豆瓣評分'] = info6
elif info.startswith('◎片 長'):
info7 = info.replace('◎片 長', '').strip()
data['片長'] = info7 複制
3
效果圖:
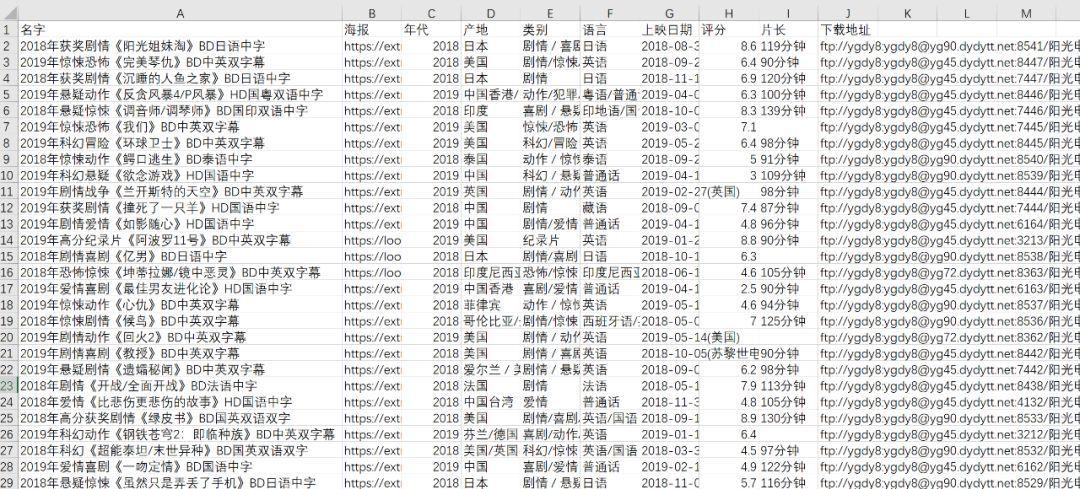
這樣檢視電影很友善呀!!!最後本跟根據【評分】【類别】選擇了些電影《頭号玩家》《江湖兒女》《調音師》,感覺還不錯!!! 主要原因還是沒錢開會員